Transformers - Atención¶
Modelos de Machine Learning No-Supervisados¶
Dr. Cristian Candia¶
Universidad del Desarrollo (UDD), Chile¶
- Director, Computational Research in Social Sciences Lab
- Faculty, Data Science Institute, School of Engineering
Northwestern University, United States¶
- External Faculty, Northwestern Institute on Complex Systems (NICO), Kellogg School of Management
Founder & CSTO¶
- Capybara. Capybara ayuda a establecimiento educacionales a detectar señales tempranas de bullying, medir convivencia escolar y tomar decisiones basadas en evidencia para prevenir conflictos a tiempo.

Paper central de esta clase: Vaswani et al. (2017), Attention Is All You Need.
De los problemas clásicos de NLP a Transformers¶
El Transformer nace desde una pregunta concreta de procesamiento de lenguaje natural (NLP):
¿cómo puede un modelo transformar una secuencia de palabras en otra secuencia de palabras preservando significado, orden, dependencias y contexto?
El caso emblemático es la traducción automática. Traducir no consiste en reemplazar palabra por palabra: hay que resolver ambigüedades, reordenar frases, mantener concordancia gramatical y decidir qué partes del texto fuente importan para cada palabra generada.
Punto de partida: encoder-decoder recurrente¶
Antes del Transformer, una arquitectura muy usada para traducción era el encoder-decoder recurrente.
La idea es:
- El encoder lee la oración de entrada token por token usando una RNN, LSTM o GRU.
- En cada paso actualiza un estado oculto, que resume lo leído hasta ese momento.
- El decoder genera la oración de salida token por token, también de forma recurrente.
- Se llama recurrente porque la misma operación se repite en cada posición y el estado de cada paso depende del estado anterior.
En las primeras versiones, el decoder dependía fuertemente del último estado del encoder: un solo vector debía resumir toda la oración. Eso funcionaba razonablemente en frases cortas, pero se vuelve un cuello de botella cuando la secuencia es larga o cuando hay que recuperar detalles específicos.
Primera intuición de atención¶
La atención aparece para aliviar ese cuello de botella.
Intuitivamente, atención significa:
al producir una salida, el modelo aprende a asignar más peso a las partes de la entrada que son relevantes en ese momento.
No es atención consciente ni una explicación humana del razonamiento del modelo. Es una operación matemática diferenciable: se calculan pesos, esos pesos suman 1, y con ellos se construye una mezcla ponderada de representaciones.
Ejemplo intuitivo: si un modelo traduce una oración y está generando la palabra correspondiente a ratón, debería mirar con más fuerza el token de entrada que contiene mouse/ratón, no todos los tokens por igual.
Problemas tradicionales en NLP¶
Antes de Transformers, los modelos secuenciales enfrentaban varios desafíos.
1. Representar significado en contexto¶
Una palabra puede cambiar de sentido según su entorno.
Ejemplo en español:
- banco puede ser una institución financiera: “El banco aprobó el crédito”.
- banco también puede ser un asiento: “Me senté en el banco de la plaza”.
El modelo necesita usar contexto, no solo una definición fija de diccionario.
2. Capturar dependencias largas¶
En una oración larga, una palabra puede depender de otra que apareció muchos tokens antes.
Ejemplo:
El libro que los estudiantes que llegaron tarde estaban leyendo era difícil.
El verbo era concuerda con libro, no con estudiantes. Para resolverlo, el modelo debe mantener información relevante a través de una distancia larga.
3. Reordenar información entre idiomas¶
Distintos idiomas no organizan las ideas en el mismo orden.
Ejemplo español -> inglés:
el gato negro -> the black cat
En español, el adjetivo negro aparece después de gato. En inglés, black aparece antes de cat. El modelo debe aprender alineamientos flexibles entre tokens de entrada y tokens de salida.
4. Evitar el cuello de botella de una sola representación¶
Si toda la entrada se comprime en un único vector, algunos detalles pueden perderse. La atención permite que el decoder consulte varios estados del encoder, no solo el último.
5. Entrenar de forma eficiente¶
Las RNNs procesan secuencias paso a paso. Eso limita la paralelización y hace más difícil escalar entrenamiento en hardware moderno.
Traducción automática y Google¶
El Transformer fue desarrollado por investigadores de Google para tareas de traducción automática neuronal y transducción de secuencias, un problema central en sistemas como Google Translate.
Contexto histórico:
- En 2016, Google presentó GNMT, un sistema de traducción neuronal basado en redes recurrentes profundas con atención.
- En 2017, Vaswani et al. propusieron el Transformer, eliminando recurrencias y convoluciones del bloque principal.
- El Transformer logró resultados competitivos o superiores en traducción, con mucho más paralelismo durante entrenamiento.
Qué resolvió el Transformer¶
El aporte central de Attention Is All You Need fue mostrar que una arquitectura basada en atención podía resolver secuencias sin depender de RNNs ni CNNs dentro del bloque principal.
Esto atacó varios problemas a la vez:
| Problema tradicional | Solución en Transformer |
|---|---|
| Secuencialidad de RNNs | Cálculo paralelo por capa |
| Dependencias largas | Ruta directa entre posiciones mediante self-attention |
| Alineamiento entre entrada y salida | Encoder-decoder attention |
| Falta de orden en atención pura | Codificación posicional |
| Capacidad de representación | Multi-head attention + FFN + profundidad |
Por qué después sirvió para muchas otras tareas¶
Al principio, el Transformer se presenta como una arquitectura para traducción. Luego la comunidad observó que sus propiedades eran útiles en muchas tareas de lenguaje:
- Aprende representaciones contextuales de tokens.
- Escala bien con datos, parámetros y cómputo.
- Permite preentrenamiento autosupervisado en grandes corpus.
- Puede adaptarse como encoder, decoder o encoder-decoder.
De ahí surgen familias como:
BERT: usa el encoder del Transformer para comprensión de lenguaje.
Ejemplos: clasificar si una reseña es positiva o negativa, detectar entidades como personas/lugares/organizaciones, o responder una pregunta usando un párrafo dado.GPT: usa un decoder Transformer autoregresivo para generar texto de izquierda a derecha.
Ejemplos: completar “El resultado principal del experimento fue...”, redactar una explicación, escribir código o continuar una conversación.T5: usa un Transformer encoder-decoder y formula tareas como texto-a-texto.
