Clustering (Agrupamiento)¶
Modelos de Machine Learning No-Supervisados¶
📌 Dr. Cristian Candia¶
🎓 Universidad del Desarrollo (UDD), Chile¶
- 🏢 Director, Computational Research in Social Sciences Lab
- 🔬 Faculty, Data Science Institute, School of Engineering
🎓 Northwestern University, United States¶
- 🔬 External Faculty, Northwestern Institute on Complex Systems (NICO), Kellogg School of Management
🚀 Founder¶
- 🦫 Capybara
Definición:¶
El clustering (agrupamiento) es una técnica que busca descubrir subgrupos dentro de un conjunto de datos de manera automática, sin necesidad de etiquetas previas. Es especialmente útil para la segmentación de datos en patrones homogéneos.
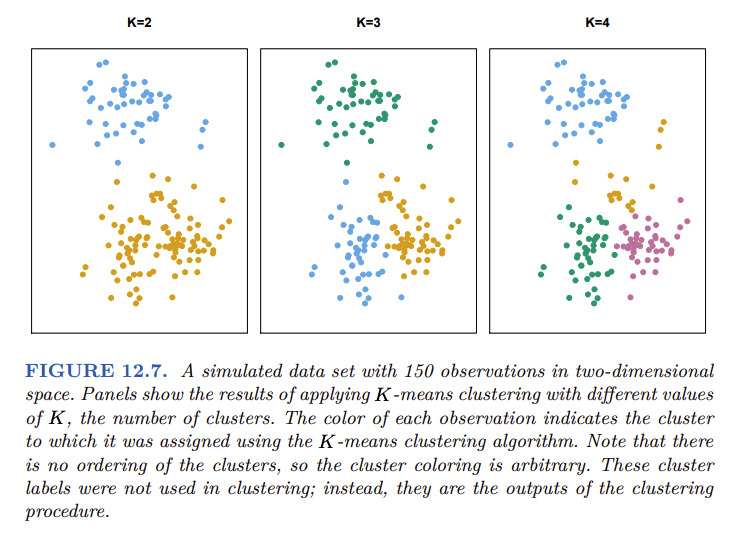
Existen diversos algoritmos de clustering, pero nos enfocaremos en:
K-Means¶
Uno de los métodos más utilizados en aprendizaje no supervisado es K-Means, que busca particionar $ n $ observaciones en $ K $ grupos, minimizando la varianza dentro de cada grupo.
Definición formal¶
Dado un conjunto de datos $ X = \{x_1, x_2, ..., x_n\} $ con $ x_i \in \mathbb{R}^d $, K-Means busca encontrar $ K $ centroides $ C = \{c_1, c_2, ..., c_K\} $ que minimicen la siguiente función de costo:
$J = \sum_{i=1}^{n} \sum_{k=1}^{K} \mathbf{1}(z_i = k) ||x_i - c_k||^2$
donde:
- $ z_i $ es la asignación de la observación $ x_i $ al clúster $ k $.
- $ ||x_i - c_k||^2 $ es la distancia euclidiana entre $ x_i $ y su centroide correspondiente $ c_k $.
- La función indicadora $ \mathbf{1}(z_i = k) $ vale 1 si $ x_i $ pertenece al clúster $ k $ y 0 en caso contrario.
Conceptos clave en K-Means:¶
- Centroide: Punto medio de cada cluster, que representa la posición promedio de sus observaciones.
- Varianza intra-cluster: Medida de dispersión de los datos dentro de un cluster; un menor valor indica que los puntos están más cerca del centroide.
- Asignación de clusters: Cada punto es asignado al cluster cuyo centroide esté más cercano en términos de distancia euclidiana.
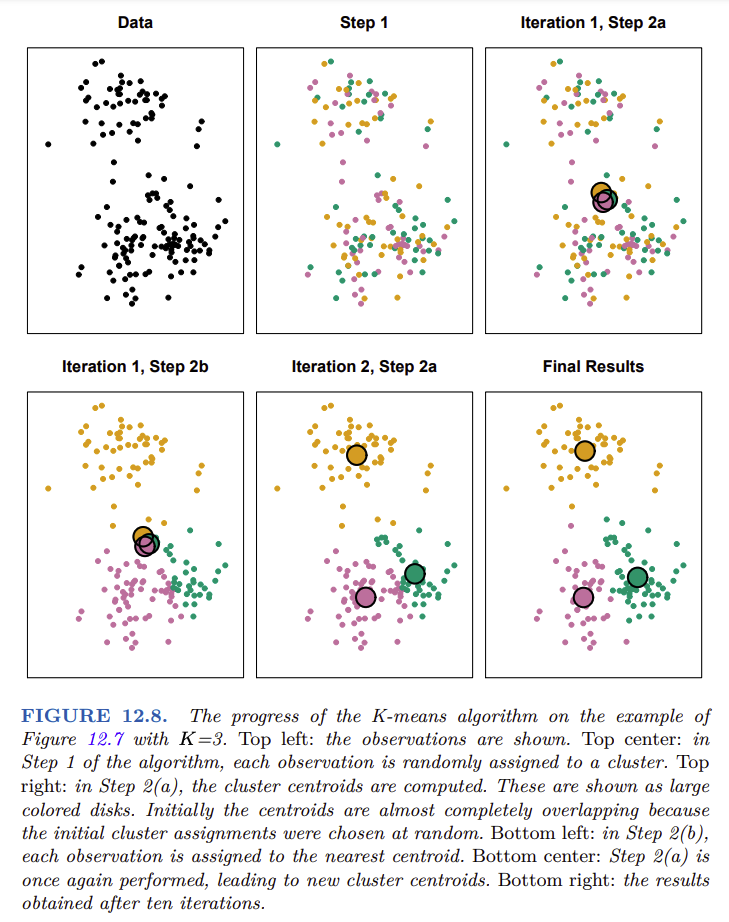
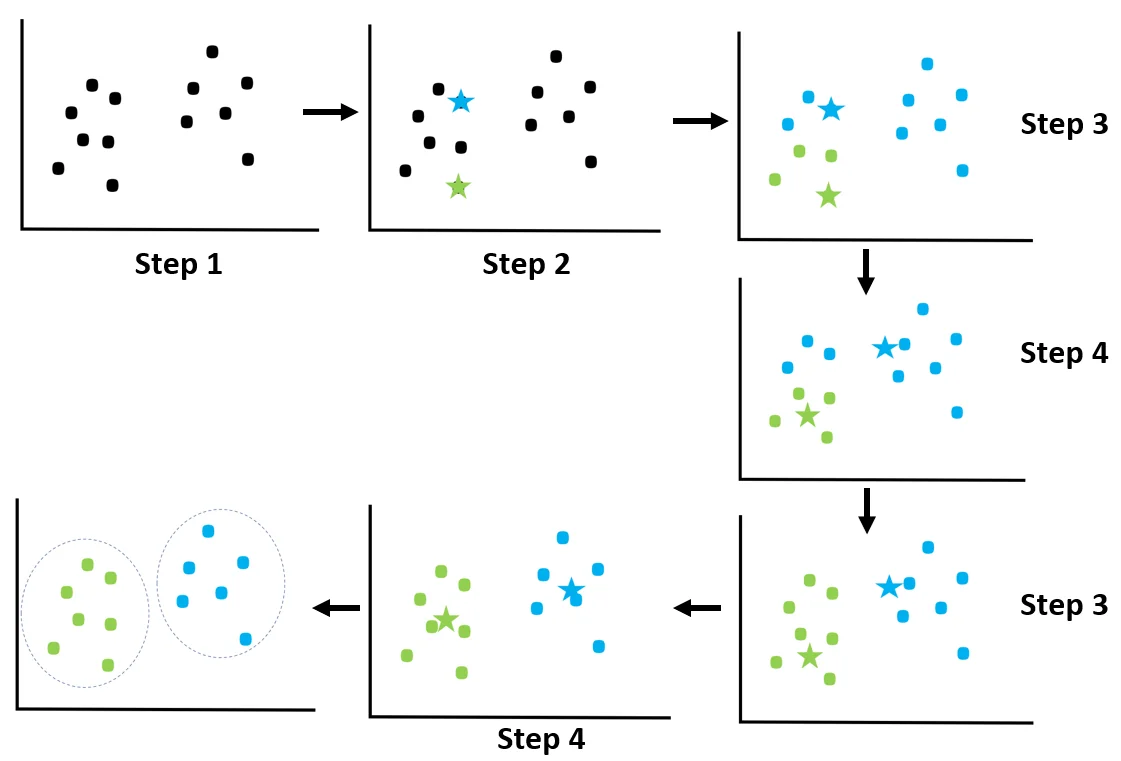
Algoritmo K-Means¶
- 1 Inicialización: Seleccionar aleatoriamente $ K $ centroides $ \{c_1, ..., c_K\} $.
2a Asignación de clústeres: Para cada punto de datos $ x_i $, asignarlo al clúster $ k $ cuyo centroide $ c_k $ esté más cercano:
$z_i = \arg \min_{k\in \{1,...,K\}} ||x_i - c_k||^2$
2b Actualización de centroides: Recalcular los centroides como el promedio de los puntos asignados a cada clúster:
$c_k = \frac{1}{|S_k|} \sum_{x_i \in S_k} x_i$
donde $ S_k $ es el conjunto de puntos asignados al clúster $ k $.
- 3 Convergencia: Repetir los pasos 2 y 3 hasta que los centroides dejen de cambiar significativamente.

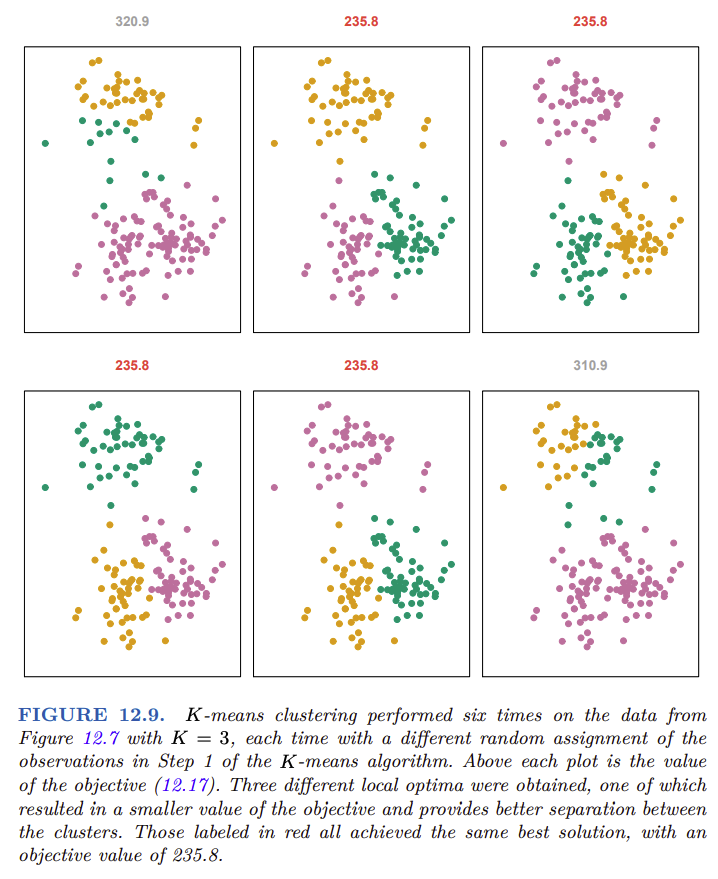
Importancia de Ejecutar K-Means Múltiples Veces¶
El algoritmo K-Means encuentra un mínimo local, no un óptimo global. Esto significa que los resultados obtenidos dependen fuertemente de la inicialización aleatoria de los centroides en el Paso 1 del algoritmo.
Para mitigar este problema, es crucial ejecutar K-Means múltiples veces con diferentes configuraciones iniciales y seleccionar la mejor solución, es decir, aquella para la cual la función objetivo es mínima:
$J = \sum_{i=1}^{n} \sum_{k=1}^{K} \mathbf{1}(z_i = k) ||x_i - c_k||^2$
donde:
- $ x_i $ es la observación $ i $-ésima.
- $ c_k $ es el centroide del clúster $ k $.
- $ \mathbf{1}(z_i = k) $ es una función indicadora que vale 1 si $ x_i $ pertenece al clúster $ k $ y 0 en caso contrario.
En la Figura 12.9, se observan seis ejecuciones diferentes de K-Means sobre el mismo conjunto de datos de la Figura 12.7. Cada una de estas ejecuciones produce un agrupamiento distinto debido a las diferencias en la inicialización de los centroides. En este caso, el mejor clustering es el que tiene un valor objetivo de 235.8.
¿Cómo mitigar el problema de los mínimos locales?¶
Para reducir la sensibilidad de K-Means a la inicialización, existen varios enfoques:
Ejecutar K-Means múltiples veces
- Se recomienda repetir el algoritmo con diferentes inicializaciones aleatorias y seleccionar el mejor resultado.
- Implementado en librerías como Scikit-Learn con el parámetro
n_init.
K-Means++ (Mejor Inicialización de Centroides)
- Mejora la selección inicial de centroides, reduciendo la probabilidad de converger a un mínimo local.
- Los centroides iniciales se eligen de forma probabilística, favoreciendo aquellos que maximizan la distancia entre sí.
Usar Métodos de Clustering más Robustas
- Algoritmos como DBSCAN o Clustering Jerárquico pueden ser mejores en ciertos casos, especialmente cuando la estructura de los datos no es esférica.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import datasets
# Cargar el dataset Iris
iris = datasets.load_iris()
X = iris.data[:, :2] # Tomamos solo las primeras dos características para visualización
# Número de clusters
n_clusters = 3
# Número de inicializaciones
n_init = 20
# Almacenar las inercias de cada inicialización y los modelos
inercias = []
models = []
# Ejecutar KMeans n_init veces y almacenar las inercias y los modelos
for i in range(n_init):
kmeans = KMeans(n_clusters=n_clusters, random_state=i, n_init=1)
kmeans.fit(X)
inercias.append(kmeans.inertia_)
models.append(kmeans)
# Encontrar el índice del mejor modelo (el de menor inercia)
best_index = np.argmin(inercias)
best_model = models[best_index]
# Visualizar las inercias
plt.figure(figsize=(10, 6))
plt.plot(range(1, n_init + 1), inercias, marker='o', linestyle='-')
plt.xlabel('Iteración de n_init')
plt.ylabel('Inercia')
plt.title('Inercia en diferentes iteraciones de n_init')
plt.grid(True)
plt.show()
# Mostrar las inercias
for i, inercia in enumerate(inercias, start=1):
print(f'Iteración {i}: Inercia = {inercia}')
print(f'\nMejor iteración: {best_index + 1} con inercia = {inercias[best_index]}')
# Visualizar los clusters del mejor modelo
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=best_model.labels_, cmap='viridis', edgecolor='k')
plt.scatter(best_model.cluster_centers_[:, 0], best_model.cluster_centers_[:, 1], s=300, c='red', marker='X')
plt.xlabel('Longitud del Sépalo')
plt.ylabel('Ancho del Sépalo')
plt.title('Mejor K-Means con n_init=20 en el dataset Iris')
plt.show()


Ejecutar K-Means en Otros Datasets¶
import numpy as np
import matplotlib.pyplot as plt
# Fijar semilla para reproducibilidad
np.random.seed(42)
# Generar dos clusters gausianos
X1 = np.random.normal(loc=[2, 2], scale=0.5, size=(50, 2)) # Cluster 1
X2 = np.random.normal(loc=[6, 6], scale=0.5, size=(50, 2)) # Cluster 2
# Unir en un solo dataset
X = np.vstack((X1, X2))
# Crear etiquetas de ground truth
y = np.array([0]*50 + [1]*50)
# Visualización
plt.scatter(X[y == 0, 0], X[y == 0, 1], s=50, alpha=0.7, label='Cluster 1')
plt.scatter(X[y == 1, 0], X[y == 1, 1], s=50, alpha=0.7, label='Cluster 2')
plt.title("Dos Clusters Gaussianos")
plt.legend()
plt.show()

from sklearn import datasets
import pandas as pd
import matplotlib.pyplot as plt
# Cargar datos de Iris
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Convertir a DataFrame para mejor interpretación
df = pd.DataFrame(X, columns=iris.feature_names)
# Visualización de las dos primeras características con etiquetas de ground truth
plt.scatter(df.iloc[y == 0, 0], df.iloc[y == 0, 1], s=50, alpha=0.7, label=iris.target_names[0])
plt.scatter(df.iloc[y == 1, 0], df.iloc[y == 1, 1], s=50, alpha=0.7, label=iris.target_names[1])
plt.scatter(df.iloc[y == 2, 0], df.iloc[y == 2, 1], s=50, alpha=0.7, label=iris.target_names[2])
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
plt.title("Iris Dataset - Visualización con etiquetas de ground truth")
plt.legend()
plt.show()

from sklearn.datasets import make_circles
import matplotlib.pyplot as plt
# Generar dataset de anillos concéntricos
X, y = make_circles(n_samples=300, factor=0.5, noise=0.05)
# Visualización con etiquetas de ground truth
plt.scatter(X[y == 0, 0], X[y == 0, 1], s=50, alpha=0.7, label='Cluster 1')
plt.scatter(X[y == 1, 0], X[y == 1, 1], s=50, alpha=0.7, label='Cluster 2')
plt.title("Anillos Concéntricos - make_circles")
plt.legend()
plt.show()

from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# Generar dataset de lunas
X, y = make_moons(n_samples=300, noise=0.05)
# Visualización con etiquetas de ground truth
plt.scatter(X[y == 0, 0], X[y == 0, 1], s=50, alpha=0.7, label='Cluster 1')
plt.scatter(X[y == 1, 0], X[y == 1, 1], s=50, alpha=0.7, label='Cluster 2')
plt.title("Lunas Entrelazadas - make_moons")
plt.legend()
plt.show()

import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Cargar el dataset "penguins" desde seaborn
df = sns.load_dataset('penguins')
# Mostrar las primeras filas del dataset
print(df.head())
# Eliminar filas con valores nulos
df = df.dropna()
# Visualización de los clusters utilizando las especies como ground truth
species = df['species'].unique()
colors = ['r', 'g', 'b']
for species, color in zip(species, colors):
subset = df[df['species'] == species]
plt.scatter(subset['bill_length_mm'], subset['bill_depth_mm'], s=50, alpha=0.7, label=species, c=color)
plt.xlabel("Longitud del Pico (mm)")
plt.ylabel("Profundidad del Pico (mm)")
plt.title("Segmentación de Pingüinos por Especie")
plt.legend()
plt.show()

