Autoencoders y Autoencoders Convolucionales¶
Modelos de Machine Learning No-Supervisados¶
Dr. Cristian Candia¶
Universidad del Desarrollo (UDD), Chile¶
- Director, Computational Research in Social Sciences Lab
- Faculty, Data Science Institute, School of Engineering
Northwestern University, United States¶
- External Faculty, Northwestern Institute on Complex Systems (NICO), Kellogg School of Management
Founder & CSTO¶
- Capybara. Capybara ayuda a establecimiento educacionales a detectar señales tempranas de bullying, medir convivencia escolar y tomar decisiones basadas en evidencia para prevenir conflictos a tiempo.
Del Espacio de Alta Dimensión al Espacio Latente: Aprendiendo Embeddings¶
Anteriormente exploramos UMAP, una técnica no supervisada para proyectar datos de alta dimensión en espacios más simples, preservando estructuras locales y globales. Hoy seguimos profundizando en ese objetivo: cómo aprender buenas representaciones internas o embeddings de los datos, pero esta vez, utilizando redes neuronales.
Fundamento común: Embeddings¶
| Técnica | ¿Qué hace? | ¿Cómo? | Tipo |
|---|---|---|---|
| PCA | Encuentra direcciones de máxima varianza lineal | Descomposición lineal | Lineal |
| UMAP | Preserva topología local/global en proyección | Vecindarios + teoría de grafos + optimización | No lineal |
| Autoencoder | Aprende una codificación eficiente (embedding) | Red neuronal entrenada para reconstrucción | No lineal aprendida |
Embedding Latente¶
En todos los casos anteriores, estamos construyendo un espacio latente $ h \in \mathbb{R}^d $ que captura información esencial de la instancia de entrada $ x \in \mathbb{R}^D $, con $ d \ll D $. La diferencia radica en el mecanismo que genera ese embedding:
- PCA: transforma los datos con proyecciones ortogonales lineales.
- UMAP: construye un grafo de vecinos y optimiza la proyección para preservar cercanías.
- Autoencoder: aprende una función $ f_\theta(x) = h $ que minimiza la pérdida de reconstrucción.
De UMAP, t-SNE y PCA a Autoencoders: ¿Qué representa un embedding?¶
¿Qué es un embedding?¶
Formalmente, un embedding es una función $ f: \mathbb{R}^D \to \mathbb{R}^d $, con $ d \ll D $, que proyecta un vector de alta dimensión en un espacio más compacto, preservando ciertas propiedades clave de los datos originales (e.g., distancias, densidades, conectividad local, separabilidad de clases).
Comparación de métodos: ¿Qué tipo de embedding aprenden?¶
| Método | Tipo de técnica | Mapa $ f(x) $ aprendido | Optimiza... | Preserva... |
|---|---|---|---|---|
| PCA | Lineal, global | $ f(x) = W^\top x $ | Máxima varianza | Varianza global |
| t-SNE | No lineal, local | implícito (no función) | Divergencia de Kullback-Leibler | Vecindad local (probabilística) |
| UMAP | No lineal, local | implícito (no función) | Cross-entropy entre grafos fuzzy | Conectividad topológica local/global |
| Autoencoder | No lineal, aprendida | Red neuronal entrenada | Error de reconstrucción (e.g., MSE) | Información suficiente para reconstrucción |
Intuiciones matemáticas¶
PCA¶
Busca una base ortonormal $ W \in \mathbb{R}^{D \times d} $ que maximice:
$\text{Var}(W^\top X) = \sum_{i=1}^{d} \lambda_i$
Donde $ \lambda_i $ son los autovalores de la matriz de covarianza. La proyección $ W^\top x $ es el embedding.
PCA es óptimo bajo reconstrucción lineal con error cuadrático.
t-SNE¶
Minimiza la divergencia KL entre distribuciones de probabilidad en alta y baja dimensión:
$\text{KL}(P \| Q) = \sum_{i \neq j} p_{ij} \log \frac{p_{ij}}{q_{ij}}$
- $ p_{ij} $: similitud entre puntos $ x_i, x_j $ en alta dimensión (gaussiana).
- $ q_{ij} $: similitud en baja dimensión (distribución t de Student).
t-SNE genera mapas donde los puntos similares permanecen cercanos, pero no hay función explícita $ f(x) $.
UMAP¶
Basado en la teoría de simplicial sets. Construye dos grafos difusos:
- Uno en alta dimensión (basado en $ k $-vecinos).
- Uno en baja dimensión.
Optimiza:
$\mathcal{L} = \sum_{i,j} w_{ij}^{(high)} \log \frac{w_{ij}^{(high)}}{w_{ij}^{(low)}} + (1 - w_{ij}^{(high)}) \log \frac{1 - w_{ij}^{(high)}}{1 - w_{ij}^{(low)}}$
UMAP busca preservar la estructura topológica local/global mediante grafos probabilísticos.
Autoencoder¶
Una red neuronal con arquitectura encoder-decoder. Optimiza:
$\min_{\theta, \phi} \sum_{i=1}^n \|x_i - g_\phi(f_\theta(x_i))\|^2$
Donde:
- $ f_\theta(x) \in \mathbb{R}^d $ es el embedding latente.
- $ g_\phi(h) \in \mathbb{R}^D $ es el decodificador.
El embedding latente está aprendido como representación compacta que permite reconstruir la entrada.
¿Qué es un Autoencoder?¶
Idea general¶
Un autoencoder es una red neuronal que se entrena para copiar su entrada a la salida, pero con una trampa: entre medio debe comprimir la información en una representación intermedia llamada embedding latente.

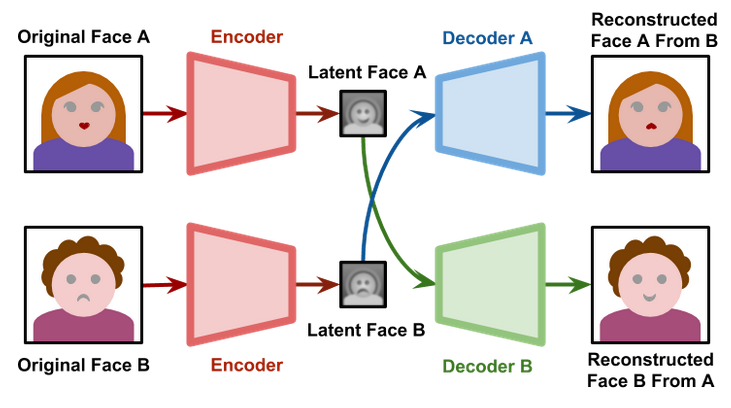
Piensa en un compresor de archivos que reduce el tamaño de un documento sin perder lo esencial. El autoencoder hace algo parecido con datos: aprende a comprimirlos en una representación más pequeña y luego reconstruirlos. La diferencia es que nadie le dice qué es "lo esencial" — lo descubre solo minimizando el error de reconstrucción.
Objetivo de la arquitectura Autoencoder¶
El objetivo central de un autoencoder es:
Aprender una representación comprimida, útil y significativa de los datos sin usar etiquetas.¶
Más concretamente:
- Capturar las estructuras esenciales del conjunto de datos.
- Generar un embedding latente que:
- Permita reconstruir la entrada original (criterio de entrenamiento).
- Pueda ser usado en tareas posteriores (clasificación, visualización, clustering).
- Funcionar como una forma no supervisada de aprendizaje de características (feature learning).
El autoencoder se entrena sin saber qué número hay en la imagen. Solo quiere reconstruir bien lo que vio. Pero para hacerlo, debe aprender a representar la información de forma eficiente. Esa eficiencia es lo que nos interesa.
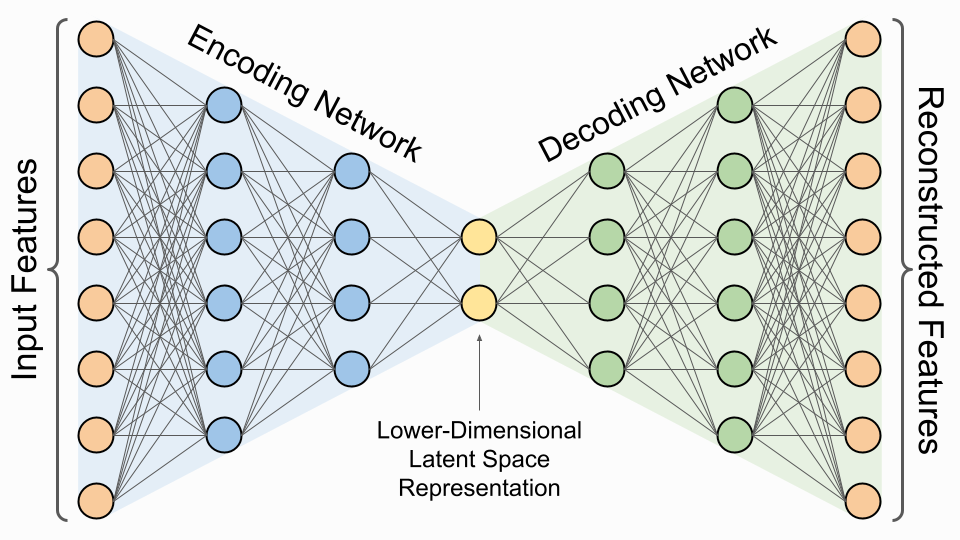
Arquitectura general¶
Un autoencoder tiene dos partes:
Encoder $ f_\theta(x) $:
Transforma los datos originales $ x \in \mathbb{R}^D $ en una versión comprimida $ h \in \mathbb{R}^d $, donde usualmente $ d \ll D $.
Es decir, aprende una función $ f_\theta: \mathbb{R}^D \to \mathbb{R}^d $.Decoder $ g_\phi(h) $:
Intenta reconstruir la entrada original desde el embedding latente: $ \hat{x} = g_\phi(h) \in \mathbb{R}^D $.
Es decir, aprende una función $ g_\phi: \mathbb{R}^d \to \mathbb{R}^D $.
Función de pérdida (lo que se optimiza)¶
La red se entrena minimizando la diferencia entre la entrada original $ x_i $ y su reconstrucción $ \hat{x}_i = g_\phi(f_\theta(x_i)) $. Esto se expresa como:
$\min_{\theta, \phi} \sum_{i=1}^{n} \left\| x_i - g_\phi(f_\theta(x_i)) \right\|^2$
Esta es una pérdida por reconstrucción, y en este caso usamos el error cuadrático medio (MSE).
Intuición¶
El autoencoder trata de copiar lo mejor posible la entrada, pero pasando por una compresión intermedia.
Si la salida es parecida a la entrada, quiere decir que el embedding capturó bien la información relevante.
Ejemplo¶
Supongamos que una imagen (aplanada) es un vector de 3 píxeles:
Entrada original:
$ x = [0.2,\ 0.8,\ 0.5] $Salida reconstruida por el autoencoder:
$ \hat{x} = [0.1,\ 0.7,\ 0.4] $
El MSE (error cuadrático medio) sería:
$\text{MSE} = \frac{1}{3} \left[(0.2 - 0.1)^2 + (0.8 - 0.7)^2 + (0.5 - 0.4)^2\right] = \frac{1}{3}(0.01 + 0.01 + 0.01) = 0.01$
¿Qué significa?¶
- Si el MSE es alto, significa que la red no está reconstruyendo bien → el embedding no está capturando bien la información.
- Si el MSE es bajo, significa que la reconstrucción es muy similar a la entrada original.
El objetivo del entrenamiento es minimizar ese error.
Nota: ¿Qué significa aplanar una imagen?¶
Las imágenes, como las del dataset MNIST, son matrices de píxeles.
Por ejemplo, una imagen MNIST es:
$\text{Imagen de 28×28} \Rightarrow \text{una matriz con 28 filas y 28 columnas}$
Pero las redes neuronales densas (fully connected) esperan vectores como entrada, no matrices.
Aplanar = pasar de matriz a vector¶
"Aplanar" una imagen significa convertir la matriz de 28×28 en un vector de 784 valores (28 × 28 = 784).
Así, cada píxel ocupa una posición en una lista (vector), y podemos alimentar ese vector a una red neuronal.
### EJEMPLO
import numpy as np
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# ===========================
# Entrada original vs reconstrucción
# ===========================
x_original = np.array([0.2, 0.8, 0.5]) # Entrada original
x_reconstruida = np.array([0.1, 0.7, 0.4]) # Salida del autoencoder
# ===========================
# Cálculo manual del MSE
# ===========================
errores = (x_original - x_reconstruida) ** 2
mse_manual = np.mean(errores)
# ===========================
# Cálculo con sklearn
# ===========================
mse_sklearn = mean_squared_error(x_original, x_reconstruida)
# ===========================
# Resultados
# ===========================
print("Errores por componente:", errores)
print("MSE (cálculo manual):", mse_manual)
print("MSE (usando sklearn):", mse_sklearn)
# ===========================
# Visualización
# ===========================
labels = ['pixel 1', 'pixel 2', 'pixel 3']
x = np.arange(len(labels))
fig, ax = plt.subplots()
ax.bar(x - 0.15, x_original, width=0.3, label='Original')
ax.bar(x + 0.15, x_reconstruida, width=0.3, label='Reconstruida')
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.set_ylabel("Intensidad")
ax.set_title("Reconstrucción vs Entrada original")
ax.legend()
plt.show()

OJO¶
No existe un umbral absoluto o universal para decir si un MSE es "bueno" o "malo". Depende del contexto, de la escala de los datos, y del tipo de problema.
¿Por qué no hay un umbral fijo para MSE?¶
El valor del MSE depende de:
La escala de los datos:
- Si tus datos están en el rango $[0, 1]$, como en imágenes normalizadas, un MSE de 0.01 puede ser aceptable.
- Pero si tus datos están en $[0, 255]$, ese mismo valor sería casi perfecto.
El número de dimensiones:
- El MSE es un promedio: mientras más dimensiones, más "distribuido" el error.
La complejidad de los datos:
- Reconstruir ruido blanco tiene un MSE bajo pero no es útil.
- Reconstruir dígitos con estructura requiere más capacidad, por lo tanto el MSE puede ser un poco mayor pero sigue siendo significativo.
Entonces, ¿cómo saber si el MSE es bueno?¶
Dicho esto, hay tres criterios concretos para evaluar si el MSE es razonable:
Comparación relativa¶
¿El MSE bajó respecto a un modelo base o al inicio del entrenamiento?
- Si al empezar el entrenamiento el MSE era 0.12 y luego baja a 0.02, ¡hay una mejora!
Visualización¶
¿La reconstrucción se ve bien?
- Un MSE de 0.03 puede estar bien si los dígitos reconstruidos son reconocibles.
- A veces una reconstrucción con MSE bajo se ve borrosa → combinar métricas con visualización es clave.
Comparación entre modelos¶
¿El autoencoder profundo mejora respecto a PCA?
- Puedes comparar los MSE de:
- PCA con 32 componentes
- Autoencoder simple
- Autoencoder profundo
- Si el autoencoder tiene menor MSE que PCA, está funcionando mejor.