Ejemplos:traducir español a inglés: el gato negro->the black cat;resumir: [texto largo]->[resumen];clasificar sentimiento: me encantó la película->positivo.
Sobre capacidades al escalar modelos¶
En modelos posteriores, mucho más grandes que el Transformer original, se observaron capacidades que no eran evidentes en modelos pequeños.
Ejemplos:
- Aprendizaje en contexto: el modelo puede usar ejemplos dentro del prompt para resolver una tarea nueva sin actualizar sus pesos.
- Transferencia entre tareas: un modelo entrenado de forma general puede adaptarse a traducción, resumen, clasificación o pregunta-respuesta.
- Razonamiento guiado por ejemplos: el desempeño puede mejorar cuando se muestran pasos intermedios o demostraciones.
- Seguimiento de instrucciones: aparece con más fuerza cuando el modelo, además de preentrenarse, se ajusta con datos de instrucciones y preferencias humanas.
Estas capacidades no son una propiedad mágica del bloque Transformer por sí solo. Dependen de la interacción entre arquitectura, objetivo de entrenamiento, escala, datos, optimización, ajuste posterior y forma de evaluación.
También hay que ser cuidadosos con la palabra emergente. En muchos papers significa que una métrica mejora bruscamente al aumentar la escala. Pero parte de ese salto puede depender de cómo se mide el desempeño: una métrica discreta puede hacer que una mejora gradual parezca repentina.
Al escalar modelos aparecen comportamientos nuevos o mucho más visibles, pero no debemos interpretarlos automáticamente como una fase cualitativa misteriosa. Hay que mirar la tarea, la métrica, los datos y el procedimiento de entrenamiento.
Idea clave¶
La motivación natural para entender Transformers en este curso es NLP:
traducir, representar y generar secuencias requiere contexto, alineamiento, memoria de largo alcance y entrenamiento escalable.
El Transformer fue una respuesta elegante a esos problemas.
Modelos Transformer (Vaswani et al., 2017)¶
Attention Is All You Need propuso una arquitectura encoder-decoder para secuencias que evita recurrencias y convoluciones dentro del bloque principal del modelo.
El contexto original fue traducción automática neuronal. El paper fue escrito por investigadores de Google y University of Toronto, y evaluó el modelo en benchmarks de traducción como WMT 2014 English-German y English-French.
La contribución no fue inventar la atención desde cero. La atención ya existía en modelos encoder-decoder recurrentes. La contribución fue convertirla en el mecanismo central de una arquitectura altamente paralelizable.
Limitaciones de modelos secuenciales tradicionales¶
Antes de los Transformers, muchas arquitecturas para lenguaje usaban RNN, LSTM o GRU. Estas redes son valiosas, pero tienen tres restricciones importantes:
- Procesan la secuencia en orden: el estado de la posición $t$ depende del estado anterior.
- La paralelización sobre posiciones es limitada, porque no se puede calcular todo al mismo tiempo.
- Las dependencias de largo alcance requieren que la señal atraviese muchos pasos, lo que puede dificultar la optimización.
Las CNNs reducen parte de esta secuencialidad, pero para conectar posiciones lejanas necesitan profundidad, kernels grandes o dilataciones.
Qué propone el Transformer¶
El Transformer combina tres ideas:
- Self-attention: cada posición calcula una representación usando información de otras posiciones de la misma secuencia.
- Multi-head attention: se calculan varias atenciones en paralelo sobre subespacios distintos.
- Codificación posicional: se agrega información de orden, porque la atención por sí sola no sabe qué token vino antes o después.
La ventaja estructural es clara: las relaciones entre tokens pueden calcularse en paralelo y con una ruta corta entre posiciones. La limitación también es importante: la atención completa tiene costo cuadrático en la longitud de la secuencia.
Arquitectura general del Transformer¶
Basado en Vaswani et al. (2017), Attention Is All You Need.
El Transformer original es una arquitectura encoder-decoder diseñada para transformar una secuencia de entrada en otra secuencia de salida. Este tipo de tarea se conoce como transducción de secuencias.
En traducción automática, por ejemplo, el encoder recibe una oración en el idioma fuente:
$ \text{el gato negro} $
y el decoder genera autoregresivamente una oración en el idioma destino:
$ \text{the black cat} $
La idea central del Transformer es reemplazar la recurrencia de las RNN por mecanismos de atención, permitiendo que cada token compare su representación con la de otros tokens de la secuencia.
Sus componentes principales son:
- Multi-head attention
- Feed-forward networks aplicadas posición por posición
- Conexiones residuales
- Layer normalization
- Codificación posicional