import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
# Cargar el dataset de vinos
wine = load_wine()
X_wine = wine.data[:, :2] # Tomamos solo las primeras dos características para visualización
y_wine = wine.target # Etiquetas de las clases
# Crear un DataFrame con las características y las etiquetas
df = pd.DataFrame(X_wine, columns=['Alcohol', 'Malic Acid'])
df['Class'] = y_wine
# Obtener los nombres de las clases
class_names = wine.target_names
# Visualización de los puntos con el ground truth de clusters
colors = ['r', 'g', 'b']
for class_label, color in zip(range(len(class_names)), colors):
subset = df[df['Class'] == class_label]
plt.scatter(subset['Alcohol'], subset['Malic Acid'], s=50, alpha=0.7, label=class_names[class_label], c=color)
plt.xlabel("Alcohol")
plt.ylabel("Ácido Málico")
plt.title("Vinos")
plt.legend()
plt.show()

import random
random.seed(42)
# Importar librerías necesarias
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.datasets import make_circles, make_moons
import seaborn as sns
# Fijar semilla para reproducibilidad
np.random.seed(42)
# Crear una lista para almacenar los datasets y sus nombres
datasets_dict = {}
# 1️ Dataset Sintético: Dos Clusters Gaussianos
X1 = np.random.normal(loc=[2, 2], scale=0.5, size=(50, 2)) # Cluster 1
X2 = np.random.normal(loc=[6, 6], scale=0.5, size=(50, 2)) # Cluster 2
X_gaussians = np.vstack((X1, X2))
y_gaussians = np.array([0]*50 + [1]*50)
datasets_dict["Clusters Gaussianos"] = (X_gaussians, y_gaussians, 2)
# 2️ Dataset Clásico: Iris Dataset
iris = datasets.load_iris()
X_iris = iris.data[:, :2] # Tomamos solo las primeras dos características para visualización
y_iris = iris.target
datasets_dict["Iris Dataset"] = (X_iris, y_iris, 3)
# 3️ Dataset Sintético: Anillos Concéntricos
X_circles, y_circles = make_circles(n_samples=300, factor=0.5, noise=0.05)
datasets_dict["Anillos Concéntricos"] = (X_circles, y_circles, 2)
# 4️ Dataset Sintético: Lunas Entrelazadas
X_moons, y_moons = make_moons(n_samples=300, noise=0.05)
datasets_dict["Lunas Entrelazadas"] = (X_moons, y_moons, 2)
# 5️ Dataset Real: Pingüinos
df_penguins = sns.load_dataset('penguins').dropna()
X_penguins = df_penguins[['bill_length_mm', 'bill_depth_mm']].values
y_penguins = df_penguins['species'].astype('category').cat.codes.values
datasets_dict["Pingüinos"] = (X_penguins, y_penguins, 3)
# Cargar un dataset real pequeño: Datos de vinos de sklearn
from sklearn.datasets import load_wine
# Cargar el dataset
wine = load_wine()
X_wine = wine.data[:, :2] # Tomamos solo las primeras dos características para visualización
y_wine = wine.target
datasets_dict["Vinos (Wine Dataset)"] = (X_wine, y_wine, 3)
# Visualizar los datasets incluyendo el de pingüinos
fig, axes = plt.subplots(len(datasets_dict), 2, figsize=(12, 5 * len(datasets_dict)))
axes = axes.flatten()
for i, (name, (X, y, n_clusters)) in enumerate(datasets_dict.items()):
# K-means clustering
kmeans = KMeans(n_clusters=n_clusters, n_init=20)#random_state=42,
kmeans.fit(X)
labels = kmeans.labels_
# Plot K-means result
scatter = axes[2*i].scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', edgecolor='k')
axes[2*i].set_title(f"K-Means en {name}")
axes[2*i].text(0.95, 0.95, f"Número real de clusters: {n_clusters}",
horizontalalignment='right',
verticalalignment='top',
transform=axes[2*i].transAxes,
bbox=dict(facecolor='white', alpha=0.6))
# Plot ground truth
scatter = axes[2*i + 1].scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', edgecolor='k')
axes[2*i + 1].set_title(f"Ground Truth en {name}")
axes[2*i + 1].text(0.95, 0.95, f"Número real de clusters: {n_clusters}",
horizontalalignment='right',
verticalalignment='top',
transform=axes[2*i + 1].transAxes,
bbox=dict(facecolor='white', alpha=0.6))
if name == "Pingüinos":
axes[2*i].set_xlabel('Longitud del Pico (mm)')
axes[2*i].set_ylabel('Profundidad del Pico (mm)')
axes[2*i + 1].set_xlabel('Longitud del Pico (mm)')
axes[2*i + 1].set_ylabel('Profundidad del Pico (mm)')
elif name == "Vinos (Wine Dataset)":
axes[2*i].set_xlabel('Alcohol')
axes[2*i].set_ylabel('Ácido Málico')
axes[2*i + 1].set_xlabel('Alcohol')
axes[2*i + 1].set_ylabel('Ácido Málico')
elif name == "Iris Dataset":
axes[2*i].set_xlabel('Longitud del Sépalo')
axes[2*i].set_ylabel('Ancho del Sépalo')
axes[2*i + 1].set_xlabel('Longitud del Sépalo')
axes[2*i + 1].set_ylabel('Ancho del Sépalo')
else:
axes[2*i].set_xlabel('Característica 1')
axes[2*i].set_ylabel('Característica 2')
axes[2*i + 1].set_xlabel('Característica 1')
axes[2*i + 1].set_ylabel('Característica 2')
# Ajustar diseño
plt.tight_layout()
plt.show()

Si no tenemos el "ground truth" ¿cómo sabemos cuántos clusters ejecutar?¶
Evaluación de Clustering: Método del Codo y Silhouette Score¶
Método del Codo¶
Definición¶
El método del codo es una técnica visual utilizada para determinar el número óptimo de clusters en K-Means. Se basa en la inercia intra-cluster, que mide la dispersión de los puntos dentro de sus respectivos clusters.
Matemáticamente, la inercia se define como:
$\text{Inercia} = \sum_{k=1}^{K} \sum_{i \in C_k} \|X_i - \mu_k\|^2$
donde:
- $ K $ es el número de clusters.
- $ C_k $ representa el conjunto de puntos en el cluster $ k $.
- $ \mu_k $ es el centroide del cluster $ C_k $.
- $ \|X_i - \mu_k\|^2 $ es la distancia euclidiana al centroide.
Interpretación¶
- Se calcula la inercia para diferentes valores de $ K $.
- Se grafica $ K $ vs. Inercia.
- El punto donde la pendiente comienza a disminuir significativamente es el "codo", que representa el número óptimo de clusters.
Ejemplo de Gráfica¶
Un ejemplo típico del método del codo muestra una curva decreciente con un punto de inflexión, donde la ganancia por agregar más clusters se reduce:

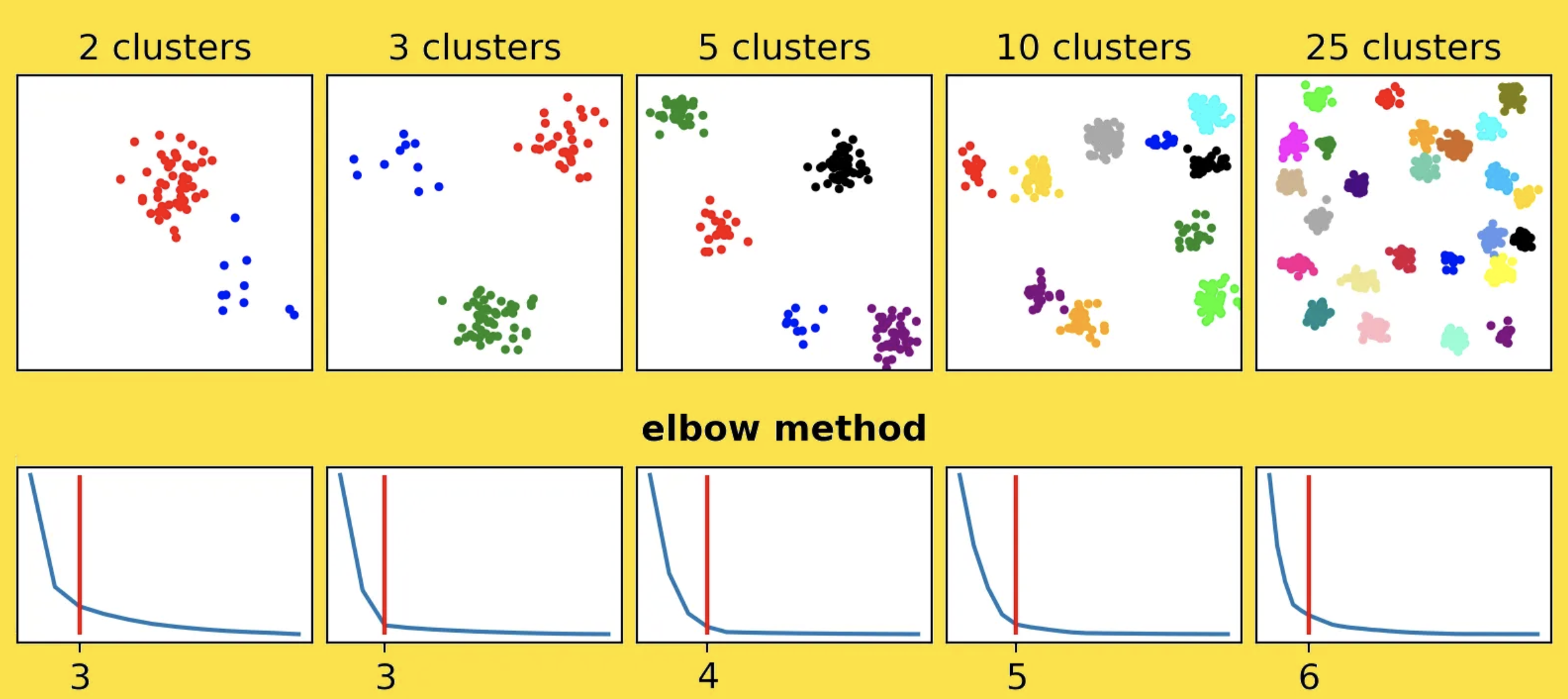
Silhouette Score¶
Definición¶
El Silhouette Score es una métrica que evalúa la calidad de un clustering midiendo qué tan bien cada punto está agrupado con su propio cluster y separado de otros clusters. Se define para cada punto $ i $ como:
$s(i) = \frac{b(i) - a(i)}{\max(a(i), b(i))}$
donde:
- $ a(i) $ es la distancia promedio de $ i $ a los otros puntos dentro de su cluster.
$ b(i) $ La distancia promedio de $i$ a todos los puntos del cluster más cercano al que no pertenece.
El valor de $ s(i) $ está en el rango $[-1, 1]$.
Interpretación¶
- $ s(i) \approx 1 $: El punto está bien asignado a su cluster.
- $ s(i) \approx 0 $: El punto está en el límite entre dos clusters.
- $ s(i) < 0 $: El punto está mal asignado y probablemente debería estar en otro cluster.
Cómo utilizarlo¶
- Se calcula el promedio de $ s(i) $ para todos los puntos, obteniendo un Silhouette Score global.
- Un mayor Silhouette Score indica una mejor partición de los datos.
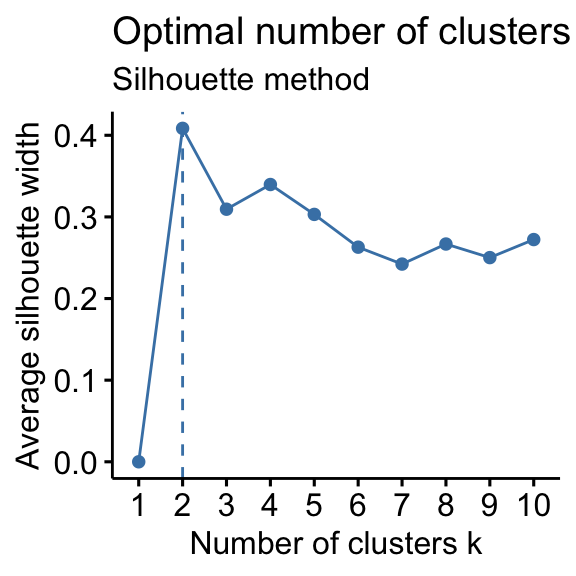
Ejemplo de Gráfica¶
La gráfica típica del Silhouette Score muestra su valor en función de $ K $, ayudando a elegir el número óptimo de clusters:
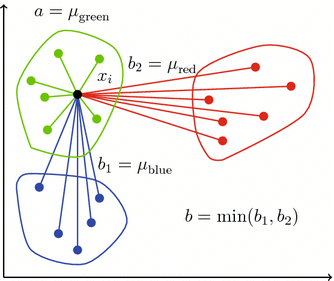
La figura muestra el cálculo del Silhouette de un punto específico (x_i) (el punto negro), comparándolo con los clústeres de colores.
1) Qué es (a) (cohesión intra-clúster)¶
(x_i) está asignado al clúster verde. Entonces:
$a(i)=\frac{1}{|C_{\text{green}}|-1}\sum_{x_j\in C_{\text{green}}, j\neq i} d(x_i,x_j)$
En el dibujo aparece como ($a=\mu_{\text{green}}$): el promedio de las distancias (líneas verdes) desde ($x_i$) a los otros puntos del mismo clúster.
- Pequeño (a(i)) entonces ($x_i$) está bien "metido" dentro del clúster.
2) Qué es (b) (separación hacia el clúster vecino)¶
Para cada otro clúster, calculas el promedio de distancias desde (x_i) hacia ese clúster:
$b_{k}(i)=\frac{1}{|C_k|}\sum_{x_j\in C_k} d(x_i,x_j)$
En el dibujo:
- ($b_1=\mu_{\text{blue}}$) (promedio hacia el clúster azul)
- ($b_2=\mu_{\text{red}}$) (promedio hacia el clúster rojo)
Luego tomas el más cercano en promedio (el “clúster vecino”):
$b(i)=\min_{k\neq \text{green}} b_k(i)$
Por eso en la imagen dice ($b=\min(b_1,b_2)$).
- Grande (b(i)) ⇒ los otros clústeres están lejos de ($x_i$).
3) Silhouette del punto ($x_i$)¶
Con esos dos números:
$s(i)=\frac{b(i)-a(i)}{\max{a(i),,b(i)}}\qquad\in[-1,1]$
Interpretación:
- ($s(i)\approx 1$): (a) pequeño y (b) grande ⇒ bien asignado y bien separado.
- ($s(i)\approx 0$): está cerca de la frontera entre clústeres (($a\approx b$)).
- ($s(i)<0$): ($a>b$) ⇒ está más cerca (en promedio) de otro clúster que del suyo entonces probable mala asignación.
4) Cómo se usa para elegir (K)¶
Para cada (K), calculas el promedio:
$S(K)=\frac{1}{n}\sum_{i=1}^n s(i)$
y sueles elegir el (K) que maximiza (S(K)) (o donde (S(K)) es alto y estable).
Comparación entre ambos métodos¶
| Método | ¿Qué mide? | ¿Cómo se usa? |
|---|---|---|
| Método del Codo | Dispersión dentro de los clusters (inercia) | Buscar el "codo" en la curva de inercia |
| Silhouette Score | Separación entre clusters y compactación interna | Elegir el $ K $ con mayor Silhouette Score |
Conclusión:
- El Método del Codo es útil para determinar cuándo dejar de agregar más clusters.
- El Silhouette Score ayuda a evaluar qué tan bien están formados los clusters.
Usar ambos métodos juntos permite una mejor elección del número de clusters en K-Means.
# Importar librerías necesarias
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.datasets import make_circles, make_moons
import seaborn as sns
from sklearn.metrics import silhouette_score
# Fijar semilla para reproducibilidad
np.random.seed(42)
# Crear una lista para almacenar los datasets y sus nombres
datasets_dict = {}
# 1️ Dataset Sintético: Dos Clusters Gaussianos
X1 = np.random.normal(loc=[2, 2], scale=0.5, size=(50, 2)) # Cluster 1
X2 = np.random.normal(loc=[6, 6], scale=0.5, size=(50, 2)) # Cluster 2
X_gaussians = np.vstack((X1, X2))
y_gaussians = np.array([0]*50 + [1]*50)
datasets_dict["Clusters Gaussianos"] = (X_gaussians, y_gaussians, 2)
# 2️ Dataset Clásico: Iris Dataset
iris = datasets.load_iris()
X_iris = iris.data[:, :2] # Tomamos solo las primeras dos características para visualización
y_iris = iris.target
datasets_dict["Iris Dataset"] = (X_iris, y_iris, 3)
# 3️ Dataset Sintético: Anillos Concéntricos
X_circles, y_circles = make_circles(n_samples=300, factor=0.5, noise=0.05)
datasets_dict["Anillos Concéntricos"] = (X_circles, y_circles, 2)
# 4️ Dataset Sintético: Lunas Entrelazadas
X_moons, y_moons = make_moons(n_samples=300, noise=0.05)
datasets_dict["Lunas Entrelazadas"] = (X_moons, y_moons, 2)
# 5️ Dataset Real: Pingüinos
df_penguins = sns.load_dataset('penguins').dropna()
X_penguins = df_penguins[['bill_length_mm', 'bill_depth_mm']].values
y_penguins = df_penguins['species'].astype('category').cat.codes.values
datasets_dict["Pingüinos"] = (X_penguins, y_penguins, 3)
# Cargar un dataset real pequeño: Datos de vinos de sklearn
from sklearn.datasets import load_wine
# Cargar el dataset
wine = load_wine()
X_wine = wine.data[:, :2] # Tomamos solo las primeras dos características para visualización
y_wine = wine.target
datasets_dict["Vinos (Wine Dataset)"] = (X_wine, y_wine, 3)
# Función para calcular el método del codo y la puntuación de Silhouette
def analizar_num_clusters(X, max_k=6):
inertias = []
silhouette_scores = []
K_values = range(1, max_k+1) # Empezar desde 1 cluster
for k in K_values:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=20)
labels = kmeans.fit_predict(X)
# Inercia (método del codo)
inertias.append(kmeans.inertia_)
# Puntuación de Silhouette (si hay más de un cluster)
if k > 1:
silhouette_scores.append(silhouette_score(X, labels))
else:
silhouette_scores.append(0)
return K_values, inertias, silhouette_scores
# Aplicar análisis en todos los datasets
fig, axes = plt.subplots(len(datasets_dict), 4, figsize=(24, 5 * len(datasets_dict)))
axes = axes.flatten()
for i, (name, (X, y, n_clusters)) in enumerate(datasets_dict.items()):
K_values, inertias, silhouette_scores = analizar_num_clusters(X, max_k=6)
# Gráfico del método del codo
axes[4*i].plot(K_values, inertias, marker='o', linestyle='-')
axes[4*i].set_title(f"Método del Codo - {name}")
axes[4*i].set_xlabel("Número de Clusters (K)")
axes[4*i].set_ylabel("Inercia")
axes[4*i].text(0.95, 0.95, f"Número real de clusters: {n_clusters}",
horizontalalignment='right',
verticalalignment='top',
transform=axes[4*i].transAxes,
bbox=dict(facecolor='white', alpha=0.6))
# Gráfico del Silhouette Score
axes[4*i+1].plot(K_values, silhouette_scores, marker='o', linestyle='-')
axes[4*i+1].set_title(f"Silhouette Score - {name}")
axes[4*i+1].set_xlabel("Número de Clusters (K)")
axes[4*i+1].set_ylabel("Puntuación Silhouette")
axes[4*i+1].text(0.95, 0.95, f"Número real de clusters: {n_clusters}",
horizontalalignment='right',
verticalalignment='top',
transform=axes[4*i+1].transAxes,
bbox=dict(facecolor='white', alpha=0.6))
# K-means clustering
kmeans = KMeans(n_clusters=n_clusters, random_state=42, n_init=20)
kmeans.fit(X)
labels = kmeans.labels_
# Plot K-means result
scatter = axes[4*i+2].scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', edgecolor='k')
axes[4*i+2].set_title(f"K-Means en {name}")
axes[4*i+2].text(0.95, 0.95, f"Número real de clusters: {n_clusters}",
horizontalalignment='right',
verticalalignment='top',
transform=axes[4*i+2].transAxes,
bbox=dict(facecolor='white', alpha=0.6))
# Plot ground truth
scatter = axes[4*i+3].scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', edgecolor='k')
axes[4*i+3].set_title(f"Ground Truth en {name}")
axes[4*i+3].text(0.95, 0.95, f"Número real de clusters: {n_clusters}",
horizontalalignment='right',
verticalalignment='top',
transform=axes[4*i+3].transAxes,
bbox=dict(facecolor='white', alpha=0.6))
if name == "Pingüinos":
axes[4*i+2].set_xlabel('Longitud del Pico (mm)')
axes[4*i+2].set_ylabel('Profundidad del Pico (mm)')
axes[4*i+3].set_xlabel('Longitud del Pico (mm)')
axes[4*i+3].set_ylabel('Profundidad del Pico (mm)')
elif name == "Vinos (Wine Dataset)":
axes[4*i+2].set_xlabel('Alcohol')
axes[4*i+2].set_ylabel('Ácido Málico')
axes[4*i+3].set_xlabel('Alcohol')
axes[4*i+3].set_ylabel('Ácido Málico')
elif name == "Iris Dataset":
axes[4*i+2].set_xlabel('Longitud del Sépalo')
axes[4*i+2].set_ylabel('Ancho del Sépalo')
axes[4*i+3].set_xlabel('Longitud del Sépalo')
axes[4*i+3].set_ylabel('Ancho del Sépalo')
else:
axes[4*i+2].set_xlabel('Característica 1')
axes[4*i+2].set_ylabel('Característica 2')
axes[4*i+3].set_xlabel('Característica 1')
axes[4*i+3].set_ylabel('Característica 2')
# Ajustar diseño
plt.tight_layout()
plt.show()