Por lo tanto: "No importa sólo que el número del MSE sea bajo. Importa que sea más bajo que antes, que la reconstrucción tenga sentido, y que el modelo esté aprendiendo algo útil."
¿Qué está aprendiendo el modelo?¶
El encoder y el decoder son funciones parametrizadas por redes neuronales (con pesos $ \theta $ y $ \phi $), que se ajustan mediante backpropagation.
- El encoder aprende a extraer las características más relevantes de los datos en una representación comprimida $ h $.
- El decoder aprende a usar esa información comprimida para reconstruir lo más fielmente posible la entrada original.
El embedding latente¶
El vector $ h = f_\theta(x) \in \mathbb{R}^d $ se llama embedding latente. Es:
- Una representación compacta del dato original.
- Aprendida automáticamente durante el entrenamiento.
- Potencialmente útil para otras tareas, como clasificación, clustering, generación, etc.
Nota clave: A diferencia de métodos como PCA, en los autoencoders el espacio latente es no lineal y aprendido, no fijo.
Imaginen que el encoder es un periodista que tiene que resumir una noticia larga (la entrada) en 3 frases (el embedding latente). El decoder es otro periodista que, usando solo esas 3 frases, debe reconstruir el artículo completo. El autoencoder se entrena hasta que esta reconstrucción sea lo más parecida posible al original.
Aunque su idea es simple —copiar la entrada—, los autoencoders se han transformado en una herramienta poderosa para entender, transformar y generar datos. Son el punto de partida hacia los modelos generativos más sofisticados de hoy.
¿Por qué es útil esta arquitectura?¶
- Permite reducir dimensionalidad no linealmente.
- Aprende una representación interna estructurada.
- Base para métodos más avanzados como:
- Denoising Autoencoders
- Sparse Autoencoders
- Contractive Autoencoders
- Variational Autoencoders (VAE)
Nota histórica¶
Los autoencoders tienen una larga historia que antecede a los modelos modernos de deep learning. Algunos hitos importantes:
| Año | Evento clave |
|---|---|
| 1986 | Rumelhart, Hinton y Williams formalizan el algoritmo de backpropagation, que permite entrenar redes con múltiples capas ocultas. Esto abre la puerta al entrenamiento de arquitecturas profundas como los autoencoders. |
| 1990s | Los autoencoders se estudian como técnica de reducción de dimensionalidad no lineal, pero el entrenamiento de redes profundas seguía siendo difícil. |
| 2006 | Hinton y Salakhutdinov publican "Reducing the Dimensionality of Data with Neural Networks" (Science, 2006), mostrando que los autoencoders profundos pueden aprender representaciones compactas útiles si se inicializan correctamente. En paralelo, Hinton et al. proponen las Deep Belief Networks basadas en Restricted Boltzmann Machines, marcando el inicio del deep learning moderno. |
| 2010s | Renacimiento de autoencoders en el contexto de: |
- Reducción de dimensionalidad no lineal.
- Detección de anomalías.
- Generación de imágenes (VAEs, GANs).
- Aprendizaje auto-supervisado.
Visualización comparativa: embeddings en acción¶
A continuación, mostramos visualmente los resultados de aplicar PCA, t-SNE, UMAP y Autoencoder (con 2D en la capa latente) sobre MNIST.
Idea general del ejercicio¶
Al final del lab haremos una discusión completa sobre cuándo conviene usar cada método. Por ahora, el objetivo es desarrollar intuición visual.
Este ejercicio muestra cómo distintos algoritmos de reducción de dimensionalidad proyectan los datos de MNIST (imágenes de 28×28 píxeles) a 2 dimensiones. El objetivo es comparar:
- ¿Qué estructura o agrupamiento de clases aprende cada método?
- ¿Cuál logra mayor separación entre los dígitos?
- ¿Qué tan útiles son estos métodos para visualizar datos complejos?
import os
# Limitar threads para reducir conflictos OpenMP / MKL / BLAS
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"
os.environ["OPENBLAS_NUM_THREADS"] = "1"
os.environ["NUMEXPR_NUM_THREADS"] = "1"
os.environ["VECLIB_MAXIMUM_THREADS"] = "1"
# TensorFlow
os.environ["TF_NUM_INTRAOP_THREADS"] = "1"
os.environ["TF_NUM_INTEROP_THREADS"] = "1"
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # workaround; no es lo ideal, pero a veces evita el crash
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import umap
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
# Limitar threads también desde TensorFlow
tf.config.threading.set_intra_op_parallelism_threads(1)
tf.config.threading.set_inter_op_parallelism_threads(1)
# ==========================================================
# 1. Cargar y preparar datos
# ==========================================================
(x_train, y_train), _ = mnist.load_data()
x_train = x_train[:2000].astype("float32") #/ 255.0 # usar solo 2000 muestras para acelerar el proceso
y_train = y_train[:2000] # labels para visualización
x_train = x_train.reshape((len(x_train), -1)) # aplanar imágenes a vectores de 784 dimensiones
# ==========================================================
# 2. Reducción lineal con PCA
# ==========================================================
pca = PCA(n_components=2, random_state=42).fit_transform(x_train)
# ==========================================================
# 3. Reducción no lineal con t-SNE
# ==========================================================
tsne = TSNE( #
n_components=2,
perplexity=30,
init="pca", # usar PCA para inicialización puede ayudar a la estabilidad
learning_rate="auto",
random_state=42
).fit_transform(x_train)
# ==========================================================
# 4. Reducción no lineal con UMAP
# ==========================================================
umap_embedding = umap.UMAP(
n_components=2,
random_state=42
).fit_transform(x_train)
# ==========================================================
# 5. Autoencoder con espacio latente 2D
# ==========================================================
input_img = Input(shape=(784,))
encoded = Dense(128, activation="relu")(input_img)
encoded = Dense(64, activation="relu")(encoded)
encoded_2d = Dense(2)(encoded) # Espacio latente
decoded = Dense(64, activation="relu")(encoded_2d)
decoded = Dense(128, activation="relu")(decoded)
decoded = Dense(784, activation="sigmoid")(decoded)
autoencoder = Model(input_img, decoded)
encoder = Model(input_img, encoded_2d)
autoencoder.compile(optimizer="adam", loss="mse")
autoencoder.fit(
x_train,
x_train,
epochs=20, # prueba primero con menos epochs
batch_size=256,
shuffle=True,
verbose=0
)
ae_embedding = encoder.predict(x_train, verbose=0)
# ==========================================================
# 6. Visualización comparativa unificada
# ==========================================================
methods = {
"PCA": pca,
"t-SNE": tsne,
"UMAP": umap_embedding,
"Autoencoder": ae_embedding
}
fig, axs = plt.subplots(1, 4, figsize=(20, 5), sharex=False, sharey=False)
palette = sns.color_palette("tab10", 10)
for ax, (name, emb) in zip(axs, methods.items()):
sns.scatterplot(
x=emb[:, 0],
y=emb[:, 1],
hue=y_train,
palette=palette,
ax=ax,
legend=False,
s=10
)
ax.set_title(name)
ax.set_xticks([])
ax.set_yticks([])
fig_tmp, ax_tmp = plt.subplots()
scatter = sns.scatterplot(
x=methods["PCA"][:, 0],
y=methods["PCA"][:, 1],
hue=y_train,
palette=palette,
ax=ax_tmp,
legend="full"
)
handles, labels = scatter.get_legend_handles_labels()
plt.close(fig_tmp)
fig.legend(
handles,
labels,
title="Dígito",
loc="center left",
bbox_to_anchor=(1.01, 0.5),
borderaxespad=0,
frameon=True
)
plt.suptitle("Comparación de embeddings 2D en MNIST", fontsize=14)
plt.tight_layout(rect=[0, 0, 0.95, 1])
plt.show()

Interpretación de los resultados¶
PCA:¶
- Forma más dispersa y continua.
- Captura variación global, pero los grupos de dígitos se mezclan.
- Función lineal → limitada para separar clases no lineales.
t-SNE:¶
- Grupos muy bien definidos y separados.
- Clústeres densos → excelente para visualización, pero:
- No preserva escala ni relaciones globales.
- No tiene función de mapeo reutilizable.
UMAP:¶
- También muestra separación clara entre dígitos.
- A diferencia de t-SNE, preserva mejor la estructura global.
- Grupos con formas más coherentes y conectividad más natural.
Autoencoder:¶
- Representación más difusa y continua.
- Algunos dígitos se mezclan (e.g., 4, 7 y 9), otros se separan bien (e.g., 1 y 0).
- Embedding aprendido mediante reconstrucción, no con un objetivo explícito de separar clases.
Entonces:¶
¿Qué estructura parecen preservar cada uno?¶
| Método | Estructura que preserva |
|---|---|
| PCA | Varianza global (direcciones lineales de mayor varianza) |
| t-SNE | Vecindades locales (probabilidades de cercanía entre pares) |
| UMAP | Vecindades locales y conectividad topológica (gráfico fuzzy) |
| Autoencoder | Información útil para reconstrucción de los datos |
¿Dónde se ve la mayor separación entre dígitos?¶
- t-SNE y UMAP son los más efectivos para separar clústeres por clase.
- Autoencoder no busca explícitamente separar clases, por lo que su espacio es más continuo.
- PCA es el menos efectivo en este sentido.
¿Por qué t-SNE y UMAP no tienen funciones explícitas de mapeo?¶
- Ambos son algoritmos no paramétricos:
- No aprenden una función $ f(x) $, sino que optimizan directamente la posición de los puntos en 2D.
- Cada vez que ejecutas t-SNE o UMAP, obtienes un resultado ligeramente distinto.
- No puedes fácilmente mapear nuevos datos sin volver a entrenar.
En cambio, los autoencoders sí aprenden una función explícita $ f_\theta(x) $ → puedes codificar nuevos ejemplos sin reentrenar.
¿Por qué son útiles los embeddings entrenados?¶
Los embeddings entrenados son representaciones vectoriales aprendidas automáticamente por un modelo (como un autoencoder o una red neuronal profunda) para capturar la estructura subyacente de los datos en un espacio de menor dimensión.
Ventajas clave¶
| Ventaja | Explicación |
|---|---|
| Compresión no lineal | A diferencia de PCA, los embeddings aprendidos pueden capturar relaciones complejas y no lineales en los datos. |
| Representación significativa | El modelo aprende qué dimensiones son más relevantes para la tarea de reconstrucción, clasificación o predicción. |
| Reutilización eficiente | Una vez entrenado, el encoder puede usarse como extractor de características para nuevos datos sin tener que reentrenar todo el sistema. |
| Reducción de ruido | El proceso de codificación puede aprender a filtrar información irrelevante o ruidosa. |
| Espacio estructurado | En el espacio latente, instancias similares están cercanas → ideal para clustering o búsqueda semántica. |
| Escalabilidad | Los embeddings se pueden usar como input para modelos más simples (SVM, KNN, etc.), mejorando eficiencia. |
¿Para qué sirven los embeddings entrenados?¶
Una vez que tienes el encoder entrenado, puedes usarlo para cualquier tarea que necesite una representación compacta de los datos: clasificación con modelos más simples (SVM, regresión logística), clustering en el espacio latente, búsqueda por similitud, o detección de anomalías. La clave es que el embedding captura estructura útil sin haber visto etiquetas.
Discusión¶
¿Cómo cambia nuestra forma de trabajar con datos cuando, en lugar de usar atributos manuales, usamos embeddings aprendidos por una red? ¿Qué implicancias tiene esto para tareas como clustering, visualización o predicción?
Mini-ejercicio:¶
Aprender MNIST usando PCA y Autoencoders
# !pip install keras
# !pip install tensorflow
# Importamos las librerías necesarias
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Input, Dense
# ======================================
# Cargar el dataset MNIST
# ======================================
# Cargamos los datos de entrenamiento (imágenes y etiquetas)
(x_train, y_train), _ = mnist.load_data()
# Seleccionamos solo las primeras 2000 imágenes para hacer el entrenamiento más rápido
# Convertimos los valores de 0-255 a valores entre 0 y 1 (normalización)
x_train = x_train[:2000].astype('float32') / 255.
# Reescribimos cada imagen 28x28 como un vector de 784 elementos (flatten)
x_train = x_train.reshape((len(x_train), -1))
# Aseguramos que las etiquetas coincidan en cantidad con los datos
y_train = y_train[:2000]
# ======================================
# PCA para 32 componentes
# ======================================
# Creamos un modelo PCA que reduzca las dimensiones de 784 a 32
pca = PCA(n_components=32)
# Ajustamos el modelo PCA a los datos de entrenamiento
x_pca = pca.fit_transform(x_train)
# Reconstruimos las imágenes desde las 32 dimensiones latentes
x_pca_inv = pca.inverse_transform(x_pca)
# ======================================
# Autoencoder simple (undercomplete)
# ======================================
# Definimos la entrada de 784 dimensiones (una imagen flatten de 28x28)
input_img = Input(shape=(784,))
# Capa de codificación: reduce a 32 dimensiones usando una activación ReLU
encoded = Dense(32, activation='relu')(input_img)
# Capa de decodificación: reconstruye la imagen original de vuelta a 784 dimensiones
# Usamos 'sigmoid' para que los valores estén entre 0 y 1
decoded = Dense(784, activation='sigmoid')(encoded)
# Definimos el modelo completo: input → encoded → decoded
autoencoder = Model(input_img, decoded)
# Compilamos el modelo con el optimizador 'adam' y pérdida de error cuadrático medio (MSE)
autoencoder.compile(optimizer='adam', loss='mse')
# Entrenamos el autoencoder usando las imágenes como input y también como target (reconstrucción)
autoencoder.fit(x_train, x_train, epochs=10, batch_size=256, shuffle=True)
# ======================================
# Reconstrucciones
# ======================================
# Obtenemos las reconstrucciones del autoencoder para las primeras 10 imágenes del set
x_ae = autoencoder.predict(x_train[:10])
# ======================================
# Visualización comparativa
# ======================================
# Definimos una función que dibuja:
# - Fila 1: imágenes originales
# - Fila 2: reconstrucciones con PCA
# - Fila 3: reconstrucciones con Autoencoder
def plot_comparison(original, recon_pca, recon_ae):
fig, axs = plt.subplots(3, 10, figsize=(20, 6))
for i in range(10):
# Fila 1: Imagen original
axs[0, i].imshow(original[i].reshape(28, 28), cmap='gray')
axs[0, i].axis('off')
# Fila 2: Reconstrucción con PCA
axs[1, i].imshow(recon_pca[i].reshape(28, 28), cmap='gray')
axs[1, i].axis('off')
# Fila 3: Reconstrucción con Autoencoder
axs[2, i].imshow(recon_ae[i].reshape(28, 28), cmap='gray')
axs[2, i].axis('off')
# Etiquetas a la izquierda de cada fila
axs[0, 0].set_ylabel("Original")
axs[1, 0].set_ylabel("PCA")
axs[2, 0].set_ylabel("Autoencoder")
# Mostrar el gráfico
plt.show()
# Llamamos a la función de visualización para mostrar los resultados comparativos
plot_comparison(x_train[:10], x_pca_inv[:10], x_ae)

Análisis del resultado de la visualización¶
La imagen muestra tres filas de dígitos:
- Primera fila (originales): Son dígitos MNIST claramente definidos. Bien.