- Máscaras causales en el decoder
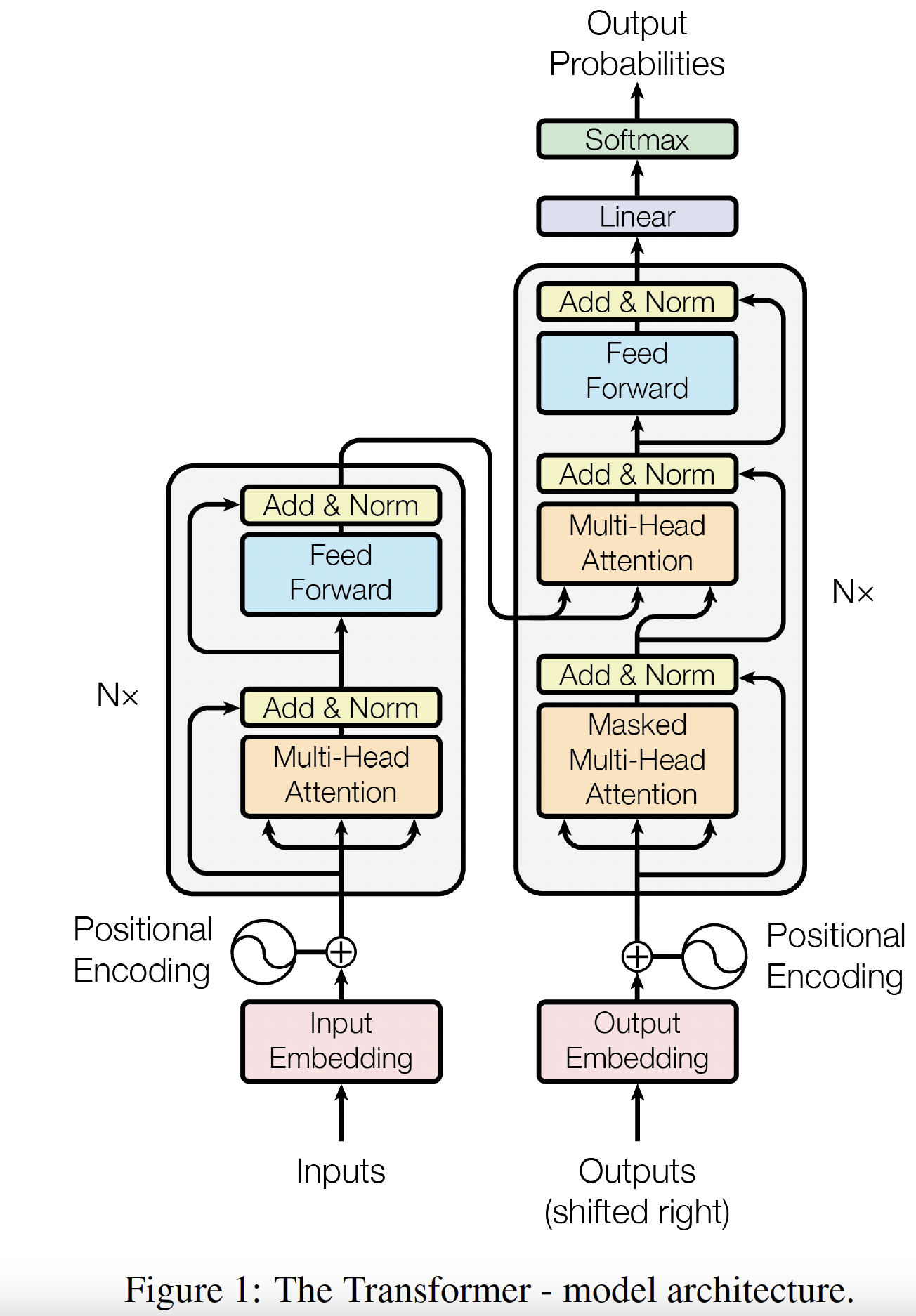
Figura: Arquitectura original del Transformer. A la izquierda, el encoder procesa la secuencia de entrada. A la derecha, el decoder genera la secuencia de salida de manera autoregresiva, es decir, token por token.
1. Entrada al modelo: tokens, embeddings y posición¶
El Transformer no recibe palabras como texto crudo. Primero, cada token se transforma en un vector numérico llamado embedding.
Por ejemplo:
$ \text{el} \rightarrow x_1,\quad \text{gato} \rightarrow x_2,\quad \text{negro} \rightarrow x_3 $
Sin embargo, la atención por sí sola no sabe el orden de los tokens. Para el mecanismo de atención, una secuencia sin información posicional se parece más a un conjunto que a una oración ordenada.
Por eso, el modelo suma a cada embedding una codificación posicional:
$ z_i = x_i + p_i $
donde $x_i$ es el embedding del token en la posición $i$ y $p_i$ es el vector que codifica la posición.
En el Transformer original, Vaswani et al. usan codificaciones posicionales sinusoidales, aunque en modelos modernos también se usan codificaciones aprendidas u otros mecanismos posicionales.
2. Encoder¶
El encoder recibe la secuencia de entrada ya convertida en embeddings con información posicional.
Si la entrada es:
$ \text{el gato negro} $
entonces cada token se representa como un vector:
$ x_1, x_2, x_3 $
A cada embedding se le suma una codificación posicional, de modo que el modelo recibe vectores que contienen tanto información semántica del token como información sobre su posición en la secuencia.
En el Transformer base del paper original, el encoder tiene $N = 6$ capas idénticas. Cada capa contiene dos subcomponentes principales:
- Multi-head self-attention
- Feed-forward network posición por posición
Cada uno de estos subcomponentes está rodeado por dos mecanismos adicionales:
- Conexión residual
- Layer normalization
En el Transformer original, cada subcapa tiene la forma:
$ \text{LayerNorm}(x + \text{Sublayer}(x)) $
Esto significa que la salida de una subcapa no reemplaza directamente a la entrada. Primero, el modelo suma la entrada original $x$ con la transformación producida por la subcapa, $\text{Sublayer}(x)$. Luego normaliza el resultado.
¿Qué es la conexión residual?¶
Una conexión residual es un atajo que permite que la representación original pase directamente a la siguiente etapa.
Sin conexión residual, una subcapa produciría simplemente:
$ y = \text{Sublayer}(x) $
Con conexión residual, el modelo calcula:
$ y = x + \text{Sublayer}(x) $
La idea es que la subcapa no necesita aprender una representación completamente nueva desde cero. Solo necesita aprender una corrección, actualización o residuo sobre la representación que ya existía.
Por ejemplo, si $x_i$ es la representación del token gato, la self-attention puede agregar información desde negro. Pero el modelo no descarta la representación previa de gato. La conserva y le suma una actualización contextual:
$ h_i = x_i + \text{SelfAttention}(x_i) $
Así, la nueva representación mantiene información original del token y agrega información contextual aprendida por la atención.
En resumen, cada capa del encoder no reemplaza la representación de los tokens, sino que la refina. La self-attention permite intercambiar información entre posiciones, la FFN aumenta la expresividad transformando cada posición de manera no lineal, la conexión residual conserva la información previa y facilita el entrenamiento, y la LayerNorm estabiliza las activaciones antes de pasar a la siguiente capa.
2.1 Multi-head self-attention en el encoder¶
En la self-attention, cada token de la secuencia de entrada puede atender a los demás tokens de la misma secuencia.
Por ejemplo, en la frase:
$ \text{el gato negro} $
el token gato puede atender a negro para incorporar información sobre su atributo. A su vez, negro puede atender a gato para saber qué sustantivo está modificando.
La atención no opera directamente sobre los tokens, sino sobre vectores derivados de ellos. Para cada posición, el modelo construye tres vectores:
- Query (Q): qué información busca esta posición.
- Key (K): qué tipo de información ofrece esta posición.
- Value (V): qué contenido entrega esta posición si recibe atención.
La atención compara queries con keys para producir pesos de atención. Luego, esos pesos se usan para combinar los values.
La operación básica es:
$ \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V $
La parte $QK^\top$ mide compatibilidad entre queries y keys.
La softmax transforma esas compatibilidades en pesos.
El término $V$ contiene la información que será mezclada.
Importante: el value no es el peso.
El peso sale de comparar queries y keys.
El value es la información que se combina usando esos pesos.