Problemas del Método del Codo y del Silhouette Score¶
1. Problemas del Método del Codo¶
1.1 No siempre hay un "codo" claro¶
El método del codo se basa en encontrar un punto de inflexión en la gráfica de inercia, pero en algunos datasets la curva es suave y sin un codo evidente, lo que dificulta la selección del número óptimo de clusters.
Ejemplo:
- Si la inercia disminuye gradualmente sin un punto de cambio claro, la elección de $ K $ se vuelve subjetiva.
Ejemplo: gráfico sin codo claro

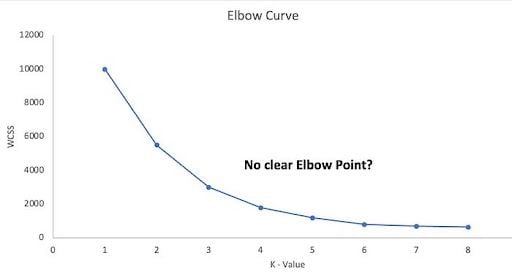
1.2 Sensible a la escala de los datos¶
- Si los datos no están bien escalados, la inercia puede estar dominada por variables con valores más grandes.
- Solución: Normalizar los datos antes de aplicar K-means.
1.3 No evalúa la separación de clusters¶
El método del codo solo mide compactación interna (inercia), pero no indica si los clusters están bien separados entre sí.
Ejemplo:
- Dos clusters pueden ser compactos pero estar muy cerca el uno del otro, lo que genera mala separación.
Conclusión:
El método del codo es útil pero subjetivo. Debe complementarse con otro método como el Silhouette Score.
2. Problemas del Silhouette Score¶
2.1 Favorece valores bajos de $ K $¶
El Silhouette Score suele favorecer valores bajos de $ K $, ya que a mayor número de clusters, los puntos están más cerca de su propio cluster, incluso si la segmentación no es útil.
Ejemplo:
- Si $ K=4 $ da un Silhouette Score de 0.51 y $ K=7 $ da 0.49, pero los clusters de $ K=7 $ tienen más sentido, elegir $ K=4 $ sería un error.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# Fijar semilla para reproducibilidad
np.random.seed(42)
# Generar siete clusters gausianos
X1 = np.random.normal(loc=[2, 2], scale=.8, size=(50, 2)) # Cluster 1
X2 = np.random.normal(loc=[6, 6], scale=.8, size=(50, 2)) # Cluster 2
X3 = np.random.normal(loc=[2, 6], scale=.8, size=(50, 2)) # Cluster 3
X4 = np.random.normal(loc=[6, 2], scale=.8, size=(50, 2)) # Cluster 4
X5 = np.random.normal(loc=[4, 4], scale=.8, size=(50, 2)) # Cluster 5
X6 = np.random.normal(loc=[8, 8], scale=.8, size=(50, 2)) # Cluster 6
X7 = np.random.normal(loc=[0, 0], scale=.8, size=(50, 2)) # Cluster 7
# X43 = np.random.normal(loc=[4, 10], scale=1.9, size=(50, 2)) # Cluster 4
# X53 = np.random.normal(loc=[4, 0], scale=1.9, size=(50, 2)) # Cluster 5
# X63 = np.random.normal(loc=[9, -2], scale=1.9, size=(50, 2)) # Cluster 6
# X73 = np.random.normal(loc=[-2, 10], scale=1.9, size=(50, 2)) # Cluster 7
# Unir en un solo dataset
X = np.vstack((X1, X2, X3, X4, X5, X6, X7)) #,X43,X53,X63,X73))
# Crear etiquetas de ground truth
y = np.array([0]*50 + [1]*50 + [2]*50 + [3]*50 + [4]*50 + [5]*50 + [6]*50) #. + [7]*50) # + [8]*50 + [9]*50 + [10]*50)
# Visualización
plt.scatter(X[y == 0, 0], X[y == 0, 1], s=50, alpha=0.7, label='Cluster 1')
plt.scatter(X[y == 1, 0], X[y == 1, 1], s=50, alpha=0.7, label='Cluster 2')
plt.scatter(X[y == 2, 0], X[y == 2, 1], s=50, alpha=0.7, label='Cluster 3')
plt.scatter(X[y == 3, 0], X[y == 3, 1], s=50, alpha=0.7, label='Cluster 4')
plt.scatter(X[y == 4, 0], X[y == 4, 1], s=50, alpha=0.7, label='Cluster 5')
plt.scatter(X[y == 5, 0], X[y == 5, 1], s=50, alpha=0.7, label='Cluster 6')
plt.scatter(X[y == 6, 0], X[y == 6, 1], s=50, alpha=0.7, label='Cluster 7')
# plt.scatter(X[y == 7, 0], X[y == 7, 1], s=50, alpha=0.7, label='Cluster 7')
# plt.scatter(X[y == 8, 0], X[y == 8, 1], s=50, alpha=0.7, label='Cluster 7')
# plt.scatter(X[y == 9, 0], X[y == 9, 1], s=50, alpha=0.7, label='Cluster 7')
# plt.scatter(X[y == 10, 0], X[y == 10, 1], s=50, alpha=0.7, label='Cluster 7')
plt.title("Siete Clusters Gaussianos")
plt.legend()
plt.show()
# Calcular el silhouette score para diferentes números de clusters
silhouette_scores = []
range_n_clusters = range(2, 11) # No tiene sentido calcular silhouette score para 1 cluster
for n_clusters in range_n_clusters:
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
cluster_labels = kmeans.fit_predict(X)
sil_score = silhouette_score(X, cluster_labels)
silhouette_scores.append(sil_score)
# Plotear la curva de silhouette scores
plt.plot(range_n_clusters, silhouette_scores, marker='o')
plt.title("Silhouette Scores para Diferentes Números de Clusters")
plt.xlabel("Número de Clusters")
plt.ylabel("Silhouette Score")
plt.xticks(range_n_clusters)
plt.grid(True)
plt.show()


2.2 No funciona bien en clusters de formas no convexas¶
El Silhouette Score asume que los clusters tienen forma esférica. Si los clusters tienen formas complejas como lunas o anillos concéntricos, el puntaje puede ser engañoso.
Ejemplo:
- En el dataset de anillos concéntricos, K-Means fallará, pero el Silhouette Score puede indicar que un $ K $ es "óptimo" aunque no tenga sentido.
2.3 Computacionalmente costoso¶
- Requiere calcular distancias entre todos los puntos y clusters, lo cual es costoso en datasets grandes.
- Alternativa: Para grandes volúmenes de datos, se pueden tomar muestras aleatorias en lugar de usar todos los puntos.
Comparación de Problemas¶
| Método | Problemas principales |
|---|---|
| Método del Codo | No siempre hay un codo claro, depende de la escala, no mide separación de clusters |
| Silhouette Score | Favorece pocos clusters, no funciona bien en formas no convexas, es costoso computacionalmente, depende de la escala |
Conclusión¶
- El Método del Codo es útil, pero subjetivo. No siempre hay un codo claro y no mide separación de clusters.
- El Silhouette Score ayuda a medir separación, pero favorece $ K $ pequeños y falla en estructuras no esféricas.
- Lo mejor es usar ambos métodos juntos y complementar con interpretación visual.
Limitaciones del Algoritmo K-Means¶
a) Sensibilidad a la inicialización¶
Si los centroides iniciales no son elegidos adecuadamente, K-Means puede converger a soluciones subóptimas. Un método para mitigar esto es la inicialización K-Means++, que selecciona los centroides de manera más informada.
Cómo funciona el algoritmo K-Means++¶
El algoritmo K-Means++ mejora la inicialización de los centroides en K-Means estándar mediante una selección probabilística que favorece la dispersión de los centros iniciales. Esto ayuda a evitar convergencias a mínimos locales deficientes.
1. Paso de Inicialización¶
El procedimiento de inicialización sigue los siguientes pasos:
Seleccionar el primer centro aleatorio:
- Se elige el primer centro $ c_1 $ de forma aleatoria de entre todos los puntos del conjunto de datos $ X $.
Seleccionar los siguientes centros de manera probabilística:
- Para cada nuevo centro $ c_i $, se selecciona un punto $ x \in X $ con una probabilidad proporcional al cuadrado de su distancia al centro más cercano ya seleccionado.
Formalmente, si ya hemos seleccionado los centros $ c_1, c_2, ..., c_{i-1} $, definimos la distancia mínima de un punto $ x $ a estos centros como:
$D(x) = \min_{j \in \{1, ..., i-1\}} \| x - c_j \|^2$
Luego, la probabilidad de seleccionar un nuevo punto $ x $ como el próximo centro $ c_i $ es:
$P(x) = \frac{D(x)}{\sum_{x' \in X} D(x')}$
Esto significa que los puntos más alejados de los centros ya seleccionados tienen una mayor probabilidad de ser elegidos.
Ventajas de K-Means++¶
El uso de esta inicialización permite que los centroides comiencen en posiciones mejor distribuidas, lo que:
- Mejora la convergencia del algoritmo.
- Reduce la probabilidad de quedar atrapado en un mínimo local subóptimo.
- Generalmente disminuye el número de iteraciones necesarias para alcanzar un clustering estable.
Este proceso garantiza que la distribución inicial de los centros de los clusters sea más representativa de la estructura real de los datos, lo que suele llevar a una mejor partición final.
# Ejemplo inicialización k-means++
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sys
# Definir la media y la covarianza para la primera distribución gaussiana
mean_01 = np.array([0.0, 0.0])
cov_01 = np.array([[1, 0.3], [0.3, 1]])
# Generar 100 puntos de datos para la primera distribución gaussiana
dist_01 = np.random.multivariate_normal(mean_01, cov_01, 100)
# Definir la media y la covarianza para la segunda distribución gaussiana
mean_02 = np.array([6.0, 7.0])
cov_02 = np.array([[1.5, 0.3], [0.3, 1]])
# Generar 100 puntos de datos para la segunda distribución gaussiana
dist_02 = np.random.multivariate_normal(mean_02, cov_02, 100)
# Definir la media y la covarianza para la tercera distribución gaussiana
mean_03 = np.array([7.0, -5.0])
cov_03 = np.array([[1.2, 0.5], [0.5, 1]])
# Generar 100 puntos de datos para la tercera distribución gaussiana
dist_03 = np.random.multivariate_normal(mean_03, cov_01, 100)
# Definir la media y la covarianza para la cuarta distribución gaussiana
mean_04 = np.array([2.0, -7.0])
cov_04 = np.array([[1.2, 0.5], [0.5, 1.3]])
# Generar 100 puntos de datos para la cuarta distribución gaussiana
dist_04 = np.random.multivariate_normal(mean_04, cov_01, 100)
# Combinar todas las distribuciones en un solo conjunto de datos
data = np.vstack((dist_01, dist_02, dist_03, dist_04))
# Mezclar aleatoriamente los datos
np.random.shuffle(data)
# Función para graficar los datos y los centroides
def plot(data, centroids):
plt.scatter(data[:, 0], data[:, 1], marker='.', color='gray', label='data points')
plt.scatter(centroids[:-1, 0], centroids[:-1, 1], color='black', label='previously selected centroids')
plt.scatter(centroids[-1, 0], centroids[-1, 1], color='red', label='next centroid')
plt.title('Select % d th centroid' % (centroids.shape[0]))
plt.legend()
plt.xlim(-5, 12)
plt.ylim(-10, 15)
plt.show()
# Función para calcular la distancia euclidiana entre dos puntos
def distance(p1, p2):
return np.sqrt(np.sum((p1 - p2)**2))
# Algoritmo de inicialización k-means++
def initialize(data, k):
'''
Inicializa los centroides para K-means++
Entradas:
data - array de numpy con los puntos de datos de forma (200, 2)
k - número de clusters
'''
centroids = []
# Seleccionar el primer centroide aleatoriamente de los datos
centroids.append(data[np.random.randint(data.shape[0]), :])
plot(data, np.array(centroids))
# Seleccionar los siguientes k-1 centroides
for c_id in range(k - 1):
dist = []
for i in range(data.shape[0]):
point = data[i, :]
d = sys.maxsize
# Calcular la distancia mínima de cada punto a los centroides seleccionados
for j in range(len(centroids)):
temp_dist = distance(point, centroids[j])
d = min(d, temp_dist)
dist.append(d)
dist = np.array(dist)
# Seleccionar el siguiente centroide como el punto con la distancia máxima
next_centroid = data[np.argmax(dist), :]
centroids.append(next_centroid)
dist = []
plot(data, np.array(centroids))
return centroids
# Inicializar los centroides con k=4
centroids = initialize(data, k=4)