- Segunda fila (PCA): Las reconstrucciones con PCA están borrosas, pero las formas son reconocibles. Es lo esperable, ya que PCA proyecta de forma lineal y puede perder detalles.
- Tercera fila (Autoencoder): Todas las imágenes parecen el mismo dígito, como un "9" deformado. Esto sugiere que el autoencoder no ha aprendido adecuadamente a reconstruir las entradas.
¿Qué puede estar fallando en el autoencoder?¶
Código funcionalmente correcto:¶
El código está bien estructurado. Sin embargo, hay dos posibles problemas críticos en la práctica que explican el mal desempeño:
Problema 1: Pocas épocas¶
autoencoder.fit(x_train, x_train, epochs=10, batch_size=256, shuffle=True)
Solo 10 épocas y con 2000 datos es probablemente muy poco para que el autoencoder logre aprender una representación significativa. Esto es especialmente cierto si se usan dos capas de tamaño 784 → 32 → 784, lo que requiere más datos para capturar bien los patrones.
Solución: prueba con 50 o 100 épocas.
Problema 2: Arquitectura muy simple¶
encoded = Dense(32, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
Esto es una red muy shallow (poca profundidad). A veces una sola capa intermedia no es suficiente para que el autoencoder aprenda buenas reconstrucciones no lineales. Puede haber aprendido un "promedio" visual (de ahí que todos parecen 9s o 8s).
Solución sugerida: usa una arquitectura ligeramente más profunda:
# Encoder
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(32, activation='relu')(encoded)
# Decoder
decoded = Dense(64, activation='relu')(encoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='sigmoid')(decoded)
Otras recomendaciones¶
- Verifica que el modelo se haya entrenado bien: puedes hacer
autoencoder.summary()y revisar si tiene suficientes parámetros para la tarea. - Visualiza la pérdida durante el entrenamiento: puede que no haya bajado lo suficiente.
Este resultado muestra lo importante que es elegir una buena arquitectura y entrenar suficientemente. Aunque el código esté bien escrito, el modelo puede no aprender si no tiene capacidad suficiente o tiempo de entrenamiento.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
# ======================================
# Cargar datos con etiquetas
# ======================================
(x_train, y_train), _ = mnist.load_data()
x_train = x_train[:2000].astype('float32') #/ 255. # Normalizamos [0,1]
x_train = x_train.reshape((len(x_train), -1)) # Flatten: 28x28 → 784
y_train = y_train[:2000] # Cortamos también las etiquetas
# ======================================
# PCA para 32 componentes
# ======================================
pca = PCA(n_components=32)
x_pca = pca.fit_transform(x_train) # Proyección a 32D
x_pca_inv = pca.inverse_transform(x_pca) # Reconstrucción a 784D
# ======================================
# Autoencoder profundo (undercomplete)
# ======================================
input_img = Input(shape=(784,))
# Encoder profundo
x = Dense(128, activation='relu')(input_img)
x = Dense(64, activation='relu')(x)
encoded = Dense(32, activation='relu')(x) # Embedding latente 32D
# Decoder profundo
x = Dense(64, activation='relu')(encoded)
x = Dense(128, activation='relu')(x)
decoded = Dense(784, activation='sigmoid')(x) # Salida reconstruida
# Modelo autoencoder completo
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adam', loss='mse')
# Entrenamiento del autoencoder
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256, shuffle=True, verbose=1)
# Reconstrucciones del autoencoder (10 primeras imágenes)
x_ae = autoencoder.predict(x_train[:10])
# ======================================
# Visualización comparativa
# ======================================
def plot_comparison(original, recon_pca, recon_ae):
fig, axs = plt.subplots(3, 10, figsize=(20, 6))
for i in range(10):
# Fila 1: Imágenes originales
axs[0, i].imshow(original[i].reshape(28, 28), cmap='gray')
axs[0, i].axis('off')
# Fila 2: Reconstrucción con PCA
axs[1, i].imshow(recon_pca[i].reshape(28, 28), cmap='gray')
axs[1, i].axis('off')
# Fila 3: Reconstrucción con Autoencoder
axs[2, i].imshow(recon_ae[i].reshape(28, 28), cmap='gray')
axs[2, i].axis('off')
# Etiquetas a la izquierda de cada fila
axs[0, 0].set_ylabel("Original", fontsize=12)
axs[1, 0].set_ylabel("PCA", fontsize=12)
axs[2, 0].set_ylabel("Autoencoder", fontsize=12)
plt.tight_layout()
plt.show()
# Ejecutamos la visualización comparativa
plot_comparison(x_train[:10], x_pca_inv[:10], x_ae)

Comparación de reconstrucciones: PCA vs Autoencoder¶
Tanto PCA como el autoencoder logran reconstruir razonablemente bien la forma general de los dígitos al comprimir de 784 a 32 dimensiones. Sin embargo, PCA tiende a producir reconstrucciones más borrosas y suavizadas, porque su compresión es lineal y depende de componentes principales globales.
El autoencoder, en cambio, aprende una representación no lineal adaptada a los datos, lo que le permite capturar mejor ciertos rasgos característicos de los dígitos. En varios ejemplos, sus reconstrucciones preservan de forma más fiel la estructura visual del número original, aunque todavía presentan algo de difuminación.
import seaborn as sns
from sklearn.decomposition import PCA
# =====================================
# 1. Definir el encoder
# =====================================
# Este modelo va desde la entrada (784D) hasta la capa latente (32D)
encoder = Model(inputs=input_img, outputs=encoded)
# =====================================
# 2. Obtener embeddings latentes
# =====================================
z_auto = encoder.predict(x_train, verbose=0) # shape: (2000, 32)
print("Shape del embedding latente:", z_auto.shape)
# =====================================
# 3. Reducir el embedding 32D a 2D para visualizar
# =====================================
pca_latent = PCA(n_components=2, random_state=42)
z_2d = pca_latent.fit_transform(z_auto)
# =====================================
# 4. Graficar
# =====================================
plt.figure(figsize=(8, 6))
sns.scatterplot(
x=z_2d[:, 0],
y=z_2d[:, 1],
hue=y_train,
palette="tab10",
s=20
)
plt.title("PCA del espacio latente aprendido por el Autoencoder")
plt.xlabel("Componente 1")
plt.ylabel("Componente 2")
plt.legend(title="Dígito", bbox_to_anchor=(1.02, 1), loc="upper left")
plt.tight_layout()
plt.show()

import umap
import seaborn as sns
encoder = Model(inputs=input_img, outputs=encoded)
z_auto = encoder.predict(x_train, verbose=0).astype("float32")
z_umap = umap.UMAP(
n_neighbors=15,
min_dist=0.1,
n_components=2,
random_state=42
).fit_transform(z_auto)
plt.figure(figsize=(8, 6))
sns.scatterplot(
x=z_umap[:, 0],
y=z_umap[:, 1],
hue=y_train,
palette="tab10",
s=20
)
plt.title("UMAP del espacio latente aprendido por el Autoencoder")
plt.xlabel("UMAP 1")
plt.ylabel("UMAP 2")
plt.legend(title="Dígito", bbox_to_anchor=(1.02, 1), loc="upper left")
plt.tight_layout()
plt.show()

Comparación entre PCA y UMAP sobre el embedding latente del autoencoder¶
Al proyectar el espacio latente de 32 dimensiones con PCA, observamos una nube con bastante solapamiento entre clases. Esto sugiere que la estructura del embedding aprendido por el autoencoder no se organiza principalmente de manera lineal en 2D.
En cambio, al aplicar UMAP sobre ese mismo embedding, emergen grupos mucho más definidos para varios dígitos. Esto indica que el autoencoder sí aprendió una representación latente informativa, pero su geometría parece ser más bien no lineal. UMAP logra revelar mejor esa estructura local y parte de la organización global del espacio aprendido.
Análisis de la representación UMAP del espacio latente¶
1. Clústeres bien definidos¶
- El dígito “1” (color naranjo) se agrupa de forma compacta y claramente separada a la izquierda → esto muestra que el autoencoder ha aprendido a representarlo como un patrón muy distintivo.
- Otros dígitos como “6”, “7”, “0” y “8” también tienen agrupaciones coherentes, aunque no totalmente aisladas.
2. Transiciones suaves entre dígitos parecidos¶
- Se observa cierta cercanía y fusión entre grupos como:
- “3” y “5”
- “4” y “9”
- “2” y “3”
- Esto es esperable, ya que estas clases comparten trazos visuales. El modelo tiende a representarlas en regiones vecinas del espacio latente.
3. Topología estructurada y no arbitraria¶
- La distribución general tiene forma orgánica, con ramificaciones y continuidad entre zonas → esto indica que UMAP está captando relaciones reales en el embedding aprendido, no simplemente separando arbitrariamente.
- No hay ruido visual o nubes caóticas → cada grupo tiene forma definida.
Conclusión¶
Este resultado indica que el autoencoder ha aprendido una representación latente útil y significativa: dígitos similares están cerca, diferentes están más separados, y la estructura global es coherente. UMAP proyecta esta estructura a 2D revelando el "mapa mental" aprendido por la red.
Explicación detallada del código Autoencoder vs PCA¶
Este notebook compara dos formas de reducir dimensionalidad y reconstruir imágenes:
- PCA: técnica lineal.
- Autoencoder: red neuronal no supervisada.
Importar librerías¶
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
numpy,matplotlib: procesamiento y visualización de datos.PCA: reducción lineal de dimensionalidad.tensorflow.keras: para construir y entrenar el autoencoder.
Cargar y preparar datos¶
(x_train, y_train), _ = mnist.load_data()
x_train = x_train[:2000].astype('float32') / 255.
x_train = x_train.reshape((len(x_train), -1))
y_train = y_train[:2000]
- MNIST: conjunto de dígitos manuscritos 28x28.
- Se usan solo 2000 imágenes para entrenamiento más rápido.
- Las imágenes se normalizan a $[0, 1]$ y se aplanan a vectores de 784 valores.
Aplicar PCA (baseline)¶
pca = PCA(n_components=32)
x_pca = pca.fit_transform(x_train)
x_pca_inv = pca.inverse_transform(x_pca)
- PCA busca los 32 componentes principales del conjunto de datos (reducción de $784 \rightarrow 32$).
x_pca_inv: reconstrucción a partir del embedding PCA.
Definición del Autoencoder profundo¶
from keras.models import Model
from keras.layers import Input, Dense
input_img = Input(shape=(784,))
# Encoder
x = Dense(128, activation='relu')(input_img)
x = Dense(64, activation='relu')(x)
encoded = Dense(32, activation='relu')(x)
# Decoder
x = Dense(64, activation='relu')(encoded)
x = Dense(128, activation='relu')(x)
decoded = Dense(784, activation='sigmoid')(x)
- Arquitectura simétrica (encoder → decoder).
- Embedding latente de 32 dimensiones.
- ReLU como activación en capas ocultas → permite modelar no linealidades.
- Sigmoid en la salida porque las imágenes están normalizadas en [0, 1].
Compilación y entrenamiento del modelo¶
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adam', loss='mse')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256, shuffle=True, verbose=1)
loss='mse': minimiza el error cuadrático medio entre imagen original y reconstrucción.optimizer='adam': optimizador estándar robusto y rápido.- 50 épocas → entrenamiento suficiente para que la red aprenda sin sobreajustar en 2000 datos.
batch_size=256: número de imágenes procesadas por paso.shuffle=True: reordena los datos entre épocas para mejor generalización.
Reconstrucción con Autoencoder¶
x_ae = autoencoder.predict(x_train[:10])
- Generamos reconstrucciones desde el autoencoder para las 10 primeras imágenes.
- Esto nos permitirá comparar visualmente con la reconstrucción de PCA.
Visualización comparativa¶
def plot_comparison(original, recon_pca, recon_ae):
...
plot_comparison(x_train[:10], x_pca_inv[:10], x_ae)
- Muestra:
- Fila 1: imágenes originales.
- Fila 2: reconstrucción usando PCA.
- Fila 3: reconstrucción usando Autoencoder.
- Permite comparar visualmente qué tan bien cada técnica logra conservar la información.
Ejercicio: Reconstruyendo Caras con un Autoencoder¶
En este ejercicio vamos a construir y entrenar un autoencoder totalmente conectado para aprender a reconstruir imágenes de caras de personas famosas usando el dataset lfw_people que viene con sklearn.
El objetivo es comprimir cada imagen a una representación más pequeña (embedding latente) y luego tratar de reconstruir la imagen original desde esa representación. Vamos a comparar visualmente las imágenes originales y sus versiones reconstruidas.
¿Qué vamos a hacer?¶
- Cargar y explorar un dataset real de imágenes de caras.
- Preprocesar las imágenes (aplanar y normalizar).
- Definir y entrenar un autoencoder profundo (con capas densas).
- Visualizar las imágenes originales vs las reconstruidas.
- Medir el error de reconstrucción usando el MSE (Mean Squared Error).
¿Qué aprenderás?¶
- Cómo usar un autoencoder para aprender representaciones compactas.
- Cómo trabajar con imágenes reales y redes neuronales densas.
- Cómo evaluar la calidad de una reconstrucción.
- ¡Y verás si el modelo puede reconstruir tu cara favorita!
Preguntas para pensar¶
- ¿Qué tan bien se ven las reconstrucciones? ¿Qué pierden?
- ¿Qué efecto tendría usar un espacio latente de 2 o de 100 dimensiones?
- ¿Podríamos usar estos embeddings para clustering o clasificación?