2.2 ¿Por qué multi-head?¶
En lugar de hacer una sola atención, el Transformer aplica varias atenciones en paralelo. A esto se le llama multi-head attention.
Cada cabeza aprende una forma distinta de mirar la secuencia.
Por ejemplo, algunas cabezas pueden capturar relaciones sintácticas, como sustantivo-adjetivo; otras pueden capturar dependencias de largo alcance, concordancia, referencias o estructuras semánticas.
En el Transformer base:
$ h = 8 $
Es decir, se usan 8 cabezas de atención en paralelo.
Cada cabeza trabaja en una subdimensión del espacio total. Como $d_{model} = 512$ y $h = 8$, cada cabeza usa típicamente:
$ d_k = d_v = 64 $
Luego, las salidas de todas las cabezas se concatenan y se proyectan nuevamente al espacio de dimensión $d_{model}$.
2.3 Feed-forward network del encoder¶
Después de la self-attention, cada posición ya contiene información contextual. Por ejemplo, la representación de gato puede haber incorporado información de negro, y la representación de negro puede haber incorporado información de gato.
Pero esa información todavía debe ser procesada. Para eso se usa una position-wise feed-forward network: una pequeña red neuronal aplicada a cada posición de manera independiente con los mismos pesos para todas las posiciones*.
Su objetivo es transformar la representación contextual de cada token mediante una operación no lineal.
La forma general es:
$ \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 $
En el Transformer base, cada vector de dimensión $d_{model} = 512$ se expande primero a una dimensión interna mayor, $d_{ff} = 2048$, pasa por una no linealidad, y luego vuelve a $512$ dimensiones.
Intuitivamente:
- La self-attention mezcla información entre tokens.
- La FFN procesa internamente la información que quedó en cada token.
- La expansión a $2048$ dimensiones le da al modelo más capacidad para construir combinaciones no lineales de las características.
- La proyección final devuelve la representación al tamaño esperado por la siguiente capa del Transformer.
¿Qué significa que se usen los mismos pesos para todas las posiciones?*¶
Significa que la misma red neuronal se aplica a cada token de la secuencia.
Si la secuencia tiene tres posiciones:
$ h_1 = \text{representación de “el”} $
$ h_2 = \text{representación de “gato”} $
$ h_3 = \text{representación de “negro”} $
entonces el modelo aplica la misma función a cada una:
$ \text{FFN}(h_1) $
$ \text{FFN}(h_2) $
$ \text{FFN}(h_3) $
La red usa los mismos parámetros $W_1$, $b_1$, $W_2$ y $b_2$ para todas las posiciones.
Esto no significa que todos los tokens produzcan la misma salida. Las salidas son distintas porque las entradas $h_1$, $h_2$ y $h_3$ son distintas. Después de la self-attention, cada token trae una mezcla contextual diferente.
La idea es similar a una convolución con filtros compartidos: no se aprende una red distinta para la posición 1, otra para la posición 2 y otra para la posición 3. Se aprende una misma transformación general que puede aplicarse a cualquier posición de la secuencia.
En rsumen: la FFN es como un “procesador local” que se aplica a cada token después de que la atención ya trajo información del resto de la frase.
La atención responde: ¿de qué otros tokens necesito información?
La FFN responde: ¿qué hago con la información que ya tengo en esta posición?
La self-attention mezcla información entre posiciones; la feed-forward network transforma la representación de cada posición. Se usan los mismos pesos en todas las posiciones para compartir parámetros, permitir secuencias de largo variable y aplicar la misma regla de procesamiento a cualquier token.
3. Decoder¶
El decoder genera la secuencia de salida token por token.
Durante entrenamiento, recibe la secuencia correcta desplazada una posición hacia la derecha. Esto se conoce como shifted right o teacher forcing.
Por ejemplo, para aprender a generar:
$ \text{the black cat} $
el decoder recibe algo como:
$ \text{<start> the black} $
y debe predecir:
$ \text{the black cat} $
Esto permite entrenar todas las posiciones en paralelo, pero manteniendo la restricción autoregresiva: para predecir el token en la posición $t$, el modelo no debe ver los tokens futuros.
En el Transformer base, el decoder también tiene $N = 6$ capas. Cada capa contiene tres subcomponentes principales:
- Masked multi-head self-attention
- Encoder-decoder attention
- Feed-forward network posición por posición
3.1 Masked self-attention en el decoder¶
La primera subcapa del decoder es una self-attention con máscara causal.
Esto significa que cada posición solo puede atender a posiciones anteriores o a sí misma.
Por ejemplo, si el decoder está generando la tercera palabra, no puede mirar la cuarta o quinta palabra de la respuesta correcta.
La máscara causal impide que el modelo “haga trampa” durante entrenamiento.
Sin esta máscara, el decoder podría mirar tokens futuros y aprender una tarea artificialmente fácil: copiar información que no estará disponible durante la generación real.
3.2 Encoder-decoder attention o cross-attention¶
La segunda subcapa del decoder conecta el decoder con la salida del encoder.
Aquí ocurre una diferencia clave:
- Las queries vienen del decoder.
- Las keys y values vienen del encoder.
Por eso esta operación también se llama cross-attention.
Intuitivamente, el decoder pregunta: “¿qué información de la entrada necesito ahora para generar el siguiente token?”.
Por ejemplo, al generar black desde la entrada:
$ \text{el gato negro} $
el decoder produce una query asociada a la posición actual. Esa query se compara con las keys derivadas de las representaciones del encoder para el, gato y negro.
Si la query es muy compatible con la key asociada a negro, el peso de atención sobre esa posición será alto. Luego, el modelo incorpora principalmente el value asociado a negro.
En otras palabras:
- La query decide qué se está buscando.
- La key permite decidir dónde mirar.
- El value contiene la información que se trae desde esa posición.
- El peso de atención indica cuánto de cada value se incorpora.
Así, la cross-attention permite que el decoder consulte la oración fuente mientras genera la oración destino.
3.3 Feed-forward network del decoder¶
Después de la masked self-attention y la cross-attention, cada posición pasa por una feed-forward network.
Igual que en el encoder, esta red se aplica posición por posición con los mismos pesos para todas las posiciones.
La atención permite combinar información entre tokens.
La FFN permite transformar internamente la representación de cada token.
4. Capa final de salida¶
Después del último bloque del decoder, cada posición tiene un vector contextual de dimensión $d_{model}$.