b) Sensibilidad a la escala¶
Dado que el algoritmo usa distancia euclidiana, las variables con diferentes escalas pueden afectar la agrupación. Es recomendable estandarizar los datos antes de aplicar K-Means.
c) Requiere especificar $ K $¶
El número de clústeres $ K $ debe ser definido a priori.
d) Supone clusters esféricos¶
K-Means funciona mejor cuando los grupos son aproximadamente esféricos y tienen varianza similar. No es ideal para estructuras de datos con formas arbitrarias o distribuciones de densidad no uniformes.
e) No maneja bien el ruido y los outliers¶
Los puntos atípicos pueden afectar significativamente la ubicación de los centroides, lo que puede degradar la calidad del clustering.
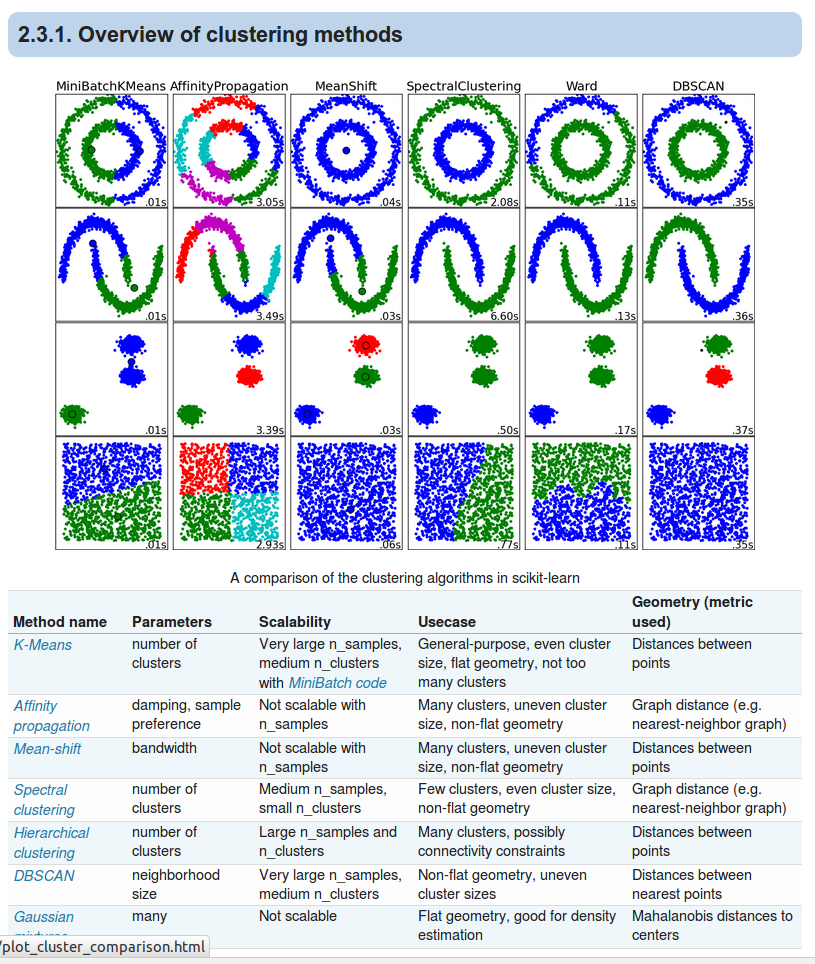
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans, DBSCAN, AffinityPropagation, MeanShift, SpectralClustering, AgglomerativeClustering
from sklearn.datasets import make_moons, make_circles, make_blobs
from sklearn.preprocessing import StandardScaler
# Configuración del estilo
sns.set(style="whitegrid")
# Generar conjuntos de datos
datasets = {
"Círculos": make_circles(n_samples=500, factor=0.5, noise=0.05, random_state=42),
"Lunas": make_moons(n_samples=500, noise=0.05, random_state=42),
"Blobs": make_blobs(n_samples=500, centers=3, cluster_std=1.0, random_state=42),
"Aleatorio": (np.random.rand(500, 2), None) # Datos aleatorios sin estructura
}
# Definir algoritmos de clustering
clustering_algorithms = {
"K-Means": KMeans(n_clusters=3, random_state=42, n_init=10),
"Affinity Propagation": AffinityPropagation(damping=0.9),
"MeanShift": MeanShift(),
"Spectral Clustering": SpectralClustering(n_clusters=3, affinity="nearest_neighbors", random_state=42),
"Hierarchical Clustering (Ward)": AgglomerativeClustering(n_clusters=3),
"DBSCAN": DBSCAN(eps=0.2, min_samples=3)
}
# Crear una figura con una cuadrícula de subplots
n_datasets = len(datasets)
n_algorithms = len(clustering_algorithms)
fig, axes = plt.subplots(n_datasets, n_algorithms + 1, figsize=(20, 15))
# Aplicar clustering a cada conjunto de datos con cada algoritmo
for row, (dataset_name, (X, y)) in enumerate(datasets.items()):
# Normalizar datos
X_scaled = StandardScaler().fit_transform(X)
# Graficar datos originales en la primera columna
axes[row, 0].scatter(X_scaled[:, 0], X_scaled[:, 1], s=10, color="gray")
axes[row, 0].set_title(f"Datos: {dataset_name}")
axes[row, 0].set_xticks([])
axes[row, 0].set_yticks([])
# Aplicar cada algoritmo de clustering
for col, (algo_name, algo) in enumerate(clustering_algorithms.items(), start=1):
# Ajustar el algoritmo de clustering
clustering = algo.fit(X_scaled)
# Obtener etiquetas de los clusters
if hasattr(clustering, "labels_"):
labels = clustering.labels_
else:
# Para algoritmos que no tienen labels_, predecir clusters
labels = clustering.fit_predict(X_scaled)
# Graficar los clusters
axes[row, col].scatter(X_scaled[:, 0], X_scaled[:, 1], c=labels, cmap="viridis", s=10)
axes[row, col].set_title(algo_name)
axes[row, col].set_xticks([])
axes[row, col].set_yticks([])
# Ajustar el diseño y mostrar la gráfica
plt.tight_layout()
plt.show()

Clustering Jerárquico¶
Introducción¶
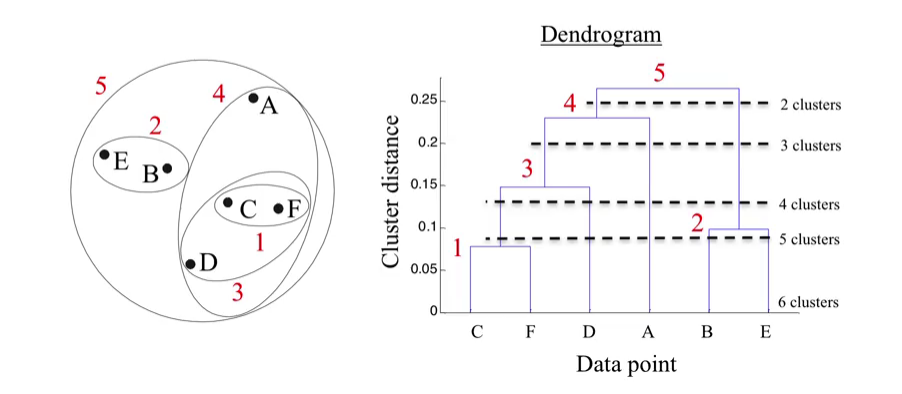
El clustering jerárquico es un método de agrupamiento que no requiere especificar el número de clusters de antemano, a diferencia de K-Means. Se basa en la construcción de una estructura jerárquica de los datos mediante un dendrograma, lo que permite explorar múltiples niveles de agrupación.
Un dendrograma es un diagrama en forma de árbol que representa la estructura de agrupamiento de un conjunto de datos en un algoritmo de clustering jerárquico, permitiendo visualizar cómo los elementos se agrupan en distintos niveles de similitud. Su estructura jerárquica organiza los datos en diferentes niveles, donde cada unión representa la formación de un grupo (cluster), y la proximidad de las ramas indica el grado de similitud entre los elementos. Además, la altura de las uniones en el dendrograma refleja la distancia o disimilitud entre los clusters, lo que permite interpretar la relación entre ellos y determinar el número óptimo de grupos en un conjunto de datos.
Aplicaciones del clustering jerárquico:
- Biología: Análisis filogenético para representar relaciones evolutivas.
- Genética: Agrupamiento de genes con expresiones similares.
- Marketing: Segmentación de clientes en grupos de comportamiento.
- Procesamiento de lenguaje natural: Agrupamiento de textos por similitud.
Definición Formal¶
Sea un conjunto de datos $ X = \{x_1, x_2, ..., x_n\} $ con $ x_i \in \mathbb{R}^d $. El clustering jerárquico busca construir una jerarquía de grupos basándose en la similitud entre observaciones.
Existen dos enfoques principales:
- Aglomerativo (bottom-up): Comienza con cada punto como un cluster y los fusiona sucesivamente.
- Divisivo (top-down): Comienza con un solo cluster y lo divide recursivamente.
El método más común es el aglomerativo, el cual sigue estos pasos:
- Inicializar cada observación como un cluster individual.
- Calcular las distancias entre todos los clusters.
- Combinar los dos clusters más cercanos.
- Repetir hasta que solo quede un cluster.
Elección de Distancia y Métodos de Vinculación¶
Para determinar la similitud entre clusters, se utilizan diferentes métricas de distancia y métodos de vinculación. La elección de estas métricas es fundamental, ya que afecta cómo se agrupan los datos y la forma final de los clusters.
a) Métricas de Distancia¶
Las métricas de distancia determinan cómo se mide la similitud entre dos puntos en el espacio de características. Dependiendo de la naturaleza de los datos y del problema, algunas métricas pueden ser más adecuadas que otras.
1️. Distancia Euclidiana (L2 Norm)¶
La distancia euclidiana es la métrica más comúnmente utilizada en clustering jerárquico y se define como:
$d_{\text{Euclidiana}}(x_i, x_j) = \sqrt{\sum_{k=1}^{d} (x_{ik} - x_{jk})^2}$
Esta métrica mide la distancia en línea recta entre dos puntos en un espacio $d$-dimensional.
Ventaja:
- Es intuitiva y fácil de calcular.
- Funciona bien en datos con distribuciones gaussianas y clusters esféricos.
Desventaja:
- Sensible a la escala de las variables: Si las características tienen rangos diferentes, las de mayor magnitud dominarán la distancia.
- No maneja bien clusters con formas alargadas o de distinta densidad.
Ejemplo:
Si estamos agrupando clientes por ingresos y edad, la distancia euclidiana puede ser útil si ambas características están escaladas correctamente.
Recomendación (breve desvío):
Si se usa esta métrica, es altamente recomendable estandarizar los datos antes de aplicarla, usando por ejemplo:
La idea central es que StandardScaler() hace que cada variable quede en una escala comparable. Si no estandarizas, una variable con números grandes puede dominar el cálculo de distancia, aunque no sea la más importante.
Qué hace este código¶
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
`
Se interpreta así:
StandardScaler()crea un objeto que va a estandarizar los datos.fit_transform(X):- fit: calcula, para cada columna de
X, su media y su desviación estándar. - transform: transforma cada valor usando:
- fit: calcula, para cada columna de
$z = \frac{x - \mu}{\sigma}$
donde:
- (x): valor original
- ($\mu$): media de la variable
- ($\sigma$): desviación estándar de la variable
Después de eso, cada variable queda aproximadamente con:
- media 0
- desviación estándar 1
Ejemplo 1: distancia sin estandarizar¶
Supongamos dos personas descritas por:
- Edad
- Ingreso mensual en pesos
A = [20, 500000]
B = [30, 650000]
La distancia euclidiana entre A y B es:
$d(A,B) = \sqrt{(20-30)^2 + (500000-650000)^2}$
$d(A,B) = \sqrt{(-10)^2 + (-150000)^2}$
$d(A,B) = \sqrt{100 + 22,500,000,000} \approx 150000$
Qué pasó aquí¶
Aunque la diferencia de edad es 10 años, la diferencia de ingreso es 150000 pesos, y esa escala enorme domina completamente la distancia.
En la práctica:
- la edad casi “no pesa”
- el ingreso decide casi todo
Ejemplo 2: mismo caso, pero estandarizando¶
Supongamos ahora este dataset:
X = [
[20, 500000],
[30, 650000],
[50, 700000]
]
Paso 1: medias¶
- media edad = ( $\frac{20+30+50}{3} = 33.33$ )
- media ingreso = ( $\frac{500000+650000+700000}{3} = 616666.67$ )
Paso 2: desviaciones estándar¶
Aproximadamente:
- desviación estándar edad ( $\approx 12.47$ )
- desviación estándar ingreso ( $\approx 84983.66$ )
Entonces:
Punto A = [20, 500000]¶
$ z_{\text{edad}}(A) = \frac{20-33.33}{12.47} \approx -1.07 $
$ z_{\text{ingreso}}(A) = \frac{500000-616666.67}{84983.66} \approx -1.37 $
A escalado:
$ A' \approx [-1.07, -1.37] $
Punto B = [30, 650000]¶
$ z_{\text{edad}}(B) = \frac{30-33.33}{12.47} \approx -0.27 $
$ z_{\text{ingreso}}(B) = \frac{650000-616666.67}{84983.66} \approx 0.39 $
B escalado:
$ B' \approx [-0.27, 0.39] $
Distancia entre A' y B'¶
$ d(A',B') = \sqrt{(-1.07 - (-0.27))^2 + (-1.37 - 0.39)^2} $
$ d(A',B') = \sqrt{(-0.80)^2 + (-1.76)^2} $
$ d(A',B') = \sqrt{0.64 + 3.10} = \sqrt{3.74} \approx 1.93 $
Qué pasó ahora¶
Ahora:
- edad e ingreso aportan en una escala comparable
- ninguna variable domina solo por tener números más grandes
- cada diferencia se interpreta en función de la variabilidad típica de su variable
Importante¶
En este ejemplo, las variables estandarizadas no quedan iguales ni aportan exactamente lo mismo. Eso es normal.
La idea correcta no es:
- “al estandarizar, todas las diferencias quedan iguales”
La idea correcta es:
- “al estandarizar, cada variable pasa a medirse en unidades de su propia dispersión”
Es decir, una diferencia en edad y una diferencia en ingreso ya no se comparan en sus unidades originales, sino en términos de cuántas desviaciones estándar representan.
Intuición general¶
La distancia euclidiana usual es:
$ d(x_i, x_j) = \sqrt{\sum_{k=1}^{d} (x_{ik} - x_{jk})^2} $
Si una variable tiene escala muy grande, puede dominar el cálculo solo por el tamaño de sus números.
Con estandarización, en la práctica estamos comparando algo más parecido a:
$ d(x_i, x_j) = \sqrt{\sum_{k=1}^{d} \left( \frac{x_{ik} - x_{jk}}{\sigma_k} \right)^2} $
Así, cada diferencia se divide por la desviación estándar de su propia variable.
Conclusión¶
Estandarizar no hace que todas las variables aporten exactamente lo mismo, pero sí evita que una variable domine la distancia únicamente por estar medida en una escala numérica mayor.
Por eso, en métodos basados en distancia como K-means, clustering jerárquico, KNN o PCA, suele ser recomendable estandarizar las variables antes de aplicar el algoritmo.
Mini ejemplo en Python¶
import numpy as np
from sklearn.preprocessing import StandardScaler
from scipy.spatial.distance import euclidean
X = np.array([
[20, 500000],
[30, 600000],
[40, 700000]
])
# Distancia sin estandarizar
d_original = euclidean(X[0], X[1])
# Estandarización
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Distancia estandarizada
d_scaled = euclidean(X_scaled[0], X_scaled[1])
print("Distancia original:", d_original)
print("Distancia escalada:", d_scaled)
print("\nDatos escalados:\n", X_scaled)
Conceptualmente:
Distancia originalmuy grande, dominada por ingresoDistancia escaladamucho más balanceada
Resumen¶
Si una variable está en pesos y otra en años, la de pesos puede dominar la distancia solo por su escala. Estandarizar evita que el algoritmo confunda "magnitud numérica" con "importancia real".
Cálculo en Python de la distancia euclidiana¶
import numpy as np
from scipy.spatial.distance import euclidean
# Definir dos puntos en un espacio 2D
p1 = np.array([3, 4])
p2 = np.array([7, 1])
# Cálculo manual de la distancia Euclidiana
dist_euclid = np.sqrt(np.sum((p1 - p2) ** 2))
print(f"Distancia Euclidiana (manual): {dist_euclid:.4f}")
# Usando scipy
dist_euclid_scipy = euclidean(p1, p2)
print(f"Distancia Euclidiana (scipy): {dist_euclid_scipy:.4f}")
2. Distancia Manhattan (norma L1)¶
La distancia Manhattan mide la suma de las diferencias absolutas entre coordenadas:
$d_{\text{Manhattan}}(x_i, x_j) = \sum_{k=1}^{d} |x_{ik} - x_{jk}|$
Ventajas:
- Es menos sensible a outliers porque no eleva las diferencias al cuadrado, así que valores extremos no dominan tanto la distancia.
- Puede funcionar mejor en alta dimensión porque reparte la contribución entre variables de forma más estable que la distancia euclidiana.
Desventajas:
- No representa la distancia en línea recta, por lo que no es ideal si la noción de cercanía geométrica es importante.
- Puede inducir clusters no esféricos, porque la cercanía se define por desplazamientos horizontales y verticales acumulados, no por distancia en línea recta, lo que a veces no calza bien con algoritmos o estructuras que esperan otra forma de proximidad.
Ejemplo: Es natural en movimientos sobre una cuadrícula, como calles en una ciudad donde solo se avanza horizontal o verticalmente.
Recomendación: Suele ser útil cuando interesa medir diferencias acumuladas variable por variable, o cuando hay riesgo de que algunos valores extremos distorsionen la distancia.
Cálculo en Python
from scipy.spatial.distance import cityblock
# Cálculo manual de la distancia Manhattan
dist_manhattan = np.sum(np.abs(p1 - p2))
print(f"Distancia Manhattan (manual): {dist_manhattan:.4f}")
# Usando scipy
dist_manhattan_scipy = cityblock(p1, p2)
print(f"Distancia Manhattan (scipy): {dist_manhattan_scipy:.4f}")
Visualización de las distancias
import matplotlib.pyplot as plt
# Puntos
x_values = [p1[0], p2[0]]
y_values = [p1[1], p2[1]]
plt.figure(figsize=(6, 6))
# Distancia Euclidiana (línea recta)
plt.plot(x_values, y_values, 'bo-', label="Distancia Euclidiana", linewidth=2)
# Distancia Manhattan (trayectoria en escalera)
plt.plot([p1[0], p2[0]], [p1[1], p1[1]], 'r--', linewidth=2)
plt.plot([p2[0], p2[0]], [p1[1], p2[1]], 'r--', linewidth=2, label="Distancia Manhattan")
# Configuración del gráfico
plt.scatter(*p1, color='blue', label="Punto 1 (3,4)", s=100)
plt.scatter(*p2, color='red', label="Punto 2 (7,1)", s=100)
plt.legend()
plt.title("Comparación de Distancia Euclidiana vs. Manhattan")
plt.grid()
plt.show()