# ========================================================
# AUTOENCODER con dataset de caras famosas (LFW)
# ========================================================
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_lfw_people
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam
# tf.config.threading.set_intra_op_parallelism_threads(1)
# tf.config.threading.set_inter_op_parallelism_threads(1)
# ----------------------------
# 1. Cargar dataset de imágenes de caras
# ----------------------------
lfw = fetch_lfw_people(min_faces_per_person=40, resize=0.4)
X = lfw.images
n_samples, h, w = X.shape
print("Tamaño del dataset:", X.shape)
# ----------------------------
# 2. Aplanar y normalizar
# ----------------------------
X_flat = X.reshape((n_samples, h * w)).astype("float32") # sklearn ya devuelve los valores en [0, 255] como float32; verificar con X.max() antes de decidir si normalizar
# ----------------------------
# 3. Dividir en entrenamiento y prueba
# ----------------------------
X_train, X_test = train_test_split(X_flat, test_size=0.2, random_state=42)
# ----------------------------
# 4. Definir arquitectura del autoencoder
# ----------------------------
input_dim = X_flat.shape[1]
input_img = Input(shape=(input_dim,))
# Encoder
encoded = Dense(512, activation="relu")(input_img)
encoded = Dense(256, activation="relu")(encoded)
latent = Dense(128, activation="relu")(encoded)
# Decoder
decoded = Dense(256, activation="relu")(latent)
decoded = Dense(512, activation="relu")(decoded)
output_img = Dense(input_dim, activation="sigmoid")(decoded)
autoencoder = Model(input_img, output_img)
autoencoder.compile(optimizer=Adam(learning_rate=0.001), loss="mse")
# ----------------------------
# 5. Entrenar el autoencoder
# ----------------------------
history = autoencoder.fit(
X_train, X_train,
epochs=20,
batch_size=128,
shuffle=True,
validation_data=(X_test, X_test),
verbose=1
)
# ----------------------------
# 6. Obtener reconstrucciones
# ----------------------------
decoded_imgs = autoencoder.predict(X_test, verbose=0)
# ----------------------------
# 7. Visualización: Original vs Reconstruida
# ----------------------------
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(X_test[i].reshape((h, w)), cmap="gray")
plt.title("Original")
plt.axis("off")
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape((h, w)), cmap="gray")
plt.title("Reconstruida")
plt.axis("off")
plt.suptitle("Reconstrucción de caras usando Autoencoder")
plt.tight_layout()
plt.show()
# ----------------------------
# 8. Evaluar reconstrucción con MSE
# ----------------------------
mse = mean_squared_error(X_test, decoded_imgs)
print("Error cuadrático medio (MSE) en test:", round(mse, 5))
# ----------------------------
# 9. Graficar pérdida
# ----------------------------
plt.figure(figsize=(10, 4))
plt.plot(history.history["loss"], label="Entrenamiento")
plt.plot(history.history["val_loss"], label="Validación")
plt.xlabel("Época")
plt.ylabel("Pérdida (MSE)")
plt.title("Evolución de la pérdida del Autoencoder")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()


autoencoder.summary()
print("Min reconstrucción:", decoded_imgs.min())
print("Max reconstrucción:", decoded_imgs.max())
print("Min de normalizado X:", X_flat.min())
print("Max de normalizado X:", X_flat.max())
print("Min de todo X:", X.min())
print("Max de todo X:", X.max())
Este autoencoder recibe una imagen de entrada representada por 1850 píxeles y la comprime gradualmente a través del encoder:
$1850 \rightarrow 512 \rightarrow 256 \rightarrow 128$
La capa de 128 neuronas corresponde al espacio latente o bottleneck. Esa es la representación comprimida que la red aprende de cada cara. Luego, el decoder intenta reconstruir la imagen original recorriendo el camino inverso:
$128 \rightarrow 256 \rightarrow 512 \rightarrow 1850$
La arquitectura es simétrica, lo que la hace más fácil de interpretar: el encoder reduce dimensionalidad y el decoder expande esa representación para reconstruir la entrada.
Un punto importante es la gran cantidad de parámetros. Este modelo tiene más de 2.2 millones de parámetros entrenables, lo cual es mucho para un dataset relativamente pequeño como LFW. Esto ocurre porque las capas densas conectan cada neurona con todas las de la capa siguiente, y cuando la entrada tiene 1850 variables, el número de pesos crece muy rápido. Por ejemplo, solo la primera capa densa ya tiene cientos de miles de parámetros. Esto hace que el modelo tenga mucha capacidad, pero también aumenta el riesgo de sobreajuste y vuelve el entrenamiento más costoso computacionalmente.
Además, el resumen distingue entre tres tipos de parámetros:
- Trainable params: son los pesos y sesgos de la red que realmente se aprenden durante el entrenamiento.
- Non-trainable params: serían parámetros fijos que no se actualizan, pero aquí son 0.
- Optimizer params: no pertenecen a la arquitectura del autoencoder en sí, sino al optimizador Adam. Adam guarda información adicional para cada peso, como promedios móviles del gradiente y del cuadrado del gradiente. Es decir, además de almacenar el valor del peso, también guarda memoria sobre cómo ha venido cambiando ese peso durante el entrenamiento. Por eso el número de parámetros del optimizador puede ser incluso muy grande.
En otras palabras: los trainable params son lo que el modelo aprende como representación, mientras que los optimizer params son variables auxiliares que permiten entrenar mejor ese modelo. No forman parte directa de la red al momento de hacer predicciones, pero sí consumen memoria durante el entrenamiento.
Finalmente, los valores reportados abajo muestran que:
- la reconstrucción toma valores entre aproximadamente 0.018 y 0.908
- las imágenes de entrada están normalizadas entre 0 y 1
Esto es coherente con usar una capa final con activación sigmoid, ya que esa función restringe la salida al rango $[0,1]$, que coincide con la escala de las imágenes normalizadas.
¿Qué está pasando?¶
Aunque el código es correcto, hay dos causas principales técnicas que hacen que un autoencoder tradicional no sea lo más adecuado:
1. Arquitectura densa (fully connected) no es buena para imágenes¶
- Las imágenes tienen estructura espacial 2D (ojos, nariz, boca están en posiciones relativas fijas).
- Al aplanar con
.reshape(...), esa estructura se pierde completamente. Las capas densas no pueden capturar relaciones espaciales locales.
Por eso, aunque la pérdida baja, el modelo simplemente podría aprender a producir un promedio con ruido, y no una reconstrucción fiel.
2. La función de pérdida mse puede ser engañosa en imágenes¶
- Si el modelo produce valores muy pequeños (cerca de 0), el MSE será muy bajo.
- Pero eso no significa que la imagen tenga sentido: puede parecer ruido negro y aún así tener MSE = 0.001.
- Podría ocurrir que el modelo "aprende" a producir casi ceros → ruido oscuro.
Solución real: usar un autoencoder convolucional¶
Las convoluciones:
- Conservan la estructura espacial.
- Capturan patrones locales como bordes, ojos, nariz, boca.
- Funcionan mucho mejor para imágenes de rostros, incluso en redes pequeñas.
- Ya no trabajamos con capas desas clásicas, sino con capas convolucionales que manejan tensores.
Autoencoders Convolucionales¶
Ya vimos que un autoencoder aprende una función de identidad aproximada comprimiendo la entrada en un espacio latente y luego reconstruyéndola. El problema es que cuando la entrada son imágenes, la arquitectura densa que usamos hasta ahora tiene limitaciones estructurales importantes.
Función de pérdida (reconstrucción)¶
Se entrena para minimizar el error cuadrático medio (MSE):
$\mathcal{L}_{\text{recon}} = \frac{1}{n} \sum_{i=1}^n \| x_i - \hat{x}_i \|_2^2 = \frac{1}{n} \sum_{i=1}^n \| x_i - D(E(x_i)) \|_2^2$
Esto penaliza reconstrucciones que se alejan mucho del valor original por pixel.
¿Qué es una capa convolucional?¶
Una capa convolucional (Conv2D) es un tipo de capa que aplica un conjunto de filtros aprendibles sobre una imagen de entrada para extraer características locales como bordes, texturas o formas.
Piensa en una ventana que se desliza por una imagen.
Intuición de la convolución¶
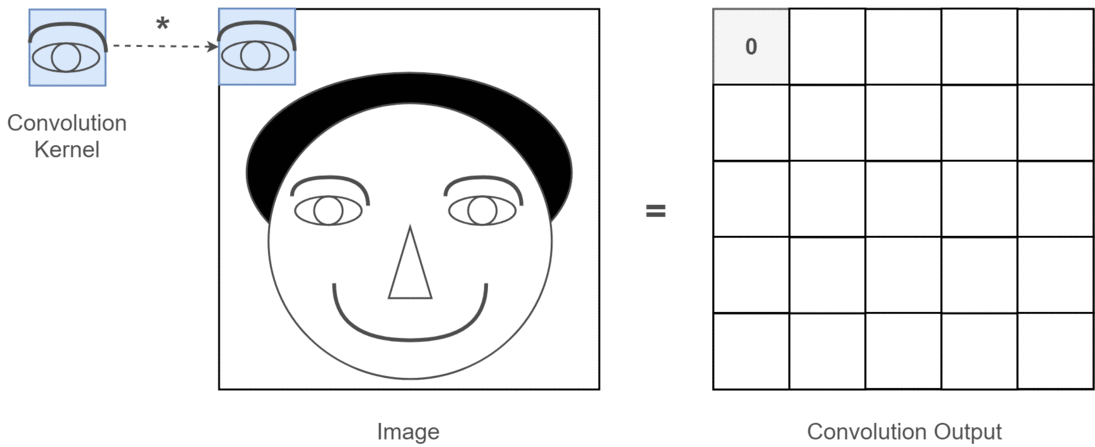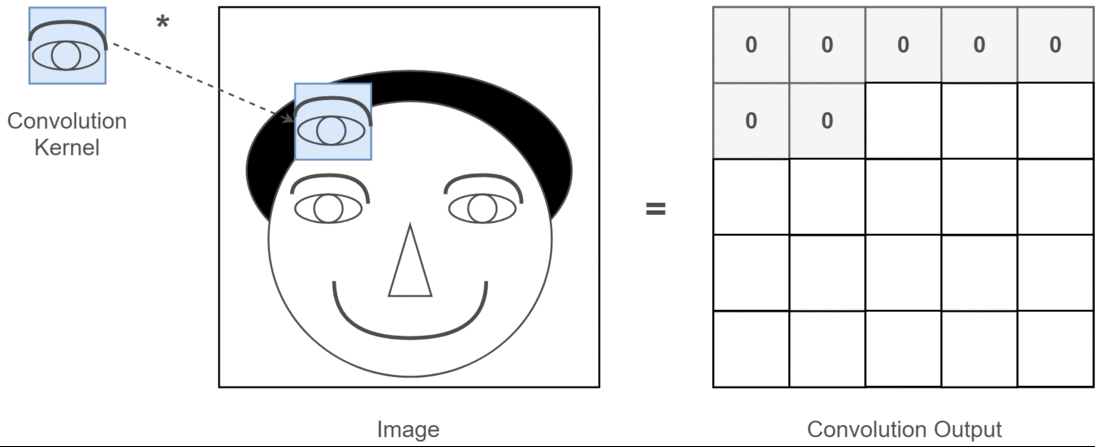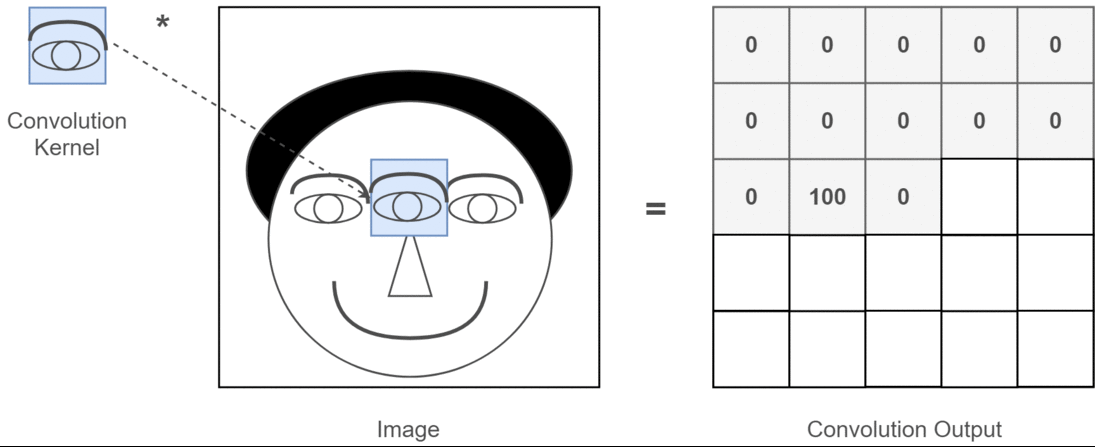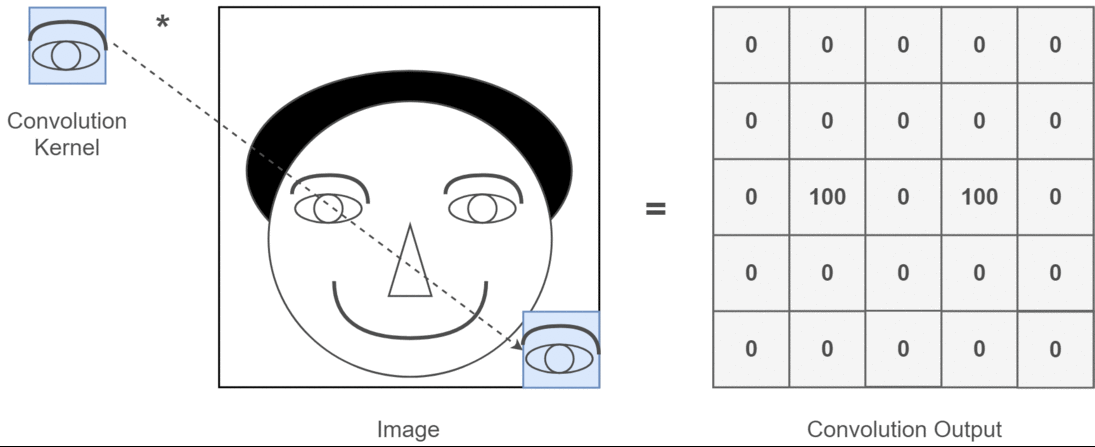
Imagina un pequeño patrón (filtro o kernel) que se desliza sobre toda la imagen. En cada posición, este patrón compara su contenido con la región local de la imagen y produce un número (una activación). En otras palabras, en cada posición, compara lo que “ve” con un pequeño filtro, y produce una salida numérica que resume esa comparación. Esto da lugar a un nuevo mapa de características (feature map).
Por ejemplo:
- Un filtro vertical activará fuertemente donde vea líneas verticales.
- Un filtro circular activará sobre ojos o bocas.
Cada filtro actúa como un detector de patrones específicos.
Definición matemática¶
Sea $ x \in \mathbb{R}^{H \times W} $ una imagen de entrada y $ k \in \mathbb{R}^{f \times f} $ un filtro de convolución (por ejemplo, $ 3 \times 3 $).
La convolución se define como:
$(x * k)(i, j) = \sum_{m=0}^{f-1} \sum_{n=0}^{f-1} x(i+m, j+n) \cdot k(m,n)$
Cada filtro se aplica sobre toda la imagen para generar un mapa de activación. El resultado es una nueva imagen (más pequeña) que contiene dónde el patrón fue detectado.
¿Qué hace esta fórmula?¶
- Tomas un parche de la imagen de tamaño $ f \times f $ en la posición $ (i, j) $.
- Multiplicas cada valor del parche por el valor correspondiente del filtro $ k $.
- Sumas todos los productos: ese número es la activación en la posición $ (i, j) $ del mapa de salida.
- Repites para cada posición de la imagen, deslizando el filtro.
Es como medir qué tan bien "calza" el patrón del filtro en cada región de la imagen.