Ese vector se proyecta al tamaño del vocabulario usando una capa lineal:
$ \text{logits} = hW_{\text{vocab}} + b $
Si el vocabulario tiene 30.000 tokens, entonces para cada posición el modelo produce 30.000 logits.
Luego, una softmax transforma esos logits en probabilidades:
$ P(\text{token siguiente} \mid \text{contexto}) = \text{softmax}(\text{logits}) $
Durante generación, el modelo usa esas probabilidades para escoger el siguiente token. Luego ese token se agrega a la entrada del decoder y el proceso se repite.
5. Configuración base del paper original¶
| Hiperparámetro | Valor en Transformer base |
|---|---|
| Capas de encoder | $N = 6$ |
| Capas de decoder | $N = 6$ |
| Dimensión del modelo | $d_{model} = 512$ |
| Cabezas de atención | $h = 8$ |
| Dimensión por cabeza | $d_k = d_v = 64$ |
| Dimensión interna de la FFN | $d_{ff} = 2048$ |
| Dropout | $0.1$ |
| Normalización | Post-LayerNorm |
| Positional encoding | Sinusoidal |
6. Resumen conceptual¶
| Componente | Función principal |
|---|---|
| Embeddings | Representan tokens como vectores numéricos |
| Positional encoding | Agrega información sobre el orden de los tokens |
| Self-attention | Permite que cada token atienda a otros tokens de la misma secuencia |
| Masked self-attention | Impide que el decoder vea tokens futuros |
| Cross-attention | Permite que el decoder consulte la salida del encoder |
| Multi-head attention | Aprende varias formas paralelas de atender a la secuencia |
| Feed-forward network | Transforma no linealmente cada posición |
| Residual connections | Facilitan el flujo de información y gradientes |
| Layer normalization | Estabiliza las activaciones durante el entrenamiento |
| Linear + softmax | Convierte vectores del decoder en probabilidades sobre tokens |
Idea central¶
El Transformer separa dos operaciones fundamentales:
- Intercambiar información entre posiciones, mediante atención.
- Transformar la representación de cada posición, mediante redes feed-forward.
El encoder construye una representación contextual de la entrada.
El decoder usa su propio historial generado y consulta al encoder para producir la salida token por token.
Por eso, en traducción, el modelo no traduce palabra por palabra de forma rígida. Aprende a construir representaciones contextuales y a decidir, en cada paso, qué partes de la entrada son relevantes para generar el siguiente token.
Mecanismos de atención¶
Por qué necesitamos atención¶
La intuición central es:
cuando el decoder genera una palabra, no todas las palabras de entrada importan lo mismo.
La atención permite que el modelo aprenda a qué posiciones mirar con más peso en cada paso de generación.
Caso 1: traducción aproximadamente alineada¶
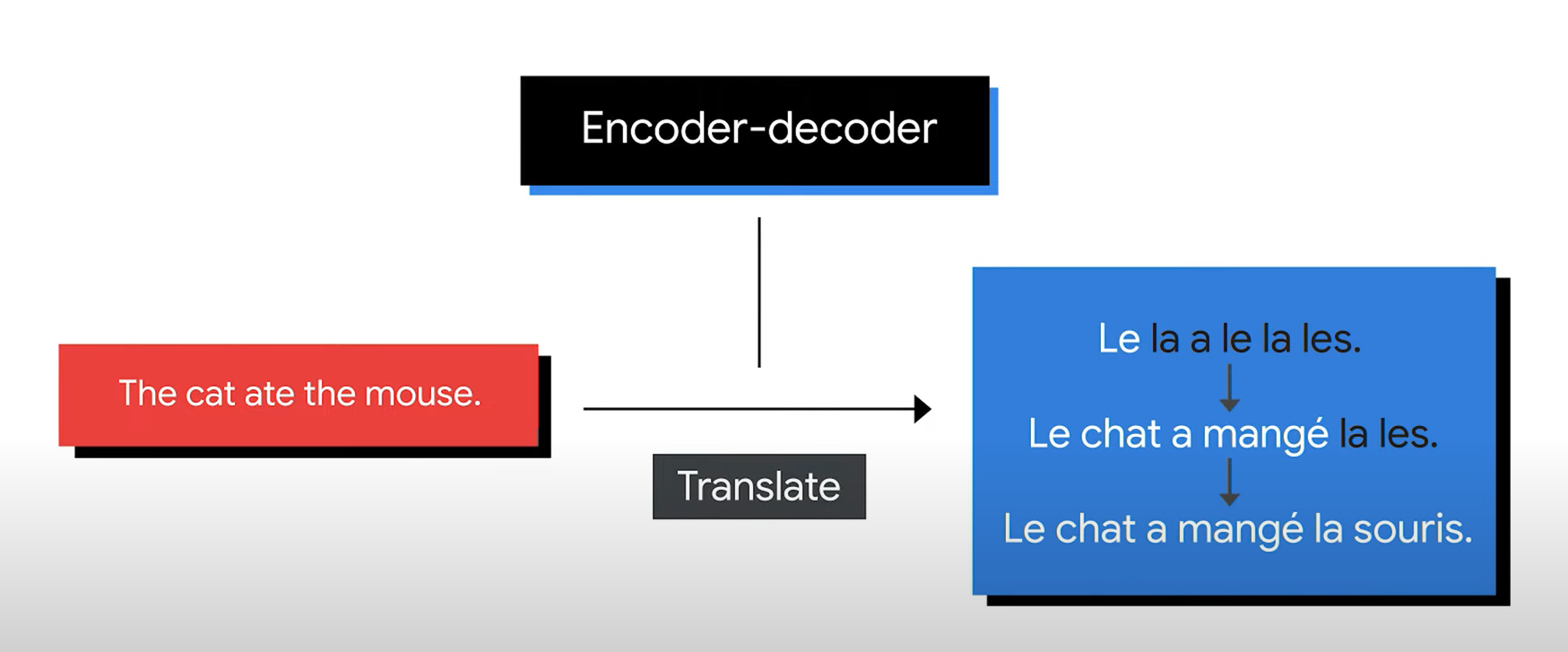
La figura usa un ejemplo inglés -> francés:
The cat ate the mouse -> Le chat a mangé la souris
Varias palabras mantienen una correspondencia relativamente directa:
- The -> Le / la
- cat -> chat
- ate -> a mangé
- mouse -> souris
En un ejemplo simple, un modelo podría apoyarse bastante en correspondencias locales entre input y output.