3. Distancia coseno¶
La distancia coseno mide la diferencia angular entre dos vectores, en lugar de la distancia absoluta entre sus valores:
$d_{\text{Coseno}}(x_i, x_j) = 1 - \frac{x_i \cdot x_j}{||x_i||, ||x_j||}$
donde:
- ($x_i \cdot x_j$) es el producto punto entre los vectores
- ($||x_i||$) y ($||x_j||$) son sus normas euclidianas
Ventajas:
- Es muy útil en texto y datos de alta dimensión porque en esos casos suele importar más la composición relativa* del vector que su tamaño total.
- Ignora la magnitud y se enfoca en la dirección. Por eso, dos vectores se consideran parecidos si tienen proporciones similares entre sus componentes, aunque uno tenga valores más grandes que el otro.
*¿Por qué importa la composición relativa en texto? Porque en texto muchas veces interesa saber si dos documentos hablan de temas parecidos, no cuál es más largo. Por ejemplo, si dos documentos usan proporciones similares de palabras como "red", "modelo" y "datos", su contenido puede ser parecido aunque uno tenga 100 palabras y otro 1000. La distancia coseno captura esa similitud temática mejor que una distancia basada en magnitudes absolutas.
Desventajas:
- No considera la magnitud del vector, así que puede ser una mala elección si la intensidad, frecuencia total o tamaño sí son relevantes.
- No mide cercanía real en el espacio, sino similitud de orientación. Por eso puede ser menos adecuada cuando importa la distancia absoluta entre observaciones.
Ejemplo: Se usa mucho en análisis de texto, donde cada documento se representa como un vector TF-IDF. Dos documentos pueden tratar temas similares aunque uno sea mucho más extenso que el otro.
Recomendación: Es especialmente útil para datos textuales, embeddings y vectores dispersos, donde la dirección del vector suele ser más informativa que su magnitud.
from sklearn.metrics.pairwise import cosine_distances
cosine_dist = cosine_distances(X)
import numpy as np
from scipy.spatial.distance import cosine
# Definir los puntos
p1 = np.array([3, 4])
p2 = np.array([7, 1])
# Cálculo manual de la distancia del coseno
cosine_similarity = np.dot(p1, p2) / (np.linalg.norm(p1) * np.linalg.norm(p2))
cosine_distance = 1 - cosine_similarity # Distancia coseno
print(f"Similitud del Coseno: {cosine_similarity:.4f}")
print(f"Distancia del Coseno: {cosine_distance:.4f}")
# Usando scipy
dist_cosine_scipy = cosine(p1, p2)
print(f"Distancia del Coseno (scipy): {dist_cosine_scipy:.4f}")
4. Distancia de Mahalanobis¶
La distancia de Mahalanobis mide qué tan lejos están dos observaciones considerando no solo la escala de cada variable, sino también la correlación entre ellas:
$d_{\text{Mahalanobis}}(x_i, x_j) = \sqrt{(x_i - x_j)^T S^{-1} (x_i - x_j)}$
donde (S) es la matriz de covarianza de los datos.
Ventajas:
- Tiene en cuenta la correlación entre variables, por lo que no trata como independientes variables que en realidad se mueven juntas.
- Ajusta la distancia según la variabilidad de los datos: diferencias en direcciones muy frecuentes pesan menos, y diferencias en direcciones raras pesan más.
- Puede capturar clusters elípticos, porque la noción de cercanía se adapta a la forma real de la nube de datos y no solo a círculos o esferas.
¿Por qué importa la correlación? Porque en muchos datos una combinación de valores puede ser completamente normal si sigue el patrón habitual de covariación. Por ejemplo, si altura y peso están correlacionados, una persona alta y con mayor peso no necesariamente está “lejos” del resto. Euclidiana puede exagerar esa distancia; Mahalanobis la reduce si esa combinación es esperable en los datos.
Desventajas:
- Requiere estimar la matriz de covarianza, lo que puede ser inestable o costoso si hay muchas variables o pocos datos.
- Depende de que la covarianza esté bien estimada; si la estructura de correlación es débil, ruidosa o mal estimada, la distancia puede perder utilidad.
- Es más difícil de interpretar que Euclidiana, porque la distancia ya no depende solo de diferencias directas entre coordenadas.
Ejemplo: Se usa en detección de fraudes o anomalías, donde una observación puede parecer normal en cada variable por separado, pero extraña en su combinación con otras variables. Ejemplo, una transacción puede ser anómala no solo por su monto, sino por su relación con otras variables (ubicación, tipo de compra, frecuencia).
Recomendación: Es útil cuando las variables están correlacionadas y la nube de datos tiene una forma alargada o elíptica, no aproximadamente esférica.
```python id="gq3n1h" from scipy.spatial.distance import mahalanobis import numpy as np
Calcular la matriz de covarianza¶
cov_matrix = np.cov(X_scaled.T) inv_cov_matrix = np.linalg.inv(cov_matrix)
Calcular distancia de Mahalanobis entre dos puntos¶
dist = mahalanobis(X_scaled[0], X_scaled[1], inv_cov_matrix) ```
from scipy.spatial.distance import mahalanobis
import numpy as np
# Definir los puntos
p1 = np.array([3, 4])
p2 = np.array([7, 1])
# Crear matriz de datos (p1 y p2 como filas)
X = np.vstack([p1, p2])
# Calcular la matriz de covarianza
cov_matrix = np.cov(X.T)
# Usar la pseudoinversa en lugar de la inversa para evitar el error de matriz singular
inv_cov_matrix = np.linalg.pinv(cov_matrix)
# Cálculo de la distancia de Mahalanobis
dist_mahalanobis = mahalanobis(p1, p2, inv_cov_matrix)
print(f"Distancia de Mahalanobis: {dist_mahalanobis:.4f}")
### Ejemplo comparativo
import numpy as np
from scipy.spatial.distance import mahalanobis
# Datos correlacionados
X = np.array([
[40, 42],
[45, 46],
[50, 51],
[55, 54],
[60, 61]
])
# Centro aproximado
mu = X.mean(axis=0)
# Matriz de covarianza e inversa
S = np.cov(X.T)
S_inv = np.linalg.inv(S)
# Puntos a comparar
A = np.array([60, 60]) # sigue la correlación #por que este punto no se usa para calcular la matriz de covarianza? porque es un nuevo punto que queremos evaluar, no forma parte del conjunto de datos original
B = np.array([60, 40]) # rompe la correlación
# Distancias euclidianas
dE_A = np.linalg.norm(A - mu)
dE_B = np.linalg.norm(B - mu)
# Distancias Mahalanobis
dM_A = mahalanobis(A, mu, S_inv)
dM_B = mahalanobis(B, mu, S_inv)
print("Centro:", mu)
print("Euclidiana A:", dE_A)
print("Euclidiana B:", dE_B)
print("Mahalanobis A:", dM_A)
print("Mahalanobis B:", dM_B)
Interpretación¶
Para Euclidiana:
- A y B están a distancias relativamente parecidas
- B sale un poco más lejos, pero no muchísimo más
¿Por qué? Porque Euclidiana solo mira "cuánto se movió" el punto en términos geométricos, sin preguntarse si esa dirección es normal o rara dado el patrón de los datos.
Qué está diciendo Mahalanobis¶
Mahalanobis no solo mira tamaño del desplazamiento. También mira:
- la varianza en cada dirección
- la correlación entre variables
Eso significa que pregunta algo más sofisticado:
¿Este punto está lejos en una dirección que es habitual en los datos, o en una dirección que rompe el patrón?
Por qué A tiene Mahalanobis pequeña¶
El punto:
$A=(60,60)$
está por encima del promedio en ambas variables. Eso sigue la tendencia natural de los datos: cuando una sube, la otra también.
Entonces, aunque geométricamente A no esté pegado al centro, sí está en una dirección esperable dada la correlación.
Por eso:
$d_M(A,\mu)\approx 1.26$
que es una distancia pequeña.
A está lejos en sentido geométrico, pero no está lejos en sentido estadístico.
Por qué B tiene Mahalanobis enorme¶
El punto:
$B=(60,40)$
tiene primera variable alta, pero segunda variable baja.
Eso rompe completamente el patrón de los datos. Dado que las variables suelen crecer juntas, esta combinación es muy inusual.
Por eso Mahalanobis lo castiga fuertemente:
$d_M(B,\mu)\approx 22.40$
B no solo está desplazado: está desplazado en una dirección muy improbable según la estructura conjunta de los datos.
Entonces¶
- Euclidiana mide "qué tan lejos está"
- Mahalanobis mide "qué tan raro es estar ahí, dada la forma de la nube"
Por qué la diferencia es tan extrema¶
La nube de datos está muy alineada con una diagonal ascendente. Eso implica:
- moverse a lo largo de esa diagonal es relativamente normal
- moverse perpendicularmente a esa diagonal es raro
A está cerca de la diagonal de correlación. B está muy fuera de esa diagonal.
Entonces Mahalanobis hace algo parecido a esto:
- "premia" movimientos en la dirección natural de la nube
- "penaliza" movimientos transversales a esa estructura
A y B están a una distancia geométrica parecida del centro, por eso Euclidiana los ve como relativamente similares. Pero los datos muestran que ambas variables suelen aumentar juntas. A respeta ese patrón, B lo rompe. Mahalanobis incorpora esa información y por eso considera a B muchísimo más lejano. Es decir, Euclidiana mide distancia. Mahalanobis mide distancia corregida por la forma y correlación de los datos.
Conclusión¶
Este ejemplo muestra por qué Mahalanobis puede ser mejor cuando hay variables correlacionadas:
- no sobrecastiga combinaciones que siguen el patrón normal de covariación
- sí detecta como lejanas combinaciones atípicas, aunque Euclidiana no las vea tan extremas
Comparación de Distancias¶
| Distancia | Uso Ideal | Ventaja | Desventaja |
|---|---|---|---|
| Euclidiana | Clusters esféricos | Intuitiva y fácil de calcular | Sensible a la escala |
| Manhattan | Datos dispersos o en cuadrícula | Robusta a outliers | Puede no capturar relaciones geométricas |
| Coseno | Texto y datos de alta dimensión | Enfocada en similitud de dirección | No considera magnitud |
| Mahalanobis | Datos correlacionados y clusters elípticos | Ajusta por correlación | Computacionalmente costosa |
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs, make_moons, make_circles
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster
from scipy.spatial.distance import pdist
# Generar datasets con diferentes características
np.random.seed(42)
# Dataset 1: Blobs (clusters esféricos)
X1, y1 = make_blobs(n_samples=300, centers=3, cluster_std=1.0)
# Dataset 2: Moons (clusters en forma de media luna)
X2, y2 = make_moons(n_samples=300, noise=0.05)
# Dataset 3: Circles (clusters concéntricos)
X3, y3 = make_circles(n_samples=300, factor=0.5, noise=0.05)
# Lista de datasets para iterar
datasets = [(X1, y1, "Blobs"), (X2, y2, "Moons"), (X3, y3, "Circles")]
# Métricas de distancia a comparar
metrics = ['euclidean', 'cityblock', 'cosine', 'mahalanobis']
# Métodos de linkage a utilizar
linkage_methods = ['single'] # Puedes añadir 'complete', 'average' si lo deseas
# Función para encontrar el corte óptimo usando el método del codo
def find_optimal_cutoff(Z):
#La idea detrás de este método es encontrar el punto en el dendrograma donde la distancia de
#fusión aumenta drásticamente, lo que indica que los clusters restantes son demasiado disímiles
#para ser fusionados sin pérdida de información.
#El número óptimo de clusters está justo antes de este gran salto en la distancia de fusión.
# Obtener las últimas 10 distancias de fusión/unión, que corresponden a las fusiones más grandes (las últimas uniones de clusters).
last = Z[-10:, 2]
# Invertir el orden de las distancias
last_rev = last[::-1]
# Crear un array de índices
idxs = np.arange(1, len(last) + 1)
# Se calcula la segunda derivada discreta de las distancias para medir la variación en la tasa de cambio.
# La segunda derivada mide la "curvatura" de la función de distancia de fusión y ayuda a detectar un punto de inflexión (donde la tasa de cambio es máxima).
acceleration = np.diff(last, 2)
# Invertir el orden de la aceleración
acceleration_rev = acceleration[::-1]
# Encontrar el índice de la máxima aceleración
k = acceleration_rev.argmax() + 2 # Si el índice es 0, necesitamos 2 clusters
# Devolver la distancia en el punto de corte óptimo
return Z[-k, 2]
# Función para aplicar clustering jerárquico y visualizar los dendrogramas
def plot_dendrograms(X, dataset_name, ax, metric, method, cutoff):
# Aplicar el clustering jerárquico
Z = linkage(X, method=method, metric=metric)
# Dibujar el dendrograma
dendrogram(Z, ax=ax, truncate_mode='level', p=5)
# Añadir una línea horizontal en el punto de corte
ax.axhline(y=cutoff, c='r', linestyle='--')
# Establecer el título del subplot
ax.set_title(f'{dataset_name} - {metric.capitalize()} - {method.capitalize()}')
# Función para aplicar clustering jerárquico y visualizar los clusters
def plot_clusters(X, dataset_name, ax, metric, method, cutoff):
# Aplicar el clustering jerárquico
Z = linkage(X, method=method, metric=metric)
# Formar clusters cortando el dendrograma en la distancia de corte
clusters = fcluster(Z, t=cutoff, criterion='distance')
# Dibujar un scatter plot de los datos, coloreando los puntos según los clusters formados
ax.scatter(X[:, 0], X[:, 1], c=clusters, cmap='viridis', marker='.')
# Establecer el título del subplot
ax.set_title(f'{dataset_name} - {metric.capitalize()} - {method.capitalize()} Clusters')
# Crear una figura con subplots para comparar las métricas
fig, axs = plt.subplots(len(datasets) * 2, len(metrics) * len(linkage_methods) + 1, figsize=(30, 30))
# Iterar sobre los datasets
for i, (X, y, dataset_name) in enumerate(datasets):
# Plot de los datos originales con sus etiquetas verdaderas
ax = axs[i * 2, 0]
scatter = ax.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', marker='.')
ax.set_title(f'{dataset_name} - Ground Truth')
# Iterar sobre las métricas de distancia
for j, metric in enumerate(metrics):
# Iterar sobre los métodos de linkage
for k, method in enumerate(linkage_methods):
# Aplicar el clustering jerárquico
Z = linkage(X, method=method, metric=metric)
# Encontrar el corte óptimo
cutoff = find_optimal_cutoff(Z)
# Dibujar el dendrograma con el corte óptimo
plot_dendrograms(X, dataset_name, axs[i * 2, j * len(linkage_methods) + k + 1], metric, method, cutoff)
# Dibujar los clusters formados con el corte óptimo
plot_clusters(X, dataset_name, axs[i * 2 + 1, j * len(linkage_methods) + k + 1], metric, method, cutoff)
# Ajustar el espaciado entre subplots para que no se solapen
plt.tight_layout()
# Mostrar la figura
plt.show()

Nota: Se eligió el corte en la altura del dendrograma justo antes del mayor salto en las distancias de fusión, detectado mediante la máxima segunda diferencia de las últimas uniones, como una versión automática del método del codo.
¿Qué aprendimos?
- Cada métrica de distancia tiene ventajas y desventajas dependiendo del tipo de datos y la estructura de los clusters.
- Euclidiana es la más común, pero puede fallar en datos con escalas distintas.
- Manhattan es robusta a outliers.
- Coseno es útil en texto y NLP.
- Mahalanobis es ideal en datos correlacionados pero costosa computacionalmente.
Ejemplo: Comparamos distiancias en el dataset IRIS¶
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.spatial.distance import euclidean, cityblock, cosine, mahalanobis
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
# Cargar el dataset Iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# Seleccionar solo dos características para visualizar en 2D
X = df.iloc[:, [0, 1]].values # Longitud y ancho del sépalo
# Seleccionar dos puntos aleatorios del dataset
np.random.seed(42)
idx = np.random.choice(len(X), 2, replace=False)
p1, p2 = X[idx[0]], X[idx[1]]
# Calcular distancias
dist_euclidiana = euclidean(p1, p2)
dist_manhattan = cityblock(p1, p2)
dist_coseno = cosine(p1, p2)
# Calcular matriz de covarianza para Mahalanobis
cov_matrix = np.cov(X.T)
inv_cov_matrix = np.linalg.pinv(cov_matrix) # Usamos pseudoinversa
dist_mahalanobis = mahalanobis(p1, p2, inv_cov_matrix)
# Imprimir resultados
print(f"Distancia Euclidiana: {dist_euclidiana:.4f}")
print(f"Distancia Manhattan: {dist_manhattan:.4f}")
print(f"Distancia del Coseno: {dist_coseno:.4f}")
print(f"Distancia de Mahalanobis: {dist_mahalanobis:.4f}")
plt.figure(figsize=(7, 7))
# Graficar puntos del dataset
sns.scatterplot(x=X[:, 0], y=X[:, 1], alpha=0.5, label="Datos Iris", color="gray")
# Graficar puntos seleccionados
plt.scatter(*p1, color='blue', label="Punto 1", s=150, edgecolor='black')
plt.scatter(*p2, color='red', label="Punto 2", s=150, edgecolor='black')
# Línea de Distancia Euclidiana
plt.plot([p1[0], p2[0]], [p1[1], p2[1]], 'g-', label="Euclidiana", linewidth=2)
# Líneas de Distancia Manhattan (movimiento ortogonal)
plt.plot([p1[0], p1[0]], [p1[1], p2[1]], 'r--', linewidth=2)
plt.plot([p1[0], p2[0]], [p2[1], p2[1]], 'r--', linewidth=2, label="Manhattan")
plt.xlabel("Longitud del Sépalo (cm)")
plt.ylabel("Ancho del Sépalo (cm)")
plt.title(f"Comparación de Distancias en el Dataset Iris\nCoseno={dist_coseno:.4f}, Mahalanobis={dist_mahalanobis:.4f}")
plt.legend()
plt.grid()
plt.show()

import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import cosine
# # Seleccionar dos puntos aleatorios del dataset Iris
# p1 = np.array([5.1, 3.5]) # Flor A
# p2 = np.array([7.9, 4.2]) # Flor B
# Calcular distancia del coseno
dist_coseno = cosine(p1, p2)
# Visualización de los vectores en 2D
plt.figure(figsize=(7, 7))
plt.quiver(0, 0, p1[0], p1[1], angles='xy', scale_units='xy', scale=1, color='blue', label="Flor A")
plt.quiver(0, 0, p2[0], p2[1], angles='xy', scale_units='xy', scale=1, color='red', label="Flor B")
# Ángulo entre los vectores
theta = np.arccos(np.dot(p1, p2) / (np.linalg.norm(p1) * np.linalg.norm(p2))) # Ángulo en radianes
theta_deg = np.degrees(theta) # Convertir a grados
plt.xlim(0, max(p1[0], p2[0]) + 2)
plt.ylim(0, max(p1[1], p2[1]) + 2)
plt.title(f"Distancia del Coseno: {dist_coseno:.4f}\nÁngulo entre vectores: {theta_deg:.2f}°")
plt.legend()
plt.grid()
plt.show()

¿Qué significa en el contexto de Iris?
- Si dos flores tienen formas similares (relación entre la longitud y el ancho del sépalo/pétalo es parecida), la distancia del Coseno será baja, indicando alta similitud direccional.
- Si dos flores tienen proporciones muy diferentes, la distancia del Coseno será alta, indicando que pertenecen a especies distintas.
La elipse en la distancia de Mahalanobis¶
Con distancia euclidiana, los puntos que están a la misma distancia del centro forman un círculo (o una esfera en dimensiones mayores). Eso funciona bien cuando la nube de datos es aproximadamente redonda y no hay una estructura especial entre variables.
Pero en datos reales eso muchas veces no ocurre. Puede pasar que:
- una variable tenga más variabilidad que otra
- dos variables estén correlacionadas