¿Qué representa esta fórmula?¶
Cada valor de la salida es un producto punto entre:
Un subparche de la imagen de tamaño igual al kernel
El kernel
> Nota: Esto es cross-correlación, no convolución clásica (que implica voltear el kernel). Pero en deep learning usamos "convolución" como sinónimo de cross-correlación, ya que el kernel es entrenable. ¿Cuál es la diferencia? La convolución clásica voltea el kernel horizontal y verticalmente. La cross-correlación simplemente desliza el kernel sin voltearlo. En términos de resultado numérico, son distintos, pero solo si el kernel es fijo. ¿Y en redes neuronales? En redes neuronales los kernels no son fijos, ¡se entrenan! Eso significa que si el modelo necesita aprender un kernel que se vería como un kernel convolucional volteado lo aprenderá. Por tanto, la diferencia entre usar convolución o cross-correlación es irrelevante, porque los parámetros se adaptan durante el entrenamiento.Por eso: En Keras, PyTorch, TensorFlow, etc., lo que implementan como Conv2D es en realidad cross-correlation, pero por tradición se sigue llamando "convolución". En otras palbras, imagina que el kernel fuera una lupa. En matemáticas, le das vuelta antes de mirar. En deep learning, aprendes a mirar en la dirección que más te conviene.¶
¿Qué son los filtros (o kernels) en redes convolucionales?¶
Intuición¶
Los filtros (también llamados kernels) son pequeñas matrices de pesos aprendibles que se deslizan sobre la imagen para extraer patrones locales, como bordes, texturas o formas.
Cada filtro detecta una característica específica en la imagen.
Ejemplo visual¶
Un filtro de $ 3 \times 3 $:
$\text{Filtro (kernel)} =\begin{bmatrix}-1 & 0 & 1 \\-2 & 0 & 2 \\-1 & 0 & 1 \\\end{bmatrix}$
Esto detecta bordes verticales (¡es el clásico filtro de Sobel!).
Pero en una red neuronal… ¡el filtro no lo defines tú!
La red aprende automáticamente estos valores durante el entrenamiento.
Es decir, el filtro parte aleatorio y va adaptándose según la pérdida.
¿Cómo se usan?¶
La operación que aplica el filtro a la imagen es una convolución discreta (en práctica, es correlación cruzada):
$\text{Output}(i,j) = \sum_{u=0}^{k-1} \sum_{v=0}^{k-1} I(i+u, j+v) \cdot K(u,v)$
- $ I(i,j) $: imagen de entrada
- $ K(u,v) $: valores del filtro
- $ k $: tamaño del filtro (usualmente $ 3 \times 3 $ o $ 5 \times 5 $)
¿Qué significa "aprender" un filtro?¶
Durante el entrenamiento, los valores del filtro se ajustan para minimizar la función de pérdida (por ejemplo, el error de reconstrucción en un autoencoder).
Cada filtro termina especializándose:
- Filtro 1: aprende a detectar bordes horizontales
- Filtro 2: sombras suaves
- Filtro 3: formas circulares
- …
- Filtro 32: combinaciones abstractas de las anteriores
¿Cuántos filtros usamos?¶
Depende de cuántas características quieras que la red aprenda.
Por ejemplo:
Conv2D(filters=32, kernel_size=(3,3))
- Aquí defines 32 filtros de $ 3 \times 3 $
- Eso significa que la salida tendrá 32 canales
- Cada canal es la imagen filtrada por uno de esos 32 kernels
¿Cómo elegir cuántos filtros usar?¶
| Etapa de la red | Tamaño espacial | Cantidad típica de filtros | Intuición |
|---|---|---|---|
| Entrada | grande (e.g. 48×48) | 16 – 64 | Patrones simples |
| Medio | 24×24 – 12×12 | 64 – 128 | Patrones más complejos |
| Profunda | 6×6 – 3×3 | 128 – 512 | Combinaciones abstractas |
Más filtros = más capacidad de aprendizaje
Pero también más parámetros, más overfitting y más costo computacional
¿Cuántos parámetros tiene un filtro?¶
Para un filtro de tamaño $ k \times k $ y una entrada con $ C $ canales:
$\text{Parámetros por filtro} = k \cdot k \cdot C + 1 \text{ (bias)}$
Ejemplo:
- Imagen $ 48 \times 48 \times 1 $
- Capa
Conv2D(32, kernel_size=3)
$\text{Total parámetros} = (3 \cdot 3 \cdot 1 + 1) \cdot 32 = 320$
Conclusión¶
- Cada filtro es como una "lente" que busca un patrón
- La red aprende los valores de los filtros durante el entrenamiento
- Elegir cuántos filtros usar es un hiperparámetro clave
- Más filtros = más capacidad para representar características complejas
Ejemplo 1¶
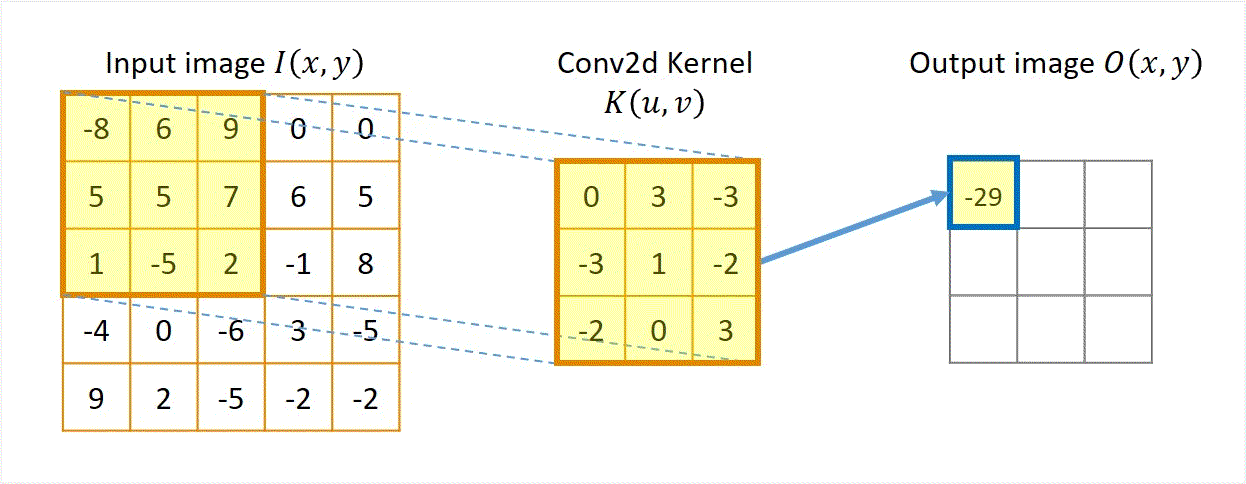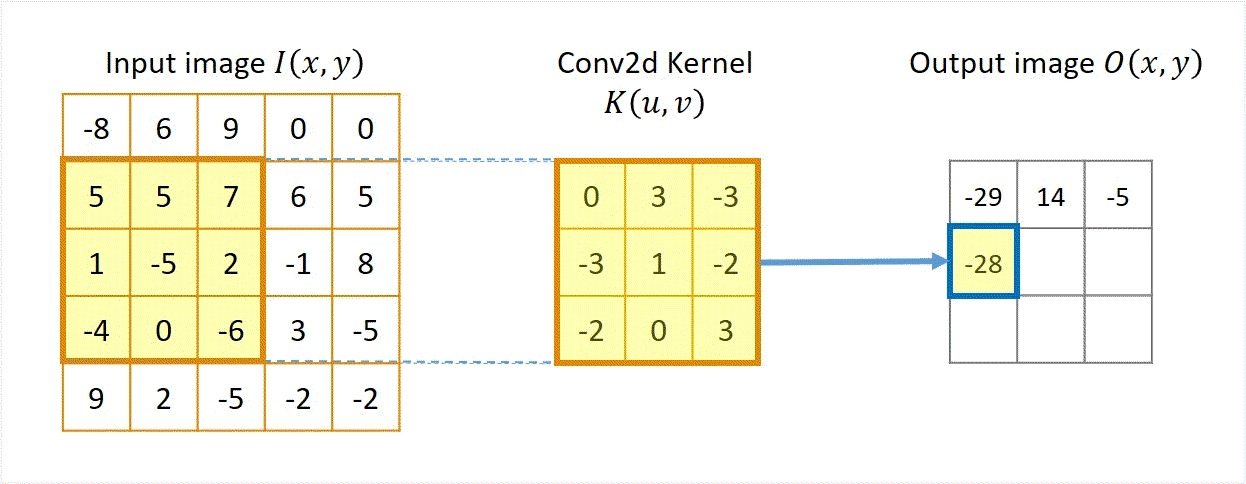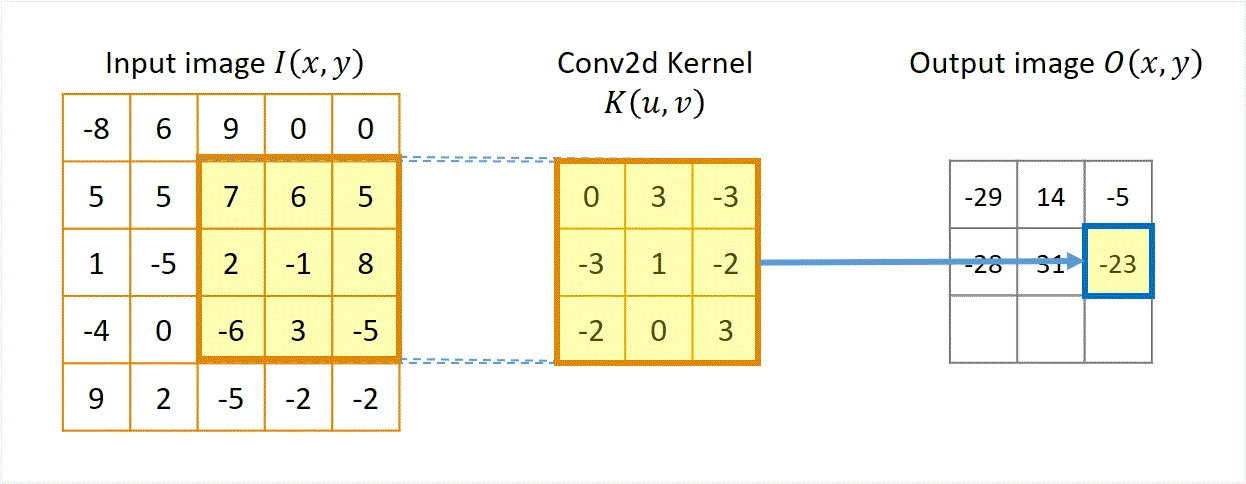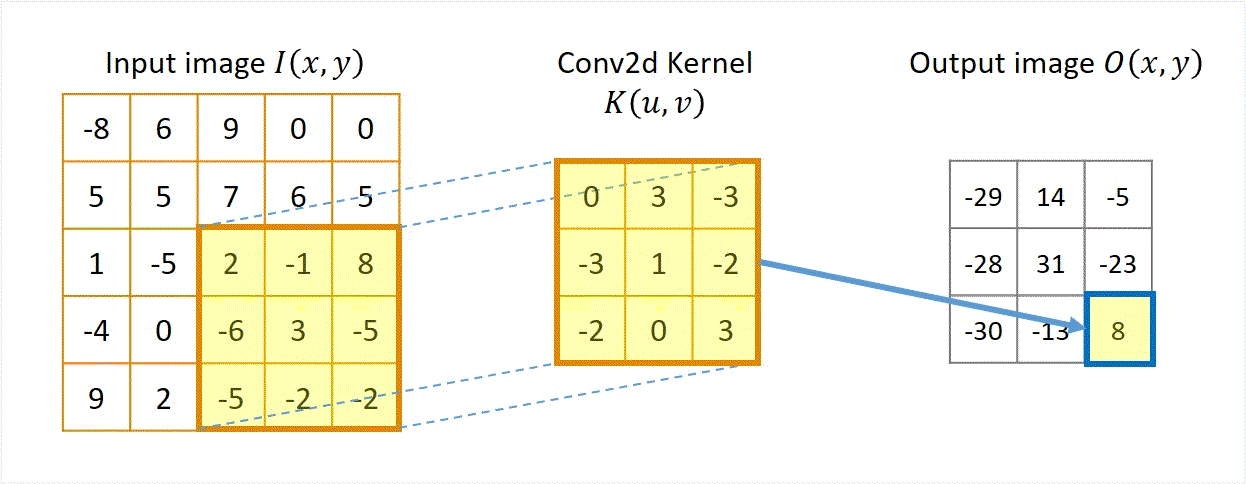
Output[3,1] ≈ patch . kernel¶
(1-0) + (-5 3) + (2 -3) + (-4-3) + (0 1) + (-6-2) + (9-2) + (2 0) + (-5* 3) = -30
Ejemplo 2¶
Supongamos que tenemos una imagen de entrada $ x \in \mathbb{R}^{4 \times 4} $:
$x = \begin{bmatrix}1 & 2 & 0 & 1 \\4 & 5 & 1 & 2 \\1 & 7 & 8 & 1 \\0 & 1 & 2 & 3\end{bmatrix}$
Y queremos aplicar el siguiente filtro $ k $ de detección de bordes verticales:
$k = \begin{bmatrix}-1 & 0 & 1 \\-1 & 0 & 1 \\-1 & 0 & 1\end{bmatrix}$
Paso 1: aplicar el filtro centrado en la esquina superior izquierda¶
Tomamos el primer parche $ 3 \times 3 $ de la imagen:
$\text{patch}_{(1,1)} = \begin{bmatrix}1 & 2 & 0 \\4 & 5 & 1 \\1 & 7 & 8\end{bmatrix}$
Multiplicamos elemento a elemento con el filtro y sumamos:
$(x * k)(1,1) =(-1)\cdot1 + 0\cdot2 + 1\cdot0 + (-1)\cdot4 + 0\cdot5 + 1\cdot1 + (-1)\cdot1 + 0\cdot7 + 1\cdot8$
$= -1 + 0 + 0 - 4 + 0 + 1 - 1 + 0 + 8 = \boxed{3}$
Paso 2: mover el filtro una columna a la derecha (stride = 1, tamaño salto 1)¶
Nuevo parche:
$\text{patch}_{(1,2)} = \begin{bmatrix}2 & 0 & 1 \\5 & 1 & 2 \\7 & 8 & 1\end{bmatrix}$
$$ (x * k)(1,2) = (-1)\cdot2 + 0\cdot0 + 1\cdot1 + (-1)\cdot5 + 0\cdot1 + 1\cdot2 + (-1)\cdot7 + 0\cdot8 + 1\cdot1 $$$$ = -2 + 0 + 1 -5 + 0 + 2 -7 + 0 + 1 = \boxed{-10} $$Resultado parcial del mapa de activación¶
Regla general¶
La dimensión de salida por eje es:
$$ \left\lfloor \frac{H - f + 2p}{s} \right\rfloor + 1 $$y análogamente para el ancho, donde:
- $H$ = alto de entrada (análogo para el ancho)
- $f$ = tamaño del filtro
- $p$ = padding
- $s$ = stride
Ejemplos rápidos¶
1. Sin padding, stride 1 entrada $32\times 32$, filtro $3\times 3$
$$ 30\times 30 $$2. Con padding 1, stride 1 entrada $32\times 32$, filtro $3\times 3$
$$ 32\times 32 $$3. Sin padding, stride 2 entrada $32\times 32$, filtro $3\times 3$
$$ 15\times 15 $$En nuestro caso anterior:
Con stride = 1 y sin padding, obtendremos una matriz de salida de tamaño $ 2 \times 2 $ (porque $ (4 - 3 +2*0)/1+ 1 = 2 $).
$$ x * k = \begin{bmatrix} 3 & -10 \\ ? & ? \end{bmatrix} $$(Se continua con las posiciones $ (2,1) $ y $ (2,2) $ para completar el mapa)
Intuición del resultado¶
- En la esquina superior izquierda, el filtro detectó un borde vertical débil → activación positiva.