Caso 2: traducción con reordenamiento¶
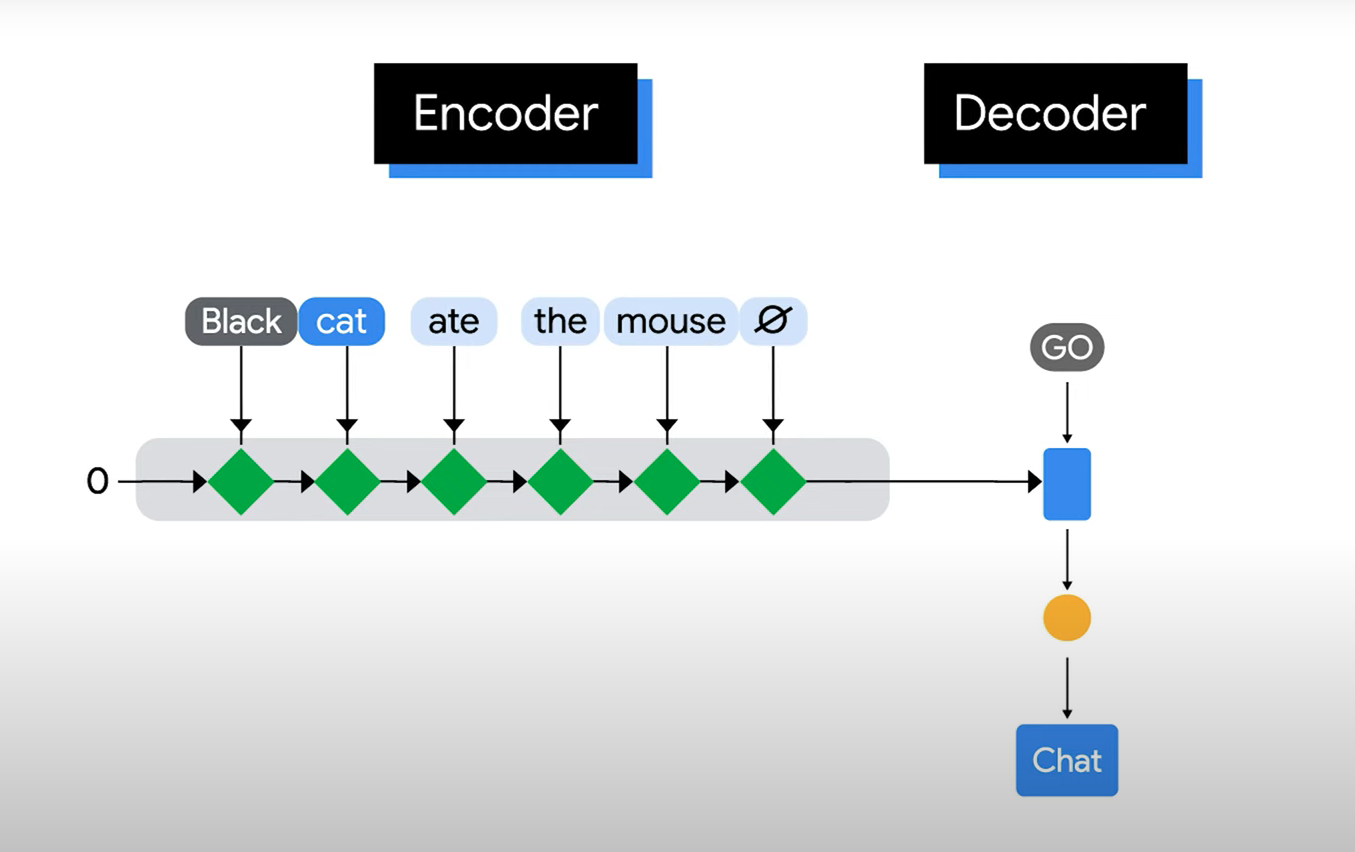
Ahora la figura muestra:
Black cat ate the mouse -> Le chat noir a mangé la souris
Aquí aparece un reordenamiento:
- En inglés: black cat.
- En francés: chat noir.
Entonces:
- black se alinea con noir.
- cat se alinea con chat.
La posición por sí sola no basta. El modelo necesita aprender alineamientos flexibles entre partes de la entrada y partes de la salida.
Un análogo útil en español -> inglés es:
el gato negro -> the black cat
El problema en encoder-decoder sin atención¶
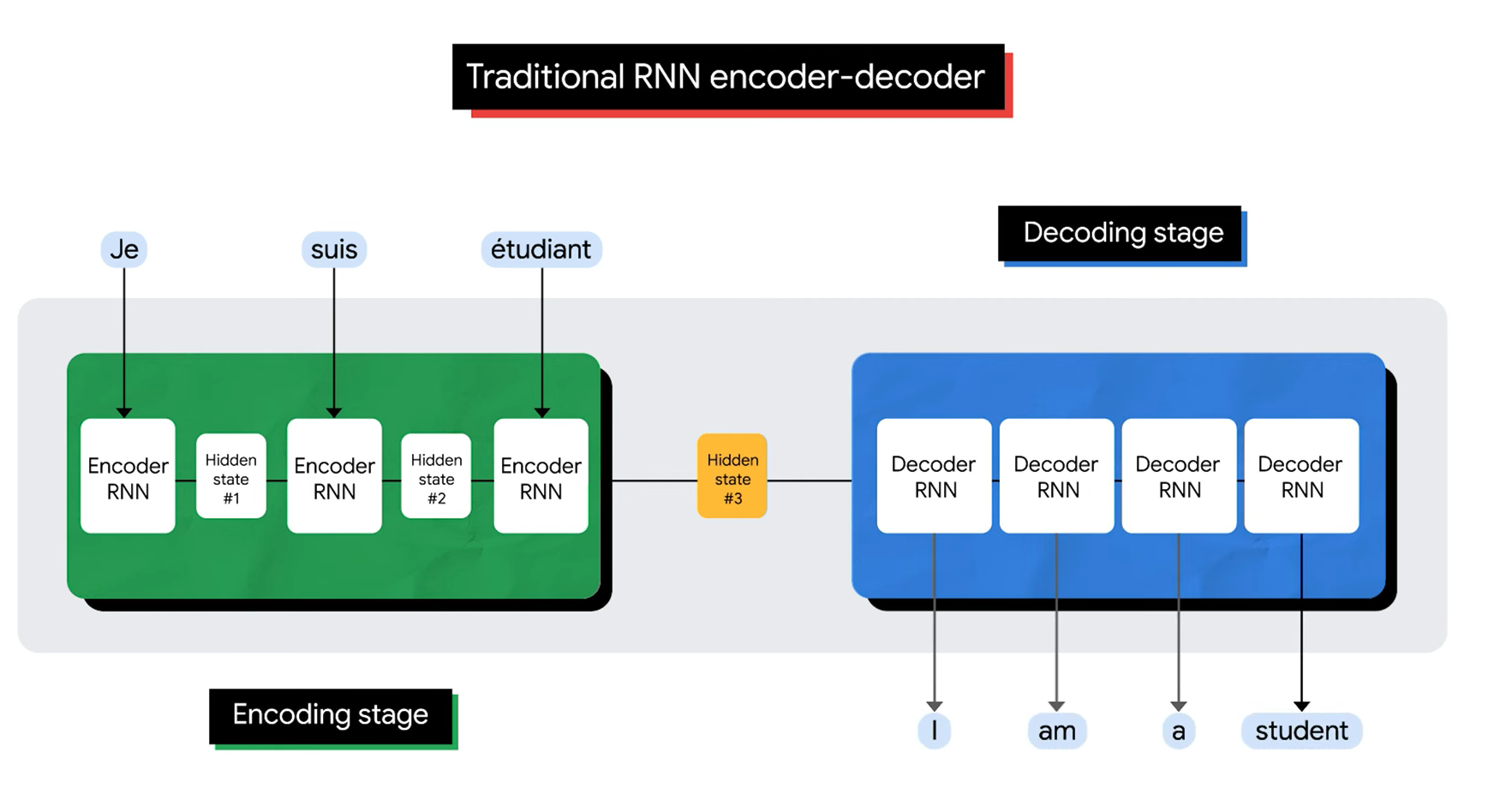
La figura muestra un encoder-decoder recurrente tradicional. El encoder procesa la entrada paso a paso y el decoder genera la salida paso a paso.
En las primeras versiones, el decoder dependía fuertemente de un único vector de contexto, usualmente el estado oculto final del encoder.
Esto crea un problema:
una oración completa queda comprimida en un solo vector.
1. Bottleneck de representación¶
Toda la información semántica y sintáctica de la entrada debe pasar por una representación fija. Mientras más larga o compleja sea la secuencia, más difícil es conservar todos los detalles relevantes.
2. Acceso indirecto a tokens lejanos¶