- la nube de puntos esté alargada e inclinada
En esos casos, la región de puntos “igualmente típicos” alrededor del centro ya no se parece a un círculo, sino a una elipse.
La elipse resume la estructura de los datos:
- su centro corresponde a la media
- su orientación depende de la correlación entre variables
- su ancho y alto dependen de cuánta variabilidad hay en cada dirección
La idea central de Mahalanobis es esta:
no solo importa qué tan lejos está un punto, sino también en qué dirección se aleja.
Si un punto se mueve en una dirección donde los datos naturalmente se dispersan mucho, esa desviación se penaliza menos. Si se mueve en una dirección poco habitual, se penaliza más.
En la figura:
- los puntos muestran las observaciones
- la elipse representa una curva de igual distancia de Mahalanobis respecto del centro
- los puntos destacados son los que estamos comparando
La lectura correcta no es solo preguntar si un punto está lejos del centro, sino también:
- ¿está lejos siguiendo la forma natural de la nube?
- ¿o está lejos en una dirección rara para esos datos?
Moverse a lo largo del eje largo de la elipse es más esperable.
Moverse cruzando la elipse es menos esperable.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.spatial.distance import mahalanobis
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from matplotlib.patches import Ellipse
# Cargar dataset Iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# Seleccionar solo dos características para visualizar en 2D
X = df.iloc[:, [0, 1]].values # Longitud y ancho del sépalo
# Normalizar los datos
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Seleccionar dos puntos aleatorios del dataset
np.random.seed(42)
idx = np.random.choice(len(X_scaled), 2, replace=False)
p1, p2 = X_scaled[idx[0]], X_scaled[idx[1]]
# Calcular la matriz de covarianza e inversa
cov_matrix = np.cov(X_scaled.T) # Calculamos la matriz de covarianza de los datos escalados
inv_cov_matrix = np.linalg.pinv(cov_matrix) # Usamos pseudoinversa para evitar problemas de matriz singular
# Calcular distancia de Mahalanobis entre los puntos seleccionados
dist_mahalanobis = mahalanobis(p1, p2, inv_cov_matrix) # Por que si p1 y p2 son nuestros puntos a comparar, no los sacamos del cálculo de la matriz de covarianza? Porque la matriz de covarianza se calcula a partir de todos los datos, incluyendo p1 y p2. Si excluimos p1 y p2 del cálculo de la matriz de covarianza, estaríamos utilizando una matriz que no refleja completamente la distribución de los datos, lo que podría llevar a una estimación inexacta de la distancia de Mahalanobis. Al incluir p1 y p2 en el cálculo de la matriz de covarianza, aseguramos que esta matriz capture la variabilidad y correlación presentes en todo el conjunto de datos, lo que resulta en una medida más precisa de la distancia entre p1 y p2.
print(f"Distancia de Mahalanobis entre p1 y p2: {dist_mahalanobis:.4f}")
# ---- Visualización Mejorada ----
plt.figure(figsize=(8, 6))
# Graficar todos los puntos del dataset en gris con mayor tamaño
sns.scatterplot(x=X_scaled[:, 0], y=X_scaled[:, 1], alpha=0.5, label="Datos Iris", color="gray", s=50)
# Graficar los puntos seleccionados con mejor contraste
plt.scatter(*p1, color='blue', label="Punto 1", s=200, edgecolor='black', linewidth=2)
plt.scatter(*p2, color='red', label="Punto 2", s=200, edgecolor='black', linewidth=2)
# Función para dibujar elipse de Mahalanobis con solo contorno
def plot_cov_ellipse(cov, pos, nstd=2, ax=None, **kwargs):
"""
Dibuja una elipse de confianza basada en la matriz de covarianza.
- `cov`: Matriz de covarianza.
- `pos`: Centro de la elipse (media de los datos).
- `nstd`: Número de desviaciones estándar para el tamaño de la elipse.
"""
if ax is None:
ax = plt.gca()
# Autovalores y autovectores de la covarianza
eigvals, eigvecs = np.linalg.eigh(cov)
order = eigvals.argsort()[::-1]
eigvals, eigvecs = eigvals[order], eigvecs[:, order]
# Ángulo de rotación de la elipse
angle = np.degrees(np.arctan2(*eigvecs[:, 0][::-1]))
# Ancho y alto de la elipse (ajustado por el número de desviaciones estándar)
width, height = 2 * nstd * np.sqrt(eigvals)
# Crear la elipse
ellip = Ellipse(xy=pos, width=width, height=height, angle=angle, **kwargs)
ax.add_patch(ellip)
# Dibujar elipse de confianza con solo contorno y sin relleno
plot_cov_ellipse(cov_matrix, np.mean(X_scaled, axis=0), nstd=1.5, ax=plt.gca(),
edgecolor='purple', linestyle='--', linewidth=2, label="Elipse Mahalanobis (1.5σ)", fill=False)
# Configuración del gráfico mejorada
plt.xlabel("Longitud del Sépalo (normalizado)")
plt.ylabel("Ancho del Sépalo (normalizado)")
plt.title(f"Distancia de Mahalanobis en Iris: {dist_mahalanobis:.4f}")
plt.legend()
plt.grid()
plt.show()

Interpretación¶
En este gráfico, cada punto gris representa una flor del dataset Iris usando dos variables: longitud del sépalo y ancho del sépalo, ambas previamente normalizadas. Los dos puntos destacados (azul y rojo) son dos observaciones seleccionadas al azar cuya distancia de Mahalanobis queremos interpretar.
¿Qué representa la elipse morada?¶
La elipse morada resume la estructura global de dispersión de los datos:
- su centro está en la media del dataset
- su orientación depende de la correlación entre las dos variables
- su ancho y alto reflejan cuánta variabilidad hay en cada dirección
En otras palabras, la elipse muestra la forma típica de la nube de datos. No es una frontera de clasificación ni un cluster, sino una curva de igual distancia de Mahalanobis respecto del centro.
¿Qué nos dice la distancia de Mahalanobis entre los puntos?¶
La distancia de Mahalanobis entre los puntos azul y rojo es aproximadamente 2.30. Esta distancia no debe interpretarse como una simple distancia en línea recta, sino como una distancia ajustada por la covarianza de los datos.
Eso significa que Mahalanobis no solo considera cuánto se separan dos puntos, sino también en qué dirección ocurre esa separación:
- si dos puntos se separan en una dirección donde los datos suelen variar mucho, la distancia se penaliza menos
- si se separan en una dirección poco habitual, la distancia se penaliza más
¿Cómo leer este gráfico en particular?¶
En esta figura, la nube de datos tiene una forma aproximadamente elíptica y algo inclinada. Eso indica que la variabilidad no es igual en todas las direcciones. Por lo tanto, no basta con mirar visualmente qué tan lejos están dos puntos: también importa si esa separación sigue o no la forma natural de la nube.
La interpretación correcta es entonces:
la distancia de Mahalanobis entre el punto azul y el rojo mide qué tan separados están considerando la geometría estadística del conjunto de datos, no solo su distancia geométrica directa.
Idea clave¶
Con distancia euclidiana, los puntos igualmente lejanos al centro formarían círculos.
Con distancia de Mahalanobis, los puntos igualmente lejanos al centro forman elipses, porque la métrica incorpora la varianza y la correlación entre variables.
Conclusión¶
Este gráfico muestra que Mahalanobis es útil cuando queremos medir distancias en datos donde las variables:
- tienen distinta dispersión
- pueden estar correlacionadas
- generan nubes de puntos no esféricas
Por eso, Mahalanobis es más adecuada que Euclidiana cuando la idea de “lejos” debe entenderse relativa a la estructura del dataset.
Ahora vamos a dibujar dos elipses, una para Setosa y otra para Versicolor. Cada elipse resume la media, la dispersión y la correlación de esa especie. La idea es mostrar que la distancia de Mahalanobis no depende solo del punto, sino también de qué población tomamos como referencia.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.spatial.distance import mahalanobis
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from matplotlib.patches import Ellipse
# ============================================================
# 1. Cargar datos
# ============================================================
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df["species"] = iris.target
df["species_name"] = df["species"].map({0: "Setosa", 1: "Versicolor", 2: "Virginica"})# el metodo map permite asignar un valor a cada categoria de la columna "species" y crear una nueva columna "species_name" con los nombres correspondientes a cada especie. En este caso, se asigna "Setosa" a la categoría 0, "Versicolor" a la categoría 1 y "Virginica" a la categoría 2.
# Usaremos pétalos, porque separan mejor las especies
X = df.iloc[:, [2, 3]].values # petal length, petal width # seleccionamos las columnas 2 y 3 del dataset, que corresponden a la longitud y ancho del pétalo respectivamente, y las almacenamos en la variable X para su posterior análisis.
# Estandarizar
scaler = StandardScaler() # Inicializamos el escalador
X_scaled = scaler.fit_transform(X) # Ajustamos el escalador a los datos y transformamos X para obtener X_scaled, que contiene las características estandarizadas (con media 0 y desviación estándar 1) de la longitud y ancho del pétalo. Esto es importante para que las diferentes escalas de las características no afecten el cálculo de distancias como la de Mahalanobis.
# Separar datos por especie
X_setosa = X_scaled[df["species"] == 0] # seleccionamos las filas de X_scaled donde la columna "species" es igual a 0 (correspondiente a la especie Setosa) y las almacenamos en la variable X_setosa.
X_versicolor = X_scaled[df["species"] == 1]
X_virginica = X_scaled[df["species"] == 2]
# Elegir un punto de cada especie
p_setosa = X_setosa[0] # seleccionamos el primer punto de la especie Setosa para usarlo como referencia en el cálculo de distancias.
p_versicolor = X_versicolor[0] # seleccionamos el primer punto de la especie Versicolor para usarlo como referencia en el cálculo de distancias.
# ============================================================
# 2. Medias y covarianzas por especie
# ============================================================
mu_setosa = X_setosa.mean(axis=0) # calculamos la media de cada característica (longitud y ancho del pétalo) para la especie Setosa, lo que nos da el centroide de esta especie en el espacio de características estandarizadas.
mu_versicolor = X_versicolor.mean(axis=0) # calculamos la media de cada característica (longitud y ancho del pétalo) para la especie Versicolor, lo que nos da el centroide de esta especie en el espacio de características estandarizadas.
cov_setosa = np.cov(X_setosa.T) # calculamos la matriz de covarianza para la especie Setosa utilizando np.cov, que toma la transpuesta de X_setosa para calcular la covarianza entre las características (longitud y ancho del pétalo) de esta especie.
cov_versicolor = np.cov(X_versicolor.T) # calculamos la matriz de covarianza para la especie Versicolor utilizando np.cov, que toma la transpuesta de X_versicolor para calcular la covarianza entre las características (longitud y ancho del pétalo) de esta especie.
inv_cov_setosa = np.linalg.pinv(cov_setosa) # calculamos la pseudoinversa de la matriz de covarianza de Setosa utilizando np.linalg.pinv, lo que nos permite manejar casos donde la matriz de covarianza pueda ser singular o no invertible, y es necesario para el cálculo de la distancia de Mahalanobis.
inv_cov_versicolor = np.linalg.pinv(cov_versicolor) # calculamos la pseudoinversa de la matriz de covarianza de Versicolor utilizando np.linalg.pinv, lo que nos permite manejar casos donde la matriz de covarianza pueda ser singular o no invertible, y es necesario para el cálculo de la distancia de Mahalanobis.
# que es la pseudoinversa: La pseudoinversa de una matriz es una generalización de la inversa que se utiliza para matrices que no son cuadradas o que son singulares (es decir, no tienen inversa). En el contexto de la distancia de Mahalanobis, la pseudoinversa se emplea para calcular la distancia cuando la matriz de covarianza no es invertible, lo que puede ocurrir si las características están altamente correlacionadas o si hay más características que muestras. La función np.linalg.pinv calcula esta pseudoinversa de manera eficiente, permitiendo así el uso de la distancia de Mahalanobis incluso en situaciones donde la matriz de covarianza no es invertible.
# Distancias de cada punto respecto de cada especie
d_setosa_to_setosa = mahalanobis(p_setosa, mu_setosa, inv_cov_setosa) # calculamos la distancia de Mahalanobis desde el punto seleccionado de Setosa (p_setosa) hasta el centroide de Setosa (mu_setosa) utilizando la pseudoinversa de la matriz de covarianza de Setosa (inv_cov_setosa). Esta distancia nos indica qué tan lejos está el punto p_setosa del centroide de su propia especie, teniendo en cuenta la variabilidad de los datos.
d_setosa_to_versicolor = mahalanobis(p_setosa, mu_versicolor, inv_cov_versicolor) # calculamos la distancia de Mahalanobis desde el punto seleccionado de Setosa (p_setosa) hasta el centroide de Versicolor (mu_versicolor) utilizando la pseudoinversa de la matriz de covarianza de Versicolor (inv_cov_versicolor). Esta distancia nos indica qué tan lejos está el punto p_setosa del centroide de la especie Versicolor, teniendo en cuenta la variabilidad de los datos.
d_versicolor_to_setosa = mahalanobis(p_versicolor, mu_setosa, inv_cov_setosa) # calculamos la distancia de Mahalanobis desde el punto seleccionado de Versicolor (p_versicolor) hasta el centroide de Setosa (mu_setosa) utilizando la pseudoinversa de la matriz de covarianza de Setosa (inv_cov_setosa). Esta distancia nos indica qué tan lejos está el punto p_versicolor del centroide de la especie Setosa, teniendo en cuenta la variabilidad de los datos.
d_versicolor_to_versicolor = mahalanobis(p_versicolor, mu_versicolor, inv_cov_versicolor)
print("Punto Setosa:")
print(f" Distancia al centro de Setosa: {d_setosa_to_setosa:.4f}")
print(f" Distancia al centro de Versicolor: {d_setosa_to_versicolor:.4f}")
print("\nPunto Versicolor:")
print(f" Distancia al centro de Setosa: {d_versicolor_to_setosa:.4f}")
print(f" Distancia al centro de Versicolor: {d_versicolor_to_versicolor:.4f}")
# ============================================================
# 3. Función para dibujar elipse de covarianza
# ============================================================
def plot_cov_ellipse(cov, pos, nstd=2, ax=None, **kwargs):
if ax is None:
ax = plt.gca()
eigvals, eigvecs = np.linalg.eigh(cov)
order = eigvals.argsort()[::-1]
eigvals = eigvals[order]
eigvecs = eigvecs[:, order]
angle = np.degrees(np.arctan2(*eigvecs[:, 0][::-1]))
width, height = 2 * nstd * np.sqrt(eigvals)
ellip = Ellipse(xy=pos, width=width, height=height, angle=angle, **kwargs)
ax.add_patch(ellip)
# ============================================================
# 4. Visualización
# ============================================================
plt.figure(figsize=(10, 8))
# Scatter de todos los datos
sns.scatterplot(
x=X_scaled[:, 0],
y=X_scaled[:, 1],
hue=df["species_name"],
alpha=0.55,
s=60
)
# Puntos destacados
plt.scatter(*p_setosa, color="blue", s=240, edgecolor="black", linewidth=2, zorder=5, label="Punto Setosa")
plt.scatter(*p_versicolor, color="red", s=240, edgecolor="black", linewidth=2, zorder=5, label="Punto Versicolor")
# Centros
plt.scatter(*mu_setosa, color="blue", marker="X", s=260, edgecolor="black", linewidth=2, zorder=6, label="Centro Setosa")
plt.scatter(*mu_versicolor, color="red", marker="X", s=260, edgecolor="black", linewidth=2, zorder=6, label="Centro Versicolor")
# Elipses
plot_cov_ellipse(
cov_setosa, mu_setosa, nstd=1.5, ax=plt.gca(),
edgecolor="blue", linestyle="--", linewidth=2.5, fill=False
)
plot_cov_ellipse(
cov_versicolor, mu_versicolor, nstd=1.5, ax=plt.gca(),
edgecolor="red", linestyle="--", linewidth=2.5, fill=False
)
# Etiquetas
plt.xlabel("Longitud del Pétalo (normalizado)")
plt.ylabel("Ancho del Pétalo (normalizado)")
plt.title("Mahalanobis con dos poblaciones de referencia: Setosa y Versicolor")
plt.grid(True)
plt.legend()
plt.show()

Interpretación¶
En este gráfico, cada elipse representa la estructura estadística de una especie distinta:
- su centro corresponde a la media de esa especie
- su forma y orientación dependen de su matriz de covarianza
- su tamaño indica cuánta variabilidad hay en cada dirección
La idea central es que la distancia de Mahalanobis siempre depende de la población de referencia.
Por eso, un mismo punto puede ser:
- cercano al centro de su propia especie
- lejano al centro de otra especie
Esto ocurre porque Mahalanobis no mide solo distancia geométrica, sino distancia ajustada por la forma de la nube de datos.
En otras palabras:
- con distancia euclidiana, igual distancia al centro genera círculos
- con distancia de Mahalanobis, igual distancia al centro genera elipses
La interpretación correcta del gráfico es entonces:
no preguntamos solo qué tan lejos está un punto, sino qué tan típico o atípico es respecto de cada especie.
Así, las dos elipses muestran que la noción de “estar cerca” cambia según la media, la dispersión y la correlación de la población que usamos como referencia.
Comparación de Distancias en el Dataset Iris¶
| Métrica | Qué mide | Cuándo usarla en Iris |
|---|---|---|
| Euclidiana | Distancia en línea recta | Para comparar tamaños absolutos de sépalos/pétalos |
| Manhattan | Distancia en ejes ortogonales | Para evitar el impacto de valores extremos |
| Coseno | Diferencia en dirección (proporciones) | Para comparar la forma relativa de los sépalos/pétalos |
| Mahalanobis | Distancia ajustada por la distribución | Para detectar anomalías y diferencias estadísticas |
¿Qué aprendimos en este dataset?
- Euclidiana y Manhattan muestran diferencias geométricas entre los puntos.
- Coseno muestra la diferencia de dirección en vez de la distancia absoluta.
- Mahalanobis toma en cuenta la distribución de los datos y la varianza en las dimensiones.
Recomendación¶
Si los datos son tabulares numéricos escalados: parte con Euclidiana¶
Si hay outliers o quieres robustez: prueba Manhattan¶
Si trabajas con texto o embeddings: prueba Coseno¶
Si la correlación entre variables es central: considera Mahalanobis¶
Métodos de Vinculación (Linkage)¶
Los métodos de vinculación determinan cómo se mide la distancia entre clusters:
### Vinculación Completa (Complete Linkage): En este método, la distancia entre dos clusters se define como la distancia máxima entre cualquier par de puntos, donde cada punto pertenece a uno de los clusters. Es decir, se considera la distancia entre los puntos más alejados de los dos clusters. Este enfoque tiende a producir clusters más compactos y es sensible a los outliers, ya que un solo punto distante puede aumentar significativamente la distancia entre los clusters.
$d(C_i, C_j) = \max \{ d(x_a, x_b) \mid x_a \in C_i, x_b \in C_j \}$
- Tiende a generar clusters compactos.
### Vinculación Simple (Single Linkage): En este método, la distancia entre dos clusters se define como la distancia mínima entre cualquier par de puntos, donde cada punto pertenece a uno de los clusters. Es decir, se considera la distancia entre los puntos más cercanos de los dos clusters. Este enfoque puede producir clusters alargados o encadenados, ya que solo se necesita un par de puntos cercanos para fusionar dos clusters, lo que puede resultar en la formación de clusters con formas irregulares. Además, es sensible a los outliers, ya que un solo punto distante puede causar que dos clusters se fusionen prematuramente.
$d(C_i, C_j) = \min \{ d(x_a, x_b) \mid x_a \in C_i, x_b \in C_j \}$
- Puede formar clusters alargados y con forma de cadena.
### Vinculación Promedio (Average Linkage): En este método, la distancia entre dos clusters se define como la distancia promedio entre todos los pares de puntos, donde cada par de puntos consiste en un punto de cada cluster. Es decir, se calcula la distancia entre cada punto de un cluster y cada punto del otro cluster, y luego se promedia esa distancia. Este enfoque tiende a producir clusters más equilibrados y es menos sensible a los outliers en comparación con la vinculación completa, ya que se basa en la distancia promedio en lugar de la distancia máxima o mínima.
$d(C_i, C_j) = \frac{1}{|C_i||C_j|} \sum_{x_a \in C_i} \sum_{x_b \in C_j} d(x_a, x_b)$
- Proporciona una solución intermedia entre los métodos anteriores.
### Vinculación de Centroides (Centroid Linkage): En este método, la distancia entre dos clusters se define como la distancia entre los centroides de los clusters. El centroide de un cluster es el punto que representa el promedio de las coordenadas de todos los puntos en ese cluster. Para fusionar dos clusters, se calcula el centroide de cada cluster y luego se mide la distancia entre estos dos centroides. Este enfoque puede producir clusters más compactos y es menos sensible a los outliers en comparación con la vinculación completa o simple, ya que se basa en la posición central de los clusters en lugar de las distancias extremas entre puntos individuales. Sin embargo, puede ser sensible a la forma de los clusters, ya que si los clusters tienen formas muy diferentes, el centroide puede no representar adecuadamente la estructura del cluster.
$d(C_i, C_j) = ||\mu_i - \mu_j||^2$
- Puede dar resultados inconsistentes en algunos casos.
### Método de Ward (Ward’s Method): En este método, la distancia entre dos clusters se define como el aumento en la suma de los cuadrados dentro del cluster (inertia) que resultaría de fusionar los dos clusters. Es decir, se calcula la suma de los cuadrados de las distancias de cada punto a su centroide dentro de cada cluster, y luego se mide cuánto aumentaría esta suma si se fusionaran los dos clusters. Este enfoque tiende a producir clusters más compactos y es menos sensible a los outliers en comparación con otros métodos de vinculación, ya que se basa en la minimización de la varianza dentro de los clusters. Sin embargo, puede ser computacionalmente más costoso que otros métodos, especialmente para conjuntos de datos grandes, debido a la necesidad de calcular la suma de los cuadrados para cada posible fusión de clusters.
$d(C_i, C_j) = \sum_{x \in C_i \cup C_j} ||x - \mu_{C_i \cup C_j}||^2 - \sum_{x \in C_i} ||x - \mu_{C_i}||^2 - \sum_{x \in C_j} ||x - \mu_{C_j}||^2$
El método de Ward que busca minimizar la varianza intracluster en cada paso de fusión de clusters. Su función de distancia está definida como por la ecuación anterior, donde:
- $ C_i $ y $ C_j $ son dos clusters candidatos a fusionarse.
- $ x $ representa cada punto en los clusters.
- $ \mu_{C} $ es el centroide del cluster $ C $.
- $ ||x - \mu_C||^2 $ es la distancia cuadrática euclidiana entre un punto $ x $ y el centroide del cluster al que pertenece.
Paso a paso de la ecuación del método de Ward¶
Primer término:
$\sum_{x \in C_i \cup C_j} ||x - \mu_{C_i \cup C_j}||^2$
Representa la suma de las distancias cuadráticas entre cada punto y el centroide del nuevo cluster después de la fusión de $ C_i $ y $ C_j $.
Esencialmente, mide la dispersión dentro del cluster resultante.
- Segundo y tercer término:
$\sum_{x \in C_i} ||x - \mu_{C_i}||^2 + \sum_{x \in C_j} ||x - \mu_{C_j}||^2$
Representan la suma de las distancias cuadráticas dentro de los clusters $ C_i $ y $ C_j $ antes de la fusión.
- Diferencia entre los términos:
La ecuación calcula el incremento en la varianza al fusionar los clusters.
En cada iteración del algoritmo, se elige la fusión que minimiza este incremento.
Intuición del método de Ward
- Busca minimizar el aumento de la varianza intracluster en cada fusión.
- Favorece la fusión de clusters que son compactos y cercanos entre sí.
- Tiende a generar clusters de tamaño balanceado, a diferencia de otros métodos como single linkage (que puede generar clusters alargados) o complete linkage (que prioriza la distancia máxima entre puntos).
- Es el método predeterminado en muchas implementaciones de clustering jerárquico.
El método de Ward es un criterio de fusión que minimiza el incremento de varianza, garantizando clusters compactos y equilibrados. Es particularmente útil cuando se espera que los datos formen grupos esféricos y de tamaño similar.
Nota: Relación con la Inercia¶
- La inercia es la suma de las distancias cuadráticas de los puntos al centroide de su cluster.
- El método de Ward es equivalente a minimizar la inercia en cada paso, similar a cómo lo hace el algoritmo K-Means.
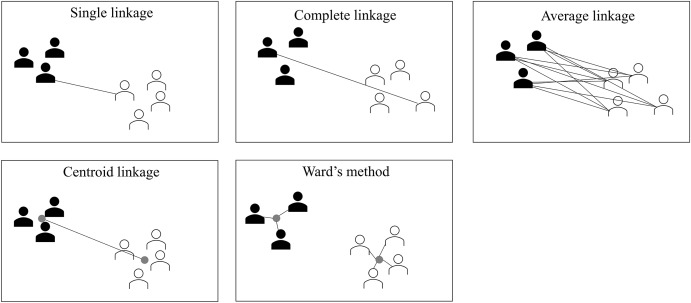
Construcción del Dendrograma¶
El dendrograma es una representación gráfica que muestra el orden en que se fusionan los clusters.
Cómo interpretarlo:
- El eje X representa las observaciones.
- El eje Y representa la distancia o disimilitud entre clusters.
- Los cortes horizontales indican la fusión de clusters.
Para definir el número de clusters, se corta el dendrograma a una altura específica.
Elección del número de clusters¶
Un criterio común es cortar el dendrograma en un nivel donde haya una gran diferencia de altura entre fusiones sucesivas.
Comparación con K-Means¶
| Característica | K-Means | Clustering Jerárquico |
|---|---|---|
| Número de clusters | Debe definirse antes | Se determina desde el dendrograma |
| Estructura de los clusters | Tiende a formar clusters esféricos | No supone ninguna forma específica |
| Escalabilidad | Eficiente para grandes datasets | Costoso en memoria para grandes $n$ |
| Robustez ante outliers | Sensible a outliers | Más robusto (depende del método de linkage) |
Reflexión Final¶
¿Qué aprendimos?
- Clustering jerárquico no requiere definir el número de clusters de antemano.
- Se basa en fusionar o dividir grupos usando distintas métricas de similitud.
- El dendrograma es una herramienta poderosa para visualizar relaciones en los datos.
- Comparado con K-Means, ofrece más flexibilidad, pero puede ser computacionalmente costoso.
En la siguiente sesión, exploraremos dos técnicas más de evaluación de clustering.
Evaluación de la Calidad del Clustering: Davies-Bouldin y Calinski-Harabasz¶
Cuando realizamos un clustering, es fundamental evaluar la calidad de los grupos formados. Existen varias métricas para esto, y dos de las más utilizadas son:
- Índice de Davies-Bouldin (DBI)
- Índice de Calinski-Harabasz (CHI)
Ambos métodos miden la compacidad y separación de los clusters, pero desde enfoques diferentes.
1. Índice de Davies-Bouldin (DBI)¶
Definición¶
El índice de Davies-Bouldin (DBI) mide la relación entre la dispersión interna de los clusters y la distancia entre ellos. Se define como:
$DBI = \frac{1}{k} \sum_{i=1}^{k} \max_{j \neq i} R_{i,j}$
donde:
$R_{i,j} = \frac{s_i + s_j}{d_{i,j}}$
- $ k $ es el número de clusters.
- $ s_i $ es la dispersión del cluster $ i $ (promedio de las distancias de los puntos al centroide del cluster).
- $ d_{i,j} $ es la distancia entre los centroides de los clusters $ i $ y $ j $.
- $ R_{i,j} $ mide la similaridad entre los clusters $ i $ y $ j $, y se toma el valor máximo para cada cluster $ i $.
Interpretación¶
- Valores bajos de DBI → Mejor separación entre clusters y menor dispersión interna (clustering más definido).
- Valores altos de DBI → Clusters solapados y menos diferenciados.
2. Índice de Calinski-Harabasz (CHI)¶
Definición¶
El Índice de Calinski-Harabasz (CHI) mide la separación entre clusters en relación con la compacidad dentro de cada cluster. Se utiliza para evaluar la calidad del clustering, y se busca maximizar este índice, ya que valores más altos indican una mejor separación entre clusters.
Definición Matemática¶
El índice de Calinski-Harabasz se define como:
$CHI = \frac{\sum_{i=1}^{k} n_i \|c_i - c\|^2}{\sum_{i=1}^{k} \sum_{x \in C_i} \|x - c_i\|^2} \times \frac{(N - k)}{(k - 1)}$
Donde:
Componentes de la Fórmula¶
$ x $:
- Es un punto de datos en el conjunto de datos $ X $.
- Cada $ x $ pertenece a un cluster $ C_i $.
$ k $:
- Número total de clusters.
$ N $:
- Número total de muestras (puntos de datos) en el dataset.
$ n_i $:
- Cantidad de puntos de datos en el cluster $ C_i $.
$ c_i $:
Centroide del cluster $ C_i $ (es decir, el punto medio de los datos dentro del cluster $ i $):
$c_i = \frac{1}{n_i} \sum_{x \in C_i} x$
$ c $:
Centroide global de todos los datos (el promedio de todos los puntos en el dataset):
$c = \frac{1}{N} \sum_{x \in X} x$
$\sum_{i=1}^{k} n_i \|c_i - c\|^2 $ → Dispersión entre clusters
- Representa cuán lejos están los centroides de cada cluster respecto al centroide global.
- Mientras más grande sea este valor, mejor es la separación entre clusters.
$\sum_{i=1}^{k} \sum_{x \in C_i} \|x - c_i\|^2$ → Dispersión dentro de cada cluster
- Representa la compactación de los clusters.
- Se calcula como la suma de las distancias cuadradas de cada punto $ x $ a su centroide $ c_i $.
- Mientras más pequeño sea este valor, más compactos son los clusters.
$\frac{(N - k)}{(k - 1)}$ → Factor de ajuste
- Penaliza la fragmentación excesiva del clustering (es decir, evita que se formen demasiados clusters pequeños).
Nota:
$ n_i $ multiplica la norma cuadrática $ \|c_i - c\|^2 $? para generar una medida proporcional de la dispersión entre clusters.
Distribución de los puntos en cada cluster¶
Si un cluster tiene más puntos, su contribución a la dispersión global debe ser mayor que la de un cluster más pequeño.
- Si un cluster con 10 puntos está alejado del centroide global, su impacto en la separación global debería ser menor que un cluster con 500 puntos igualmente alejado.
- $ n_i $ actúa como un factor de ponderación para reflejar la cantidad de datos que contiene cada cluster.
Ejemplo Intuitivo¶
Imagina que tienes dos configuraciones de clusters en un dataset:
Caso A:
- Cluster 1: 1000 puntos alejados del centro global.
- Cluster 2: 5 puntos alejados del centro global.
Caso B:
- Cluster 1: 500 puntos alejados del centro global.
- Cluster 2: 500 puntos alejados del centro global.
Si solo usáramos $ \|c_i - c\|^2 $ sin ponderar por $ n_i $, ambos casos tendrían la misma dispersión entre clusters, lo cual es incorrecto, ya que el primer caso tiene un cluster muy grande y otro muy pequeño.
Al incluir $ n_i $, la fórmula refleja correctamente que la dispersión entre clusters en el Caso A está dominada por el cluster grande.
Interpretación del Índice de Calinski-Harabasz¶
Valores altos de CHI → Mejor clustering
- Indica que los clusters están bien separados y que los puntos dentro de cada cluster están bien agrupados.
Valores bajos de CHI → Clustering deficiente
- Puede significar que los clusters están superpuestos o que los datos están demasiado dispersos dentro de los clusters.
Ejemplo Intuitivo¶
Imagina que tienes dos agrupaciones de personas en un parque:
Agrupación bien definida:
- Las personas dentro de cada grupo están muy cerca unas de otras (baja dispersión intra-cluster).
- Los dos grupos están bien separados entre sí (alta dispersión inter-cluster).
- Esto daría un CHI alto.
Agrupación mal definida:
- Algunas personas están más dispersas dentro de sus grupos (alta dispersión intra-cluster).
- Los grupos están muy cerca entre sí o mezclados (baja dispersión inter-cluster).
- Esto daría un CHI bajo.
Conclusión¶
El Índice de Calinski-Harabasz es una herramienta poderosa para evaluar la calidad de un clustering:
Maximiza la separación entre clusters y minimiza la dispersión dentro de cada cluster.
Es sensible a la estructura de los datos, lo que lo hace útil en comparación con otros métodos.
Se usa junto con otras métricas (Davies-Bouldin, Silhouette, método del codo) para una mejor decisión sobre $ k $.
Código en Python para Evaluar Clustering¶
El siguiente código implementa DBI y CHI para diferentes números de clusters en K-Means.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import davies_bouldin_score, calinski_harabasz_score, silhouette_score
from sklearn.datasets import make_blobs
# Generar datos de prueba
np.random.seed(3)
X, _ = make_blobs(n_samples=500, centers=5, cluster_std=1.0)# Generamos un conjunto de datos sintético utilizando la función make_blobs de sklearn, que crea clusters de puntos alrededor de centros definidos. En este caso, generamos 500 muestras distribuidas en 5 clusters con una desviación estándar de 1.0.
# Rango de número de clusters a evaluar
cluster_range = range(2, 11)# Definimos un rango de números de clusters (k) que queremos evaluar para nuestro análisis de clustering. En este caso, evaluaremos desde 2 hasta 10 clusters. Este rango nos permitirá analizar cómo varían las métricas de evaluación a medida que cambiamos el número de clusters en el algoritmo KMeans.
# Listas para almacenar las métricas
dbi_scores = []
chi_scores = []
silhouette_scores = []
wcss = [] # Para el método del codo
# Evaluación para diferentes números de clusters
for k in cluster_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
labels = kmeans.fit_predict(X)
# Calcular métricas
dbi = davies_bouldin_score(X, labels)# Calculamos el índice de Davies-Bouldin para evaluar la calidad del clustering. Este índice mide la relación entre la dispersión dentro de los clusters y la separación entre los clusters. Un valor más bajo indica un mejor clustering, ya que sugiere que los clusters son compactos y están bien separados.
chi = calinski_harabasz_score(X, labels) # Calculamos el índice de Calinski-Harabasz para evaluar la calidad del clustering. Este índice mide la relación entre la dispersión entre los clusters y la dispersión dentro de los clusters. Un valor más alto indica un mejor clustering, ya que sugiere que los clusters están bien separados y son compactos.
silhouette = silhouette_score(X, labels)# Calculamos el índice de Silhouette para evaluar la calidad del clustering. Este índice mide qué tan similar es un punto a su propio cluster en comparación con otros clusters. El valor del índice de Silhouette varía entre -1 y 1, donde un valor cercano a 1 indica que los puntos están bien agrupados dentro de su cluster y lejos de otros clusters, un valor cercano a 0 indica que los puntos están en el límite entre dos clusters, y un valor negativo indica que los puntos podrían estar asignados al cluster incorrecto.
inertia = kmeans.inertia_ # Inercia para el método del codo
# Guardar métricas
dbi_scores.append(dbi)
chi_scores.append(chi)
silhouette_scores.append(silhouette)
wcss.append(inertia)
# Graficar los resultados
fig, ax = plt.subplots(2, 3, figsize=(18, 10))
# Método del codo
ax[0, 0].plot(cluster_range, wcss, marker='o', linestyle='-')
ax[0, 0].set_xlabel('Número de Clusters')
ax[0, 0].set_ylabel('Inercia (WCSS)')
ax[0, 0].set_title('Método del Codo')
# Davies-Bouldin
ax[0, 1].plot(cluster_range, dbi_scores, marker='o', linestyle='-')
ax[0, 1].set_xlabel('Número de Clusters')
ax[0, 1].set_ylabel('Índice Davies-Bouldin')
ax[0, 1].set_title('Evaluación con Davies-Bouldin')
# Calinski-Harabasz
ax[0, 2].plot(cluster_range, chi_scores, marker='o', linestyle='-')
ax[0, 2].set_xlabel('Número de Clusters')
ax[0, 2].set_ylabel('Índice Calinski-Harabasz')
ax[0, 2].set_title('Evaluación con Calinski-Harabasz')
# Índice Silhouette
ax[1, 0].plot(cluster_range, silhouette_scores, marker='o', linestyle='-')
ax[1, 0].set_xlabel('Número de Clusters')
ax[1, 0].set_ylabel('Índice Silhouette')
ax[1, 0].set_title('Evaluación con Silhouette')
# Visualización de los clusters con el mejor número de clusters según el índice de Silhouette
best_k = cluster_range[np.argmax(chi_scores)]
best_kmeans = KMeans(n_clusters=best_k, n_init=10)# random_state=3, # Inicializamos el modelo KMeans con el número óptimo de clusters (best_k) determinado por el índice de Silhouette. Este modelo se ajustará a los datos para identificar los clusters y sus centroides correspondientes.
labels_best = best_kmeans.fit_predict(X)# Aplicamos el algoritmo KMeans con el mejor número de clusters (best_k) para obtener las etiquetas de cluster asignadas a cada punto en el dataset. Esto nos permitirá visualizar cómo se han agrupado los datos según el número óptimo de clusters determinado por el índice de Silhouette.
ax[1, 1].scatter(X[:, 0], X[:, 1], c=labels_best, cmap='viridis', marker='.')# Graficamos los puntos del dataset coloreados según los clusters asignados por el modelo KMeans con el mejor número de clusters (best_k). Utilizamos un mapa de colores 'viridis' para diferenciar visualmente los clusters, y cada punto se representa con un marcador de tipo '.' para una visualización clara de la distribución de los datos dentro de cada cluster.
ax[1, 1].scatter(best_kmeans.cluster_centers_[:, 0], best_kmeans.cluster_centers_[:, 1], c='red', marker='x', s=100, label='Centroides')# Graficamos los puntos del dataset coloreados según los clusters asignados por el modelo KMeans con el mejor número de clusters (best_k). Además, graficamos los centroides de los clusters como puntos rojos con forma de 'x' para destacar su posición en el espacio de características. Esto nos permite visualizar cómo se han agrupado los datos y dónde se encuentran los centros de cada cluster.