- En la siguiente posición, encontró un borde fuerte pero opuesto → activación negativa.
- Las activaciones son altas donde el patrón del filtro se parece al parche, y bajas donde no.
¿Qué es el resultado?¶
- Un nuevo array (más pequeño), que llamamos mapa de activación o feature map.
- En él, cada valor representa cuánto se activó el filtro en esa zona.
- Es como un detector de patrones que responde cuando ve “algo familiar”.
En resumen:¶
| Elemento | Intuición |
|---|---|
| $ x $ | imagen original |
| $ k $ | lupa que busca un patrón |
| $ x * k $ | imagen nueva que muestra dónde el patrón fue detectado |
| $ (i, j) $ | posición donde se aplica el filtro |
| Resultado | Imagen más pequeña con activaciones |
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# Cargar y preparar datos (MNIST)
(x_train, y_train), (_, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.0
x_train = np.expand_dims(x_train, axis=-1)
model = Sequential([
Conv2D(8, (3, 3), activation='relu', input_shape=(28, 28, 1)),
MaxPooling2D(),
Flatten(),
Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.fit(x_train, y_train, epochs=3, batch_size=128)
# Visualizar filtros aprendidos (pesos de la primera capa Conv2D)
filters = model.layers[0].get_weights()[0] # (3, 3, 1, 8)
plt.figure(figsize=(10, 2))
for i in range(filters.shape[-1]):
f = filters[:, :, 0, i]
plt.subplot(1, 8, i+1)
plt.imshow(f, cmap='gray')
plt.axis('off')
plt.title(f"Filtro {i}")
plt.suptitle("Filtros aprendidos por la primera capa")
plt.tight_layout()
plt.show()

f.max()
Contexto matemático¶
Un filtro convolucional es una matriz de pesos que se multiplica (producto punto) con una pequeña región de la imagen de entrada. Esta operación se repite sobre toda la imagen (sliding window). El resultado es un mapa de activación que resalta ciertas características según el filtro.
Intuición y función de cada filtro¶
En general, interpretamos el tipo de patrón que aprende cada filtro, en función de sus valores (brillo = peso alto positivo; negro = negativo; gris = cerca de cero). Por ejemplo,
| Observación visual | Intuición / posible patrón que detecta |
|---|---|
| Gradiente claro a oscuro hacia derecha | Detecta transiciones horizontales claras → oscuras |
| Líneas horizontales con contraste | Posiblemente un borde horizontal |
| Líneas verticales con contraste | Borde vertical o transiciones fuertes de arriba a abajo |
¿Por qué son todos diferentes?¶
Cada filtro aprende a detectar una característica que ayude a minimizar la pérdida del modelo. Como esta es la primera capa, detectan patrones muy básicos como:
- Bordes
- Líneas
- Esquinas
- Contrastes locales
Estas características serán combinadas por capas posteriores para identificar formas más complejas (como un dígito o parte de una cara).
¿Cómo se aprenden?¶
- Inicialmente: cada filtro se inicializa con valores aleatorios.
- Durante el entrenamiento:
- Se hace forward pass: se aplica la convolución y se calcula la pérdida.
- Luego se hace backpropagation: el gradiente de la pérdida con respecto a cada valor del filtro se calcula y se ajustan los pesos del filtro con un optimizador (como Adam).
- Resultado: cada filtro encuentra una función útil para "responder" a un patrón particular en los datos.
¿Cómo se ve una capa convolucional?¶
En Keras, por ejemplo:
Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='same')
Esto significa:
- Se aplican 32 filtros distintos.
- Cada filtro es de tamaño $ 3 \times 3 $.
- El resultado son 32 mapas de activación de tamaño similar al de entrada.
- La activación
ReLUse aplica para introducir no linealidad. padding='same'se agregan ceros para mantener tamaño, convalidla salida es más pequeña.
¿Por qué son mejores que las capas densas para imágenes?¶
En autoencoders densos:¶
$$ x \in \mathbb{R}^{H \times W} \xrightarrow{\text{flatten}} \mathbb{R}^{HW} \xrightarrow{\text{densa}} \mathbb{R}^d $$- Se pierde la estructura espacial: se mezclan píxeles vecinos y lejanos sin distinción.
- Los patrones locales (bocas, bordes, esquinas) no se detectan.
- Todos los píxeles son tratados como si fueran independientes → se necesitan muchísimos parámetros.
En autoencoders convolucionales:¶
$$ x \in \mathbb{R}^{H \times W \times C} \xrightarrow{\text{Conv}} \mathbb{R}^{H' \times W' \times F} \xrightarrow{\text{Pooling}} \ldots $$- Se preserva la topología espacial (filas, columnas, profundidad)
- Cada filtro comparte pesos: solo se aprende un conjunto pequeño de pesos por filtro, no uno por píxel.
- Se capturan patrones locales repetibles (boca, nariz, cejas, etc.)
- Menos parámetros → menos overfitting, más eficiencia.
Reducción de dimensionalidad¶
Las capas MaxPooling2D reducen la resolución espacial de las imágenes, guardando solo lo más importante:
$$ \mathbb{R}^{48 \times 48 \times 32} \xrightarrow{\text{MaxPooling}} \mathbb{R}^{24 \times 24 \times 32} $$Cada bloque reduce un 2x2 a un 1x1 tomando el valor máximo.
- Captura la información más relevante.
- Reduce el tamaño de la imagen (y de la computación).
- Permite que el encoder se enfoque en estructuras más abstractas.
Esto forma parte del encoder.
Reconstrucción con upsampling¶
Para reconstruir la imagen, necesitamos aumentar resolución. Hay dos formas:
UpSampling2D: duplicar valores por interpolación.
Conv2DTranspose: también llamada deconvolución, aprende pesos.
Hasta llegar a:
$$ \hat{x} \in \mathbb{R}^{48 \times 48 \times 1} $$> Intuición: es como "inflar" la imagen comprimida para volver a su forma original.¶
Arquitectura convolucional simple para imágenes 48×48¶
Encoder¶
$$ x \in \mathbb{R}^{48 \times 48 \times 1} \xrightarrow{\text{Conv2D(32)}} \mathbb{R}^{48 \times 48 \times 32} \xrightarrow{\text{MaxPooling}} \mathbb{R}^{24 \times 24 \times 32} \xrightarrow{\text{Conv2D(64)}} \mathbb{R}^{24 \times 24 \times 64} \xrightarrow{\text{MaxPooling}} \mathbb{R}^{12 \times 12 \times 64} \xrightarrow{\text{Flatten + Dense}} z \in \mathbb{R}^{\text{latente}} $$Decoder (simétrico)¶
$$ z \in \mathbb{R}^{\text{latente}} \xrightarrow{\text{Dense + Reshape}} \mathbb{R}^{12 \times 12 \times 64} \xrightarrow{\text{UpSampling + Conv2D}} \mathbb{R}^{24 \times 24 \times 32} \xrightarrow{\text{UpSampling + Conv2D}} \mathbb{R}^{48 \times 48 \times 1} \Rightarrow \hat{x} $$Se reconstruye la imagen paso a paso descomprimiendo la representación latente.
Notar que pasamos de 1 canal a 32 y luego a 64. Esto significa que la red aprende múltiples filtros, cada uno produciendo un mapa de activación distinto. En capas tempranas, estos filtros suelen responder a patrones locales simples, como bordes o texturas. A medida que aumenta la profundidad, la red puede combinar estos patrones en representaciones más complejas. Incrementar el número de canales aumenta la capacidad representacional del modelo, aunque también incrementa su costo computacional.
Intuición general¶
| Parte | Qué hace |
|---|---|
| Conv2D | Aprende filtros que responden a patrones locales del input (detecta patrones locales como bordes, texturas, formas) |
| MaxPooling | Reduce la resolución espacial resumiendo activaciones locales (resume la imagen, reemplaza una ventana local por su valor máximo, reduciendo la resolución espacial y preservando la activación más alta en esa región). |
| Dense (latente) | Proyecta la representación intermedia a una representación latente compacta |
| UpSampling | Aumenta la resolución espacial de la representación, los detalles se refinan luego mediante convoluciones |
| Conv2D final | Produce la imagen reconstruida combinando las features decodificadas en un mapa de salida final |
En resumen:¶
| Elemento | Densa | Convolucional |
|---|---|---|
| Captura relaciones espaciales | ❌ No | ✅ Sí |
| Número de parámetros | Muy alto | Mucho menor |
| Preserva forma de imagen | ❌ No | ✅ Sí |
| Requiere flatten | ✅ Sí | ❌ No (sólo en el espacio latente h) |
| Eficiente en imágenes | ❌ No | ✅ Sí |
¿Qué aprende el modelo?¶
Formalmente, el autoencoder convolucional aprende una proyección no lineal:
$$ x \mapsto z = E(x) \in \mathcal{Z} \subset \mathbb{R}^d $$donde $ \mathcal{Z} $ es un espacio latente de dimensión reducida que captura lo más relevante de la imagen, y $ D(z) $ intenta reconstruir el original.
"El autoencoder aprende una función $ E $ que toma una entrada $ x $ (por ejemplo, una imagen) y la proyecta a una representación latente $ z $, que vive en un subconjunto $ \mathcal{Z} $ del espacio euclidiano de dimensión $ d $".
- $ x $: imagen original (por ejemplo, de tamaño $ 48 \times 48 $)
- $ E(x) = z $: encoder que genera el embedding o representación comprimida
- $ \mathcal{Z} \subset \mathbb{R}^d $: espacio latente donde se "condensa" la información más importante de las imágenes
Intuición¶
Un autoencoder convolucional está aprendiendo a representar imágenes complejas en un espacio más pequeño y manejable. Este espacio se llama espacio latente.
- Cada imagen $ x $ es mapeada a un vector $ z $, mucho más pequeño, que codifica lo esencial de la imagen (estructura facial, ubicación de ojos, boca, etc.).
- El decoder aprende a tomar ese vector $ z $ y "dibujar" de nuevo la imagen original (reconstrucción).
Ejemplo¶
Imagina que quieres reconocer personas con los ojos cerrados o en baja resolución. Lo que te interesa no es cada píxel exacto, sino las características importantes: forma de la cabeza, pelo, nariz, etc.
El encoder aprende a guardar eso (lo esencial) en $ z $.
Analogía¶
Es como si en vez de recordar una cara pixel por pixel, recordaras un boceto: forma del rostro, distancia entre ojos, sonrisa... Esa es la representación latente.
Propiedades clave de los autoencoders convolucionales¶
| Propiedad | Descripción |
|---|---|
| Invariancia local | Las convoluciones capturan patrones locales (bordes, texturas). |
| Compartición de pesos | Cada filtro aprende una sola función aplicada en toda la imagen. |
| Reducción de parámetros | Mucho menos parámetros que una red densa. |
| Preservación espacial | A diferencia del aplanado, se mantiene la estructura $2D$. |
¿Y por qué sirve esto?¶
Una vez entrenado, puedes:
- Visualizar las reconstrucciones para entender qué captó el modelo.
- Usar el espacio latente $ z $ para clustering, visualización con UMAP, o incluso como input para clasificación.
- Modificar la arquitectura para crear un denoising autoencoder, VAE, o generador de imágenes.
Entonces¶
El autoencoder convolucional aprende a comprimir imágenes de manera que aún se puedan reconstruir. Si lo hace bien, significa que captó la esencia visual de los datos, sin necesidad de etiquetas.
Nota sobre el decoder¶
El decoder puede realizar dos operaciones distintas por capas:
- subir resolución espacial
- recombinar canales para producir una nueva representación
Eso es lo que hacen UpSampling y Conv2D juntos.
La idea central¶
Supón que tienes un tensor en el decoder de tamaño:
$$[ 12 \times 12 \times 64 ]$$Eso significa:
- alto = 12
- ancho = 12
- canales = 64
Ahora quieres pasar, por ejemplo, a algo como: $$ [ 24 \times 24 \times 32 ] $$ Eso requiere dos cambios al mismo tiempo:
- subir de $12\times12$ a $24\times24$
- bajar de 64 canales a 32 canales
Una sola operación no necesariamente hace ambas cosas de la forma más clara. Por eso se separa:
Paso 1: UpSampling¶
Hace esto:
$$ [ 12 \times 12 \times 64 ;\to; 24 \times 24 \times 64 ] $$Sube alto y ancho, pero no cambia los canales.
¿Qué hace realmente UpSampling?¶
Toma cada pixel o activación y la “expande” espacialmente.
Por ejemplo, con UpSampling2D(size=2), un valor puede replicarse en un bloque $2\times2$.
Si antes tenías algo como: $$ [ \begin{bmatrix} 1 & 3\ 2 & 4 \end{bmatrix} ] $$ después de upsampling podría quedar:
$$ [ \begin{bmatrix} 1 & 1 & 3 & 3\ 1 & 1 & 3 & 3\ 2 & 2 & 4 & 4\ 2 & 2 & 4 & 4 \end{bmatrix} ] $$Eso pasa en cada canal.
Entonces si tenías 64 canales, sigues teniendo 64 canales, pero ahora cada mapa es más grande.
Paso 2: Conv2D¶
Luego aplicas una convolución:
$$ [ 24 \times 24 \times 64 ;\to; 24 \times 24 \times 32 ] $$Aquí:
- el tamaño espacial puede mantenerse si usas padding adecuado,
- pero el número de canales de salida lo decides con el número de filtros.
Si usas Conv2D(32, ...), produces 32 mapas de activación, así que la salida tiene 32 canales.
Entonces¶
- UpSampling: agranda el mapa
- Conv2D: mezcla información local y transforma el número de canales
Intuición de por qué van juntos¶
Después del upsampling, la imagen queda más grande pero “tosca”, como una versión agrandada sin refinamiento.
La convolución posterior sirve para:
- suavizar artefactos del upsampling,
- combinar los 64 canales entre sí,
- construir nuevos mapas más útiles,
- y además cambiar de 64 canales a 32.
Es decir:
UpSampling aumenta resolución, y Conv2D aprende cómo refinar esa resolución expandida.
Cómo una Conv2D baja canales¶
Esto es clave.
En una capa convolucional, cada filtro ve todos los canales de entrada.