En una RNN, la información debe viajar paso a paso. Las dependencias largas pueden aprenderse, especialmente con LSTM/GRU, pero la ruta de información es larga y puede ser difícil de optimizar.
3. Falta de alineamiento explícito¶
El decoder no elige directamente qué parte de la entrada consultar en cada paso. Para traducción, resumen o respuesta a preguntas, eso es una limitación importante.
Qué introduce la atención¶
La atención permite que el decoder calcule, en cada paso, una mezcla ponderada de los estados del encoder. En lugar de usar siempre el mismo resumen fijo, usa un contexto distinto para cada token generado.
Esto permite modelar fenómenos como:
- Reordenamientos sintácticos.
- Traducciones de frases largas.
- Concordancia de género y número.
- Ambigüedades resueltas por contexto.
- Dependencias de largo alcance.
La idea es anterior al Transformer. Bahdanau et al. y Luong et al. ya usaban atención en modelos recurrentes de traducción. Vaswani et al. dan el paso siguiente: hacen que la atención sea el mecanismo central de la arquitectura.
Atención en encoder-decoder¶
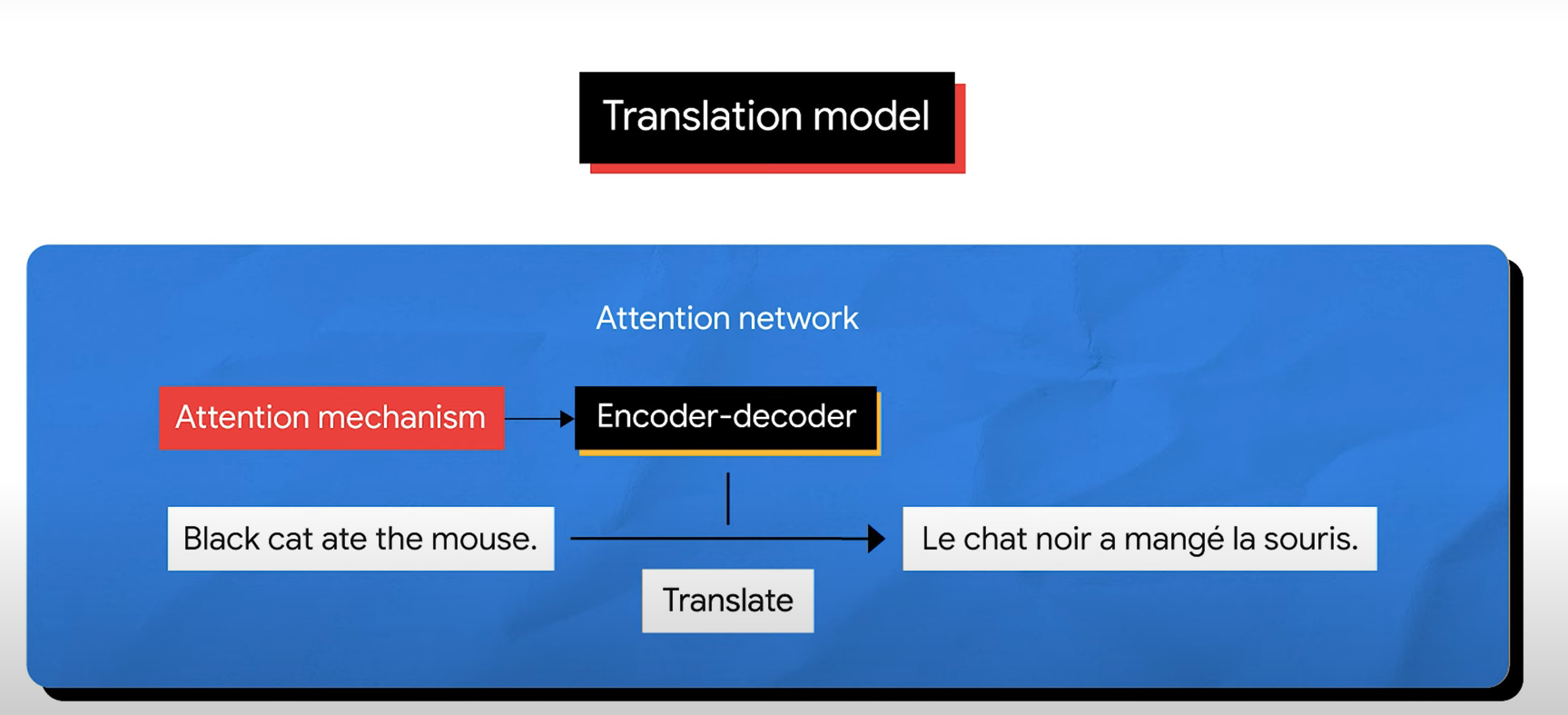
La atención cambia la forma en que un decoder usa la información del encoder.