ax[1, 1].set_title(f'Clusters para K={best_k}')
ax[1, 1].legend()
# Eliminar eje vacío
ax[1, 2].axis('off')# Eliminamos el tercer subplot de la segunda fila, ya que no se utilizará para mostrar ningún gráfico. Esto ayuda a mantener la presentación visual limpia y enfocada en los gráficos relevantes.
plt.tight_layout()# Ajustamos el diseño de los subplots para que no se solapen y se vean claramente cada uno de los gráficos sin superposición de títulos, etiquetas o leyendas. Esto mejora la legibilidad y la presentación visual de los resultados.
plt.show() # Mostramos la figura con todos los subplots que hemos creado, incluyendo los gráficos de las métricas de evaluación y la visualización de los clusters con el mejor número de clusters según el índice de Silhouette.

Comparación de Métodos de Evaluación de Clusters¶
Para seleccionar el número óptimo de clusters en K-Means, hemos evaluado cuatro métricas distintas:
- Método del Codo (WCSS)
- Índice Davies-Bouldin
- Índice Calinski-Harabasz
- Índice Silhouette
Método del Codo (Gráfico Superior Izquierdo)¶
El método del codo evalúa la inercia intra-cluster (suma de distancias cuadradas de cada punto a su centroide). Se busca un punto donde la reducción de la inercia se desacelera significativamente.
Observación en la gráfica:¶
- La inercia disminuye drásticamente entre $ k = 2 $ y $ k = 4 $.
- A partir de $ k = 5 $, la reducción de la inercia es mucho más lenta, lo que sugiere un posible punto de codo en $ k = 4 $ o $ k = 5 $.
Interpretación¶
El mejor $ k $ según el método del codo parece estar en $ k = 4 $ o $ k = 5 $, ya que después de este punto, agregar más clusters no mejora significativamente la reducción de inercia.
Índice de Davies-Bouldin (Gráfico Superior Central)¶
El índice Davies-Bouldin (DBI) mide la relación entre la dispersión intra-cluster y la separación entre clusters. Se busca minimizar este índice.
Observación en la gráfica:¶
- $ DBI $ alcanza su mínimo alrededor de $ k = 5 $.
- Luego, el índice aumenta gradualmente a medida que se incrementa el número de clusters, lo que indica clusters menos definidos.
Interpretación¶
Dado que valores más bajos de $ DBI $ son mejores, este criterio sugiere que el número óptimo de clusters es $ k = 5 $.
Índice de Calinski-Harabasz (Gráfico Superior Derecho)¶
El índice Calinski-Harabasz (CHI) mide la separación inter-cluster en relación con la compactación intra-cluster. Se busca maximizar este índice.
Observación en la gráfica:¶
- CHI alcanza su máximo en $ k = 5 $ y luego comienza a disminuir.
- Un máximo indica una buena separación entre clusters, lo que sugiere que $ k = 5 $ es una opción fuerte.
Interpretación¶
Dado que valores más altos de CHI son mejores, este criterio sugiere que $ k = 5 $ es óptimo.
Índice de Silhouette (Gráfico Inferior Izquierdo)¶
El índice de Silhouette mide la cohesión dentro de los clusters y la separación entre ellos. Se busca maximizar este índice.
Observación en la gráfica:¶
- $ k = 5 $ tiene el mayor valor de Silhouette, indicando que los puntos están bien agrupados y los clusters bien separados.
- Para $ k > 5 $, el índice Silhouette comienza a decrecer, lo que indica que los clusters se vuelven menos definidos.
Interpretación¶
Este criterio sugiere que $ k = 5 $ es la mejor opción, ya que maximiza la calidad de agrupamiento.
Visualización de Clusters (Gráfico Inferior Derecho)¶
En la gráfica de dispersión de la derecha, se muestran los clusters generados con $ k = 5 $, junto con los centroides en rojo.
Observación en la gráfica:¶
- Los clusters se ven bien separados y compactos.
- Los centroides parecen estar bien posicionados en el centro de cada agrupamiento.
Interpretación¶
La visualización respalda la elección de $ k = 5 $ como el mejor número de clusters.
Conclusión Final: ¿Cuál es el mejor $ k $?¶
$ k = 5 $ es la mejor opción, ya que:
- Es sugerido por Davies-Bouldin (mínimo en $ k=5 $).
- Es respaldado por el Índice de Silhouette (máximo en $ k=5 $).
- Es un buen trade-off según el método del codo.
- La visualización muestra clusters bien definidos.
$ k = 5 $ es también una opción razonable, respaldada por el Índice de Calinski-Harabasz (máximo en $ k=5 $), pero la calidad del clustering empieza a disminuir según Silhouette.
Elección final: $ k = 5 $¶
Este valor proporciona clusters bien definidos, separación óptima, y alta cohesión interna, lo que lo convierte en la mejor opción en este análisis.
Este análisis muestra cómo combinar diferentes métricas para una decisión informada sobre el número de clusters en K-Means.
Tarea: Clustering jerárquico y selección sistemática del corte¶
Objetivo¶
En esta actividad deberán implementar clustering jerárquico aglomerativo usando distintos métodos de enlace, visualizar sus dendrogramas y evaluar de manera sistemática dónde realizar el corte para obtener una partición razonable de los datos.
El objetivo no es sólo “hacer correr” el algoritmo, sino también comparar críticamente distintas soluciones de clustering usando métricas cuantitativas y análisis visual.
Dataset sugerido¶
Usaremos el dataset Wine de sklearn, que contiene variables químicas de distintos vinos.
¿Por qué este dataset?¶
- Tiene varias variables numéricas continuas.
- Es suficientemente pequeño para experimentar rápidamente.
- Permite observar diferencias entre métodos de enlace.
- Está precargado en Python vía
sklearn.datasets.
Instrucciones generales¶
- Carguen el dataset Wine.
- Estandaricen las variables.
Implementen clustering jerárquico con al menos estos métodos de enlace:
completeaverageward
- Generen el dendrograma para cada método.
- Evalúen sistemáticamente distintos valores de corte, equivalentes a distintos números de clusters.
Para cada partición obtenida, calculen:
- Davies-Bouldin
- Calinski-Harabasz
- Silhouette Score
- una medida tipo “codo” basada en dispersión intra-cluster
- Comparen los resultados entre métodos de enlace.
Propongan una decisión razonada sobre:
- el mejor método de enlace
- el número de clusters más razonable
- si las métricas coinciden o no entre sí
Resultado esperado¶
El notebook debe incluir:
- código ordenado y comentado
- dendrogramas para cada método
- gráficos de métricas versus número de clusters
- una tabla resumen de resultados
- una interpretación final breve pero clara
Código base¶
Importante: este código está preparado como base de trabajo. Tiene partes ya implementadas para facilitar el arranque, pero deja espacio para que ustedes completen el análisis y la interpretación.
# ============================================================
# 1. Librerías
# ============================================================
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import AgglomerativeClustering
from sklearn.metrics import (
silhouette_score,
davies_bouldin_score,
calinski_harabasz_score
)
from scipy.cluster.hierarchy import linkage, dendrogram
from scipy.spatial.distance import cdist
# ============================================================
# 2. Cargar dataset
# ============================================================
wine = load_wine()
X = wine.data
feature_names = wine.feature_names
df = pd.DataFrame(X, columns=feature_names)
print(df.head()) #IMPORTANTE: Identifiquen la dimensión de la data!!!
# ============================================================
# 3. Estandarizar datos
# ============================================================
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print("Forma de X_scaled:", X_scaled.shape)
# ============================================================
# 4. Función auxiliar: dispersión intra-cluster
# (análogo simple para el “método del codo”)
# ============================================================
def within_cluster_dispersion(X, labels):
"""
Calcula una medida simple de dispersión intra-cluster:
suma de distancias cuadradas de cada punto al centroide de su cluster.
"""
total_dispersion = 0.0
for cluster_id in np.unique(labels):
cluster_points = X[labels == cluster_id]
centroid = cluster_points.mean(axis=0)
total_dispersion += np.sum((cluster_points - centroid) ** 2)
return total_dispersion
# ============================================================
# 5. Métodos de enlace a comparar
# ============================================================
linkage_methods = ["complete", "average", "ward"]
# ============================================================
# 6. Dendrogramas
# ============================================================
# Número de clusters que queremos mostrar
n_clusters = 10 # Este número se elige para mostrar claramente las fusiones en el dendrograma, pero no es un número fijo que deba usarse para el clustering final. El número óptimo de clusters se determinará posteriormente utilizando las métricas de evaluación.
plt.figure(figsize=(18, 5))
for i, method in enumerate(linkage_methods, 1):
# Matriz de enlace
Z = linkage(X_scaled, method=method)
# ------------------------------------------------------------
# Para obtener exactamente n_clusters, el corte debe hacerse
# entre las fusiones Z[-n_clusters, 2] y Z[-(n_clusters-1), 2].
# Un valor intermedio asegura que se vean exactamente n_clusters.
# ------------------------------------------------------------
h1 = Z[-n_clusters, 2]
h2 = Z[-(n_clusters - 1), 2]
cut_height = (h1 + h2) / 2
plt.subplot(1, 3, i)
dendrogram(
Z,
no_labels=True,
color_threshold=cut_height,
above_threshold_color="steelblue"
)
# Línea horizontal que muestra el corte
plt.axhline(y=cut_height, color="black", linestyle="--", linewidth=1)
plt.title(f"Dendrograma - {method} (corte en {n_clusters} clusters)")
plt.xlabel("Observaciones")
plt.ylabel("Distancia")
plt.tight_layout()
plt.show()

# ============================================================
# 7. Evaluación sistemática para distintos números de clusters
# ============================================================
results = []
# Puedes ajustar este rango si quieres explorar más o menos valores
k_values = range(2, 11)
for method in linkage_methods:
for k in k_values:
model = AgglomerativeClustering(n_clusters=k, linkage=method)
labels = model.fit_predict(X_scaled)
# Métricas
silhouette = silhouette_score(X_scaled, labels)
db = davies_bouldin_score(X_scaled, labels)
ch = calinski_harabasz_score(X_scaled, labels)
wcd = within_cluster_dispersion(X_scaled, labels)
results.append({
"linkage": method,
"k": k,
"silhouette": silhouette,
"davies_bouldin": db,
"calinski_harabasz": ch,
"within_dispersion": wcd
})
results_df = pd.DataFrame(results)
results_df.head()
# ============================================================
# 8. Ver resultados en tabla
# ============================================================
results_df.sort_values(["linkage", "k"]).reset_index(drop=True)
# ============================================================
# 9. Graficar métricas para cada método de enlace en panel 2x2
# ============================================================
metrics = ["silhouette", "davies_bouldin", "calinski_harabasz", "within_dispersion"]
ylabels = {
"silhouette": "Silhouette",
"davies_bouldin": "Davies-Bouldin",
"calinski_harabasz": "Calinski-Harabasz",
"within_dispersion": "Within-cluster dispersion"
}
better_text = {
"silhouette": "Mayor es mejor",
"davies_bouldin": "Menor es mejor",
"calinski_harabasz": "Mayor es mejor",
"within_dispersion": "Menor es mejor (buscar codo)"
}
fig, axes = plt.subplots(2, 2, figsize=(14, 8))
axes = axes.ravel()
for ax, metric in zip(axes, metrics):
for method in linkage_methods:
subset = results_df[results_df["linkage"] == method]
ax.plot(subset["k"], subset[metric], marker="o", linewidth=2, label=method)
ax.set_title(f"{ylabels[metric]} vs número de clusters\n{better_text[metric]}")
ax.set_xlabel("Número de clusters (k)")
ax.set_ylabel(ylabels[metric])
ax.grid(True, alpha=0.3)
ax.legend()
plt.tight_layout()
plt.show()

# ============================================================
# 11. Elegir una solución final y visualizar clusters
# ============================================================
# Reemplace estos valores por la solución que ustedes consideren mejor
best_method = "ward" #????
best_k = 3 #????
final_model = AgglomerativeClustering(n_clusters=best_k, linkage=best_method)
final_labels = final_model.fit_predict(X_scaled)
print("Método elegido:", best_method)
print("Número de clusters elegido:", best_k)
print("Tamaño de cada cluster:")
print(pd.Series(final_labels).value_counts().sort_index())
Extra¶
Ya que son multiples dimensiones, usamos PCA para reducir (lo veremos en las proximas clases)
# ============================================================
# 12. Elegir una solución final, imprimir data y pintar clusters
# + comparar con ground truth
# ============================================================
from sklearn.decomposition import PCA
# ------------------------------------------------------------
# 1. Elegir solución final
# ------------------------------------------------------------
best_method = "complete"
best_k = 2
final_model = AgglomerativeClustering(n_clusters=best_k, linkage=best_method)
final_labels = final_model.fit_predict(X_scaled)
# ------------------------------------------------------------
# 2. Crear dataframe con datos originales, clusters y ground truth
# ------------------------------------------------------------
df_clusters = df.copy()
df_clusters["cluster"] = final_labels
df_clusters["true_class"] = wine.target
print(f"Método elegido: {best_method}")
print(f"Número de clusters: {best_k}")
print("\nTamaño de cada cluster encontrado:")
print(df_clusters["cluster"].value_counts().sort_index())
print("\nTamaño de cada clase real:")
print(df_clusters["true_class"].value_counts().sort_index())
print("\nPrimeras filas del dataset con cluster asignado y clase real:")
display(df_clusters.head(10))
# ------------------------------------------------------------
# 3. Tabla de contingencia: cluster encontrado vs clase real
# ------------------------------------------------------------
print("\nTabla de contingencia: clusters encontrados vs ground truth")
contingency_table = pd.crosstab(
df_clusters["cluster"],
df_clusters["true_class"],
rownames=["Cluster encontrado"],
colnames=["Clase real"]
)
display(contingency_table)
# ------------------------------------------------------------
# 4. Reducir a 2 dimensiones con PCA para visualizar
# ------------------------------------------------------------
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
df_clusters["PC1"] = X_pca[:, 0]
df_clusters["PC2"] = X_pca[:, 1]
# ------------------------------------------------------------
# 5. Panel 1: clusters encontrados
# ------------------------------------------------------------
# 6. Panel 2: ground truth
# ------------------------------------------------------------
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# -------------------------
# Panel izquierdo: clustering encontrado
# -------------------------
for cluster_id in sorted(df_clusters["cluster"].unique()):
subset = df_clusters[df_clusters["cluster"] == cluster_id]
axes[0].scatter(
subset["PC1"],
subset["PC2"],
s=60,
alpha=0.8,
label=f"Cluster {cluster_id}"
)
# Centroide visual
centroid_x = subset["PC1"].mean()
centroid_y = subset["PC2"].mean()
axes[0].scatter(
centroid_x,
centroid_y,
s=220,
marker="X",
edgecolor="black",
linewidth=1.2
)
axes[0].text(
centroid_x,
centroid_y,
f"C{cluster_id}",
fontsize=10,
ha="center",
va="center"
)
axes[0].set_title(f"Clusters encontrados\n{best_method}, k={best_k}")
axes[0].set_xlabel("Componente principal 1")
axes[0].set_ylabel("Componente principal 2")
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# -------------------------
# Panel derecho: ground truth
# -------------------------
for class_id in sorted(df_clusters["true_class"].unique()):
subset = df_clusters[df_clusters["true_class"] == class_id]
axes[1].scatter(
subset["PC1"],
subset["PC2"],
s=60,
alpha=0.8,
label=f"Clase real {class_id}"
)
axes[1].set_title("Ground truth del dataset Wine")
axes[1].set_xlabel("Componente principal 1")
axes[1].set_ylabel("Componente principal 2")
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()

Tareas que deben completar¶
Parte A. Implementación¶
- Ejecutar el pipeline completo.
- Verificar que los datos estén correctamente estandarizados.
- Generar y comparar los dendrogramas de los tres métodos.
Parte B. Evaluación sistemática¶
- Probar distintos valores de ( k ) entre 2 y 10.
- Construir una tabla resumen con todas las métricas.
Detectar:
- qué valores de ( k ) favorece cada métrica
- si existen desacuerdos entre métricas
- si algún método de enlace parece más estable que los demás
Parte C. Interpretación¶
Responder en el notebook:
- ¿Qué diferencias visuales observan entre los dendrogramas?
- ¿Cuál método de enlace parece generar particiones más claras?
- ¿Qué número de clusters sugeriría cada métrica?
- ¿Coinciden todas las métricas en la misma solución?
- Si no coinciden, ¿cómo justificarían una decisión final?
- ¿Qué limitaciones tiene usar sólo métricas automáticas para decidir el corte?
Pistas metodológicas¶
Sobre el corte del dendrograma¶
Recuerden que “cortar el dendrograma” equivale a decidir cuántos grupos finales quieren obtener. En esta tarea no basta con mirar el gráfico de forma intuitiva: deben hacerlo de manera sistemática comparando varios valores de ( k ).
Sobre las métricas¶
- Silhouette: mayor es mejor.
- Davies-Bouldin: menor es mejor.
- Calinski-Harabasz: mayor es mejor.
- Within-cluster dispersion: menor es mejor, pero deben buscar un posible “codo”, no sólo el valor mínimo.
Advertencia importante¶
En clustering jerárquico, el “método del codo” no viene dado de forma nativa como en K-Means. Aquí lo aproximaremos usando una medida de dispersión intra-cluster de la partición final.
Combinaciones Métrica–Linkage razonables¶
En clustering jerárquico debemos elegir dos cosas:
cómo medir la distancia entre puntos (métrica)
cómo unir clusters (linkage)
No todas las combinaciones tienen sentido. Escribe las combinaciones que tiene sentido desde lo que aprendiste.