Si la entrada es:
$$ [ 24 \times 24 \times 64 ] $$y usas 32 filtros de tamaño $3\times3$, entonces cada filtro tiene tamaño:
$$ [ 3 \times 3 \times 64 ] $$Cada uno produce un mapa de salida.
Entonces:
- 1 filtro $\to$ 1 canal de salida
- 32 filtros $\to$ 32 canales de salida
Por eso:
$$ [ 24 \times 24 \times 64 ;\xrightarrow{\text{Conv2D}(32)}; 24 \times 24 \times 32 ] $$No está “borrando” canales uno a uno. Está aprendiendo 32 nuevas combinaciones de los 64 canales anteriores.
Ejemplo completo del decoder¶
Supón:
$$ [ z \to 12 \times 12 \times 64 ] $$Luego:
Bloque 1¶
$$ [ 12\times12\times64 ;\xrightarrow{\text{UpSampling}} 24\times24\times64 ] $$$$ [ 24\times24\times64 ;\xrightarrow{\text{Conv2D}(32)} 24\times24\times32 ] $$Bloque 2¶
$$ [ 24\times24\times32 ;\xrightarrow{\text{UpSampling}} 48\times48\times32 ] $$$$ [ 48\times48\times32 ;\xrightarrow{\text{Conv2D}(1)} 48\times48\times1 ] $$Y eso ya parece una imagen reconstruida.
Intuición visual¶
Piensa así:
- UpSampling = “estirar” el lienzo
- Conv2D = “repintar y reorganizar” la información sobre ese lienzo
O más técnico:
- UpSampling aumenta soporte espacial
- Conv2D refina estructura local y proyecta a nuevos canales
Lo que no hace UpSampling¶
UpSampling por sí solo no inventa detalle fino inteligentemente. Solo agranda la representación.
La parte “inteligente” viene de la convolución aprendida después.
Entonces¶
En el decoder,
UpSamplingaumenta la resolución espacial de los mapas de activación, pero mantiene fijo el número de canales. Luego,Conv2Drefina esa representación expandida y produce un nuevo conjunto de canales aprendidos. Así, el decoder puede aumentar alto y ancho mientras reorganiza progresivamente la información hasta reconstruir la imagen.
En simple¶
Primero agrando el mapa, después uso convoluciones para limpiarlo, refinarlo y cambiar el número de canales.
Ejercicio: Reconstruyendo caras con un Autoencoder Convolucional¶
En este ejercicio trabajaremos con un autoencoder convolucional para aprender representaciones comprimidas de imágenes de rostros humanos usando el dataset lfw_people (caras famosas) que viene en sklearn.
El objetivo es que el modelo aprenda a comprimir una imagen y luego reconstruirla lo mejor posible desde esa representación latente.
Objetivos del ejercicio¶
- Construir un autoencoder convolucional que capture patrones visuales como ojos, nariz y boca.
- Entrenar el modelo para minimizar el error de reconstrucción (MSE).
- Visualizar y comparar caras originales vs reconstruidas.
- Evaluar qué tan bien el modelo aprendió observando los resultados y la función de pérdida.
¿Qué usamos?¶
Conv2DyMaxPooling2Dpara codificar (encoder).UpSampling2DyConv2Dpara reconstruir (decoder).- Pérdida:
mse(error cuadrático medio). - Dataset: imágenes 62×47 en escala de grises.
Preguntas para reflexionar¶
- ¿Qué ventajas tiene usar convoluciones sobre capas densas en tareas visuales?
- ¿Qué tan bien se conservan los rasgos faciales después de la reconstrucción?
- ¿Podríamos usar la representación latente para otras tareas como clasificación o clustering?
Posibles extensiones¶
- Cambiar el tamaño del espacio latente (más compresión).
- Visualizar el espacio latente con UMAP o t-SNE.
- Usar regularización (dropout, sparsity, etc.).
# ========================================================
# AUTOENCODER CONVOLUCIONAL FUNCIONAL con dataset de caras LFW
# ========================================================
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_lfw_people
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from skimage.transform import resize
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D
from tensorflow.keras.optimizers import Adam
# ----------------------------
# 1. Cargar dataset y reescalar imágenes a 48x48
# ----------------------------
lfw = fetch_lfw_people(min_faces_per_person=40, resize=1.0)
X_raw = lfw.images # (n, h_original, w_original)
# Redimensionamos cada imagen a 48x48 (manteniendo escala de grises)
X = np.array([resize(img, (48, 48), anti_aliasing=True) for img in X_raw])
# Normalizamos a [0, 1] #si ya vienen normalizadas solo dejar en float
print("Min de todo X:", X.min())
print("Max de todo X:", X.max())
X = X.astype('float32') # skimage.resize normaliza a [0, 1] automáticamente
# Agregamos dimensión del canal → (n, 48, 48, 1)
X = np.expand_dims(X, axis=-1)
# Confirmamos dimensiones
n_samples, h, w, c = X.shape
print("Número de imágenes en el dataset:", X.shape[0])
print("Tamaño del dataset:", X.shape)
# ----------------------------
# 2. Dividir en entrenamiento y test
# ----------------------------
X_train, X_test = train_test_split(X, test_size=0.2, random_state=42)
# ----------------------------
# 3. Definir el modelo de Autoencoder Convolucional
# ----------------------------
input_img = Input(shape=(h, w, c)) # (48, 48, 1)
# Encoder
x = Conv2D(64, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x) # → 24x24
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x) # → 12x12
# Decoder
x = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x) # 12x12 → 24x24
x = Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x) # 24x24 → 48x48
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
# Modelo
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer=Adam(learning_rate=0.0001), loss='mse')#mae #mse #La función mse tiende a producir imágenes borrosas.
# binary_crossentropy: si los valores están en [0,1] y tienes fondo negro/blanco.
# mae: puede dar más nitidez en algunos casos.
# ----------------------------
# 4. Entrenar el modelo
# ----------------------------
history = autoencoder.fit(X_train, X_train,
epochs=50,
batch_size=64,
shuffle=True,
validation_data=(X_test, X_test),
verbose=1)
# ----------------------------
# 5. Visualización de reconstrucciones
# ----------------------------
decoded_imgs = autoencoder.predict(X_test)
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# Original
ax = plt.subplot(2, n, i + 1)
plt.imshow(X_test[i].reshape(h, w), cmap='gray')
plt.title("Original")
plt.axis('off')
# Reconstruida
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(h, w), cmap='gray')
plt.title("Reconstruida")
plt.axis('off')
plt.suptitle("Reconstrucción de caras con Autoencoder Convolucional (ajustado)")
plt.tight_layout()
plt.show()
# ----------------------------
# 6. Evaluar con MSE
# ----------------------------
mse = mean_squared_error(X_test.reshape(len(X_test), -1),
decoded_imgs.reshape(len(decoded_imgs), -1))
print("Función de pérdida\n (puede ser error cuadrático medio, MSE) en test:", round(mse, 5))
# ----------------------------
# 7. Evolución de la pérdida
# ----------------------------
plt.figure(figsize=(10, 4))
plt.plot(history.history['loss'], label='Entrenamiento')
plt.plot(history.history['val_loss'], label='Validación')
plt.xlabel("Época")
plt.ylabel("Pérdida (MSE)")
plt.title("Evolución de la pérdida del Autoencoder Convolucional")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()


Reconstrucción de imágenes¶
La parte superior muestra:
- Imagen original: las caras reales del dataset (ej. LFW)
- Imagen reconstruida: lo que el modelo logra reconstruir al pasar la imagen por el codificador → espacio latente → decodificador
¿Qué se observa?¶
- Las reconstrucciones son bastante fieles, aunque ligeramente borrosas
- Rasgos generales como posición de los ojos, boca, nariz, forma de la cara están bien capturados
- Detalles finos (textura del cabello, arrugas) no se preservan
¿Por qué ocurre esto?¶
Porque los autoencoders están limitados por el tamaño del espacio latente (y filtros) y tienden a aprender solo las características más relevantes y repetibles. El modelo descarta detalles que considera menos útiles para minimizar la pérdida.
2. Función de pérdida (MSE)¶
La curva de pérdida representa cómo el modelo va mejorando su capacidad de reconstrucción a lo largo del tiempo.
¿Qué es el MSE?¶
$$ \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (x_i - \hat{x}_i)^2 $$Donde:
- $ x_i $: valor del pixel original
- $ \hat{x}_i $: valor reconstruido por el autoencoder
- $ n $: número total de píxeles
MSE mide la distancia promedio entre la imagen original y la reconstruida. Cuanto más bajo, mejor.
Curva de entrenamiento y validación:¶
- Ambas disminuyen rápidamente → el modelo aprende bien.
- No hay divergencia entre entrenamiento y validación → no hay sobreajuste.
Valor final:¶
$$ \text{MSE en test} \approx 0.0022 $$Eso es bastante bajo para imágenes normalizadas en $[0,1]$: el modelo reconstruye bien la estructura global de las caras, aunque todavía suaviza detalles finos.
¿Qué representa esto en términos de aprendizaje?¶
Este gráfico muestra que el autoencoder ha aprendido una buena representación latente del conjunto de caras:
- Comprime las imágenes en un espacio de menor dimensión (reducción de dimensionalidad)
- Desde ahí puede reconstruir una versión aproximada con muy bajo error
¿Cómo se puede mejorar?¶
Una hipótesis razonable sería aumentar filtros o profundidad. Pero esto no garantiza mejora automática: hay que comparar contra una métrica y contra la visualización. En la siguiente prueba vamos a usar una arquitectura más grande y veremos que, en esta corrida, el resultado es muy parecido al modelo simple.
Esto es una lección importante: más parámetros no siempre significan mejores reconstrucciones.
Algunos checks¶
autoencoder.summary()
print("Min reconstrucción:", decoded_imgs.min())
print("Max reconstrucción:", decoded_imgs.max())
print("Min de todo X:", X.min())
print("Max de todo X:", X.max())
Los autoencoders convolucionales aprenden una representación comprimida preservando la estructura espacial de la imagen. Sin embargo, la calidad de reconstrucción no depende solo de hacer la red más profunda: también importan el cuello de botella, la función de pérdida, el tamaño del dataset y la regularización. Pérdidas como mse tienden a suavizar detalles, y una arquitectura más grande puede capturar patrones más complejos, pero solo si esa capacidad extra se traduce en mejor generalización.
Arquitectura del Autoencoder Convolucional¶
Input¶
input_img = Input(shape=(48, 48, 1))
Recibimos imágenes de tamaño 48x48 en escala de grises (1 canal).
Encoder: compactar la información¶
Este bloque reduce la dimensionalidad de la imagen, manteniendo la estructura local (bordes, texturas, etc).
x = Conv2D(64, (3, 3), activation='relu', padding='same')(input_img)
- Aplica 64 filtros convolucionales de tamaño 3x3.
- Usa
padding='same', así que el tamaño de la imagen no cambia: 48×48 → 48×48. - Usa activación ReLU, que deja pasar valores positivos.
x = MaxPooling2D((2, 2), padding='same')(x)
- Reduce tamaño a la mitad: 48×48 → 24×24.
- Se queda con lo más representativo de cada bloque de 2×2.
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
- Segunda convolución: 32 filtros.
- Segunda reducción: 24×24 → 12×12.
Resultado: una representación compacta y densa de la imagen en un espacio latente de tamaño 12×12×32.
encoded = ...
Decoder: reconstruir la imagen¶
Ahora vamos a descomprimir la representación anterior paso a paso.
x = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
- Convolución + duplicación de tamaño: 12×12 → 24×24
x = Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
- Otra capa de reconstrucción: 24×24 → 48×48
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
- Filtro final con 1 canal (imagen reconstruida).
sigmoidasegura que los valores queden entre 0 y 1, igual que la imagen original.
Modelo final¶
autoencoder = Model(input_img, decoded)
Este modelo va de una imagen a su reconstrucción.
¿Cómo ver la arquitectura?¶
autoencoder.summary()
Esto imprimirá una tabla como esta:
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 48, 48, 1)] 0
conv2d (Conv2D) (None, 48, 48, 64) ...
max_pooling2d (MaxPooling2D) (None, 24, 24, 64) 0
...
conv2d_5 (Conv2D) (None, 48, 48, 1) ...
=================================================================
Total params: XXXXXX
Trainable params: XXXXXXDiagrama visual¶
Si quieres generar un gráfico con la arquitectura, puedes usar:
from tensorflow.keras.utils import plot_model
plot_model(autoencoder, show_shapes=True, show_layer_names=True)
# !pip install pydot
# conda install anaconda::graphviz
from tensorflow.keras.utils import plot_model
plot_model(autoencoder, show_shapes=True, show_layer_names=True)

Probamos con más capacidad: ¿mejora realmente?¶
Ahora vamos a entrenar un autoencoder convolucional más profundo. La intuición inicial podría ser: si agregamos más filtros, más capas y Batch Normalization, deberíamos obtener mejores reconstrucciones.
Pero esa es justamente la pregunta que queremos poner a prueba. En machine learning no basta con que una arquitectura sea más grande: debe mejorar en validación/test o entregar una mejora visual clara.
# ========================================================
# AUTOENCODER CONVOLUCIONAL AVANZADO CON LFW
# ========================================================
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_lfw_people
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from skimage.transform import resize
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, BatchNormalization, Activation
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
from tensorflow.keras.optimizers import Adam
np.random.seed(42)
tf.random.set_seed(42)
# ----------------------------
# 1. Cargar y preprocesar imagenes (48x48 en escala de grises)
# ----------------------------
lfw = fetch_lfw_people(min_faces_per_person=40, resize=1.0)
X_raw = lfw.images
# Redimensionar manteniendo el rango original y luego normalizar a [0, 1]
X = np.array([
resize(img, (48, 48), anti_aliasing=True, preserve_range=True)
for img in X_raw
], dtype="float32")
if X.max() > 1.0:
X = X / 255.0
X = np.clip(X, 0.0, 1.0)
X = np.expand_dims(X, axis=-1) # (n, 48, 48, 1)
print("Min X:", X.min(), " - Max X:", X.max())
print("Shape:", X.shape)
# ----------------------------
# 2. Dividir en entrenamiento y test
# ----------------------------
X_train, X_test = train_test_split(X, test_size=0.2, random_state=42)
# ----------------------------
# 3. Arquitectura del Autoencoder Convolucional Profundo
# ----------------------------
def conv_block(x, filters):
x = Conv2D(filters, (3, 3), padding="same", use_bias=False)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation("relu")(x)
x = Conv2D(filters, (3, 3), padding="same", use_bias=False)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation("relu")(x)
return x
input_img = Input(shape=(48, 48, 1))
# Encoder: al bajar resolucion espacial aumentamos filtros.
x = conv_block(input_img, 32)
x = MaxPooling2D((2, 2), padding="same")(x) # 48x48 -> 24x24
x = conv_block(x, 64)
x = MaxPooling2D((2, 2), padding="same")(x) # 24x24 -> 12x12
x = conv_block(x, 128)
encoded = MaxPooling2D((2, 2), padding="same", name="embedding_6x6x128")(x) # 12x12 -> 6x6
# Decoder: reconstruimos invirtiendo la piramide de resoluciones.
x = conv_block(encoded, 128)
x = UpSampling2D((2, 2))(x) # 6x6 -> 12x12
x = conv_block(x, 64)
x = UpSampling2D((2, 2))(x) # 12x12 -> 24x24
x = conv_block(x, 32)
x = UpSampling2D((2, 2))(x) # 24x24 -> 48x48
decoded = Conv2D(1, (3, 3), activation="sigmoid", padding="same")(x)
# ----------------------------
# 4. Compilar y configurar callbacks
# ----------------------------
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer=Adam(learning_rate=0.001), loss="mse")
latent_shape = autoencoder.get_layer("embedding_6x6x128").output.shape[1:]
latent_dim = int(np.prod(latent_shape))
print(f"Espacio latente: {latent_shape} = {latent_dim} valores")
callbacks = [
EarlyStopping(monitor="val_loss", patience=15, min_delta=1e-4, restore_best_weights=True),
ReduceLROnPlateau(monitor="val_loss", factor=0.5, patience=5, min_lr=1e-5, verbose=1),
ModelCheckpoint("best_autoencoder.keras", monitor="val_loss", save_best_only=True)
]
# ----------------------------
# 5. Entrenar el modelo
# ----------------------------
history = autoencoder.fit(
X_train, X_train,
epochs=100,
batch_size=64,
shuffle=True,
validation_data=(X_test, X_test),
callbacks=callbacks,
verbose=1
)
# ----------------------------
# 6. Evaluar y visualizar reconstrucciones
# ----------------------------
decoded_imgs = autoencoder.predict(X_test, verbose=0)
n = min(10, len(X_test))
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(X_test[i].reshape(48, 48), cmap="gray")
plt.title("Original")
plt.axis("off")
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(48, 48), cmap="gray")
plt.title("Reconstruida")
plt.axis("off")
plt.suptitle("Reconstruccion de caras con Autoencoder Convolucional Avanzado")
plt.tight_layout()
plt.show()
# ----------------------------
# 7. Evaluar error
# ----------------------------
mse = mean_squared_error(
X_test.reshape(len(X_test), -1),
decoded_imgs.reshape(len(decoded_imgs), -1)
)
print("Error cuadratico medio (MSE) en test:", round(mse, 5))
# ----------------------------
# 8. Visualizar evolucion de la perdida
# ----------------------------
plt.figure(figsize=(10, 4))
plt.plot(history.history["loss"], label="Entrenamiento")
plt.plot(history.history["val_loss"], label="Validacion")
plt.xlabel("Epoca")
plt.ylabel("Perdida (MSE)")
plt.title("Evolucion de la perdida del Autoencoder Convolucional")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()


Conclusión: más capacidad no siempre mejora¶
Comparemos los dos autoencoders convolucionales entrenados sobre las mismas caras LFW redimensionadas a $48 \times 48$:
| Modelo | Cuello de botella | Parámetros aprox. | MSE en test |
|---|---|---|---|
| Convolucional simple | $12 \times 12 \times 32 = 4608$ valores | 147 mil | 0.00248 |
| Convolucional avanzado | $6 \times 6 \times 128 = 4608$ valores | 721 mil | 0.00286 |
La conclusión es que el modelo avanzado no mejora de forma clara. De hecho, en esta corrida obtiene un MSE levemente mayor, aunque visualmente las reconstrucciones se ven bastante parecidas.
¿Por qué puede pasar esto?
- Ambos modelos tienen un cuello de botella con la misma cantidad total de valores: 4608.
- El modelo avanzado tiene muchos más parámetros, pero esa capacidad extra no necesariamente ayuda si el modelo simple ya captura la estructura principal de las caras.
- La pérdida
msepremia reconstrucciones promedio y suaves; por eso diferencias finas de textura pueden no reflejarse bien en la métrica. - Con un dataset relativamente pequeño, una red más grande puede ser más difícil de optimizar o generalizar.
La lección importante es esta:
Más profundo no significa automáticamente mejor. En autoencoders, la calidad depende del balance entre arquitectura, cuello de botella, datos, función de pérdida y objetivo pedagógico. Si el modelo simple reconstruye casi igual y tiene muchos menos parámetros, puede ser la mejor opción para explicar la idea central.
Para mejorar de verdad, no bastaría con agregar capas. Habría que cambiar la pregunta experimental: por ejemplo, usar un cuello de botella más restrictivo, comparar con SSIM, usar una pérdida perceptual, aumentar datos, o evaluar si el embedding sirve para clustering o clasificación.
Intuición de la arquitectura avanzada¶
Esta arquitectura sirve para mostrar cómo se construye un autoencoder convolucional más profundo. La idea no es afirmar que será automáticamente mejor, sino observar cómo cambia el diseño cuando agregamos capacidad. Debe equilibrar dos cosas:
- Capacidad: más filtros y más capas para intentar modelar ojos, boca, nariz, contornos y textura.
- Compresión: un cuello de botella suficientemente restrictivo para que aprenda una representación, pero no tan pequeño que destruya la información necesaria para reconstruir.
Por eso este modelo usa una pirámide convolucional:
48x48x1 -> 24x24x32 -> 12x12x64 -> 6x6x128
El embedding sigue siendo espacialmente compacto (6x6), pero aumenta canales (128). Notar que esto mantiene la misma cantidad total de valores latentes que el modelo simple: $6 \times 6 \times 128 = 12 \times 12 \times 32 = 4608$.
Arquitectura del Autoencoder Convolucional Profundo¶
Este modelo es un autoencoder convolucional: recibe una imagen de entrada, la transforma en una representación interna o embedding, y luego intenta reconstruir la imagen original.
La entrada es una imagen en escala de grises de tamaño $48 \times 48 \times 1$.
1. Bloque convolucional básico¶
El bloque conv_block(x, filters) aplica dos veces la misma secuencia para aprender patrones visuales más complejos antes de reducir la resolución con MaxPooling:
$ \text{Conv2D} \rightarrow \text{BatchNormalization} \rightarrow \text{ReLU} $
En términos prácticos:
Conv2D(filters, (3,3), padding="same")aprende patrones locales de la imagen.padding="same"mantiene el tamaño espacial de la imagen.BatchNormalizationestabiliza el entrenamiento normalizando las activaciones internas.ReLUintroduce no linealidad y deja pasar sólo activaciones positivas.use_bias=Falsees razonable porqueBatchNormalizationya incorpora un término de desplazamiento.
Cada bloque mantiene la resolución espacial, pero cambia la cantidad de canales según el número de filtros.
2. Encoder: comprimir espacialmente la imagen¶
El encoder reduce progresivamente la resolución espacial usando MaxPooling2D.
| Etapa | Operación | Salida |
|---|---|---|
| Entrada | Imagen original | $48 \times 48 \times 1$ |
| Bloque conv 32 | Aprende 32 mapas de activación | $48 \times 48 \times 32$ |
| MaxPooling | Reduce resolución a la mitad | $24 \times 24 \times 32$ |
| Bloque conv 64 | Aprende patrones más abstractos | $24 \times 24 \times 64$ |
| MaxPooling | Reduce resolución a la mitad | $12 \times 12 \times 64$ |
| Bloque conv 128 | Aprende patrones de mayor nivel | $12 \times 12 \times 128$ |
| MaxPooling | Genera el embedding | $6 \times 6 \times 128$ |
La idea central es que, a medida que baja la resolución espacial, el modelo aumenta el número de filtros. Es decir, pierde detalle espacial fino, pero gana capacidad para representar patrones más abstractos.
El embedding final es:
$6 \times 6 \times 128$
Esto puede interpretarse como una representación compacta en términos espaciales: la imagen original de $48 \times 48$ se resume en una grilla de $6 \times 6$, donde cada posición tiene 128 características aprendidas.
3. Decoder: reconstruir la imagen¶
El decoder invierte la pirámide del encoder. Parte desde el embedding y recupera progresivamente la resolución espacial usando UpSampling2D.
| Etapa | Operación | Salida |
|---|---|---|
| Embedding | Representación interna | $6 \times 6 \times 128$ |
| Bloque conv 128 | Refina la representación latente | $6 \times 6 \times 128$ |
| UpSampling | Duplica la resolución espacial | $12 \times 12 \times 128$ |
| Bloque conv 64 | Reduce canales y organiza información | $12 \times 12 \times 64$ |
| UpSampling | Duplica la resolución espacial | $24 \times 24 \times 64$ |
| Bloque conv 32 | Refina detalles locales | $24 \times 24 \times 32$ |
| UpSampling | Recupera tamaño original | $48 \times 48 \times 32$ |
| Conv2D final | Reconstruye una imagen de 1 canal | $48 \times 48 \times 1$ |
UpSampling2D no aprende parámetros: simplemente aumenta la resolución espacial. Las capas convolucionales posteriores son las que aprenden a transformar esa representación ampliada en una reconstrucción más coherente.
4. Capa de salida¶
La última capa es:
$ \text{Conv2D}(1, 3 \times 3, \text{sigmoid}) $
Produce una imagen reconstruida de tamaño $48 \times 48 \times 1$.
La activación sigmoid fuerza los valores de salida al intervalo $[0,1]$, lo cual es consistente si las imágenes de entrada fueron normalizadas dividiendo los píxeles por 255.
5. Idea general¶
El autoencoder aprende una función de codificación y decodificación:
$ \text{imagen original} \rightarrow \text{embedding} \rightarrow \text{imagen reconstruida} $
El objetivo no es clasificar la imagen, sino reconstruirla. Para hacerlo bien, el modelo debe aprender una representación interna que capture las estructuras relevantes de la imagen: bordes, texturas, formas locales y patrones espaciales.
6. Nota importante¶
Aunque el embedding tiene menor resolución espacial, no necesariamente tiene menos valores totales que la imagen original.
La imagen original tiene:
$48 \times 48 \times 1 = 2304$ valores
El embedding tiene:
$6 \times 6 \times 128 = 4608$ valores
Por lo tanto, esta arquitectura comprime espacialmente, pero no reduce la dimensionalidad total en sentido estricto. Es un cuello de botella espacial, no necesariamente un cuello de botella dimensional. Si se busca una compresión más fuerte, habría que reducir más la resolución, disminuir canales o agregar una capa densa latente más pequeña.
Qué deberías observar¶
Al entrenarlo, el MSE de test debería ser comparable o menor que el del ejemplo convolucional anterior. Si no baja claramente, conviene mirar primero:
- si
val_lossdisminuye de forma sostenida, - si
EarlyStoppingestá cortando demasiado temprano, - y si las reconstrucciones visuales capturan rasgos faciales, no solo una cara promedio borrosa.
Nota: Para imágenes continuas como estas, binary_crossentropy no es necesariamente mejor que mse. Puede servir en datos normalizados, pero tiene más sentido cuando los pixeles se interpretan como probabilidades binarias. En este caso docente, mse hace más clara la comparación entre modelos.
Discusión¶
¿Cuándo conviene usar un autoencoder en vez de PCA, t-SNE y UMAP?¶
Respuesta:
Depende del objetivo.
| Objetivo | Método sugerido |
|---|---|
| Reducción de dimensión lineal, rápida, interpretable | PCA |
| Visualización 2D que preserve estructura local | t-SNE / UMAP |
| Aprender representaciones compactas paramétricas que puedan ser usadas para otras tareas (e.g. reconstrucción, generación, clasificación) | Autoencoder |
Intuición:
- PCA busca direcciones ortogonales que capturan mayor varianza → es lineal y global.
- t-SNE / UMAP construyen mapas 2D buenos para visualización, pero no tienen una función de transformación directa. No se puede aplicar fácilmente a nuevos datos.
- Autoencoder aprende una función explícita $ f_\theta(x) = h $ (el encoder) y es capaz de reconstruir (decoder). Sirve cuando quieres:
- usar el embedding para otra red (clasificación, clustering),
- hacer compresión aprendida,
- generar nuevos ejemplos (e.g. con VAE o GANs),
- o cuando los datos no se proyectan bien linealmente (más allá de lo que PCA puede ver).
Conclusión:
Si lo que quieres es un mapa útil para visualización, usa t-SNE o UMAP. Si quieres una representación aprendida que se pueda aplicar a nuevos datos o reutilizar, usa un autoencoder.
¿Cómo se puede evitar que un autoencoder simplemente aprenda la identidad?¶
Respuesta: Un autoencoder es entrenado para que $ g(f(x)) \approx x $. Sin restricciones, la red puede simplemente aprender a copiar la entrada → sin extraer estructura.
Estrategias para evitarlo:
Undercomplete autoencoder:
- Forzamos una capa latente más pequeña que la dimensión original $ d < D $, obligando a la red a comprimir y aprender estructura relevante.
- Es la forma más básica de regularización.
Regularización explícita:
- Sparse autoencoder: impone que la mayoría de las neuronas del embedding estén en cero → activación dispersa.
- Denoising autoencoder: se corrompe la entrada (ruido) y se pide que reconstruya el original → fuerza a aprender patrones estables.
- Contractive autoencoder: penaliza grandes derivadas en la codificación para obtener representaciones estables frente a pequeñas perturbaciones.
Intuición:
Si el autoencoder es muy poderoso y no lo limitamos, simplemente va a memorizar. Como un estudiante que copia sin entender. Por eso, le ponemos límites para que tenga que encontrar ‘resúmenes’ o representaciones significativas del input.
¿Qué rol cumplen los autoencoders en técnicas modernas como los variational autoencoders?¶
Respuesta: Los Variational Autoencoders (VAEs) son una extensión probabilística de los autoencoders.
Autoencoder clásico: aprende un punto en un espacio latente $ h = f(x) $.
VAE: aprende una distribución $ q(h|x) $, típicamente gaussiana → mapea cada entrada a una región difusa del espacio latente.
¿Por qué es útil?
- Permite generar nuevos ejemplos: puedes muestrear puntos del espacio latente y decodificarlos.
- Se usa en modelos generativos, compresión probabilística, y aprendizaje semi-supervisado.
Intuición:
Un autoencoder aprende un punto por ejemplo; un VAE aprende una nube. Así, podemos explorar el espacio latente, no sólo reconociendo, sino también ‘imaginando’ ejemplos nuevos.
Regularización en autoencoders¶
Regularización = controlar la capacidad del modelo.
| Tipo | Idea principal | Resultado deseado |
|---|---|---|
| Sparse | Forzar activación mínima en capas ocultas | Representaciones parciales y robustas |
| Denoising | Entrenar con datos corruptos (ruido, dropout) | Representaciones más estables |
| Contractive | Penalizar cambios abruptos en el embedding | Invariancia a pequeñas perturbaciones |
Ahora que sabemos cómo entrenar redes para comprimir datos y reconstruirlos… ¿Y si en vez de un punto en el espacio latente, aprendemos una distribución? ¿Y si ese espacio puede ser usado para crear e interpolar? Bienvenidos al mundo de los modelos generativos: VAEs, GANs, y beyond.