Sin atención, el decoder recibe principalmente un resumen fijo de la entrada. Con atención, en cada paso de generación puede consultar todos los estados ocultos del encoder y asignarles pesos.
Intuición¶
Usando el ejemplo de la figura:
Black cat ate the mouse -> Le chat noir a mangé la souris
Cuando el decoder genera chat, debería mirar con fuerza el estado asociado a cat. Cuando genera noir, debería mirar con fuerza el estado asociado a Black. Cuando genera souris, debería mirar con fuerza el estado asociado a mouse.
El procedimiento es:
- El decoder produce una representación de su estado actual.
- Esa representación se compara con cada estado del encoder.
- Las comparaciones se transforman con softmax en pesos que suman 1.
- Los estados del encoder se combinan usando esos pesos.
Cálculo básico¶

Sea $h_1, h_2, ..., h_n$ la secuencia de estados del encoder. En el paso $t$ del decoder se calculan scores:
$$ e_{t,i} = \text{score}(s_t, h_i) $$Luego se normalizan:
$$ \alpha_{t,i} = \frac{\exp(e_{t,i})}{\sum_{j=1}^n \exp(e_{t,j})} $$Y se construye el vector de contexto:
$$ c_t = \sum_{i=1}^n \alpha_{t,i} h_i $$Donde:
- $s_t$ es el estado del decoder en el paso $t$.
- $h_i$ es el estado del encoder para el token $i$.
- $\alpha_{t,i}$ es el peso de atención asignado al token $i$ al generar el paso $t$.
- $c_t$ es el contexto usado por el decoder en ese paso.
Visualización de alineamientos¶
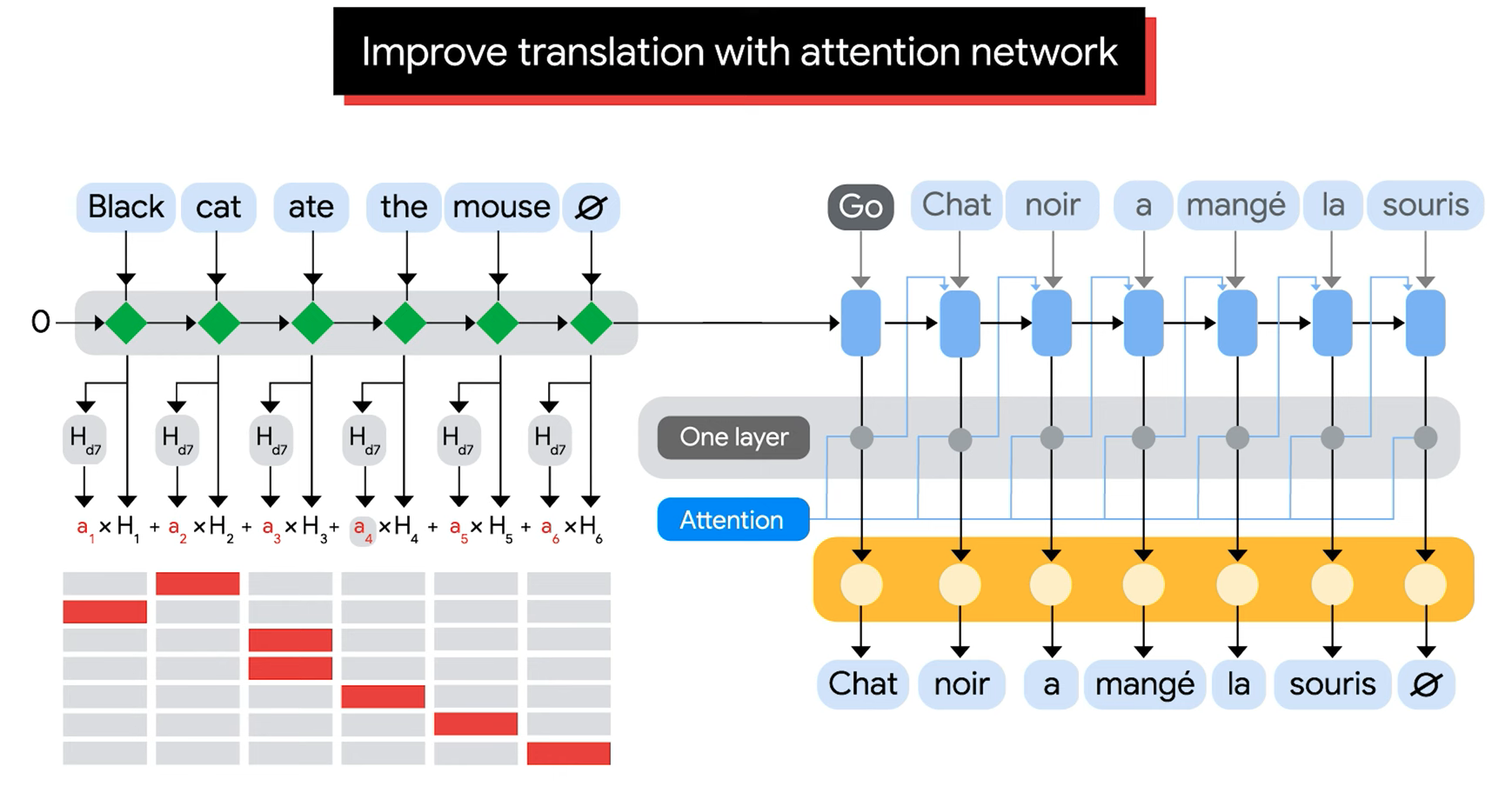
La matriz de atención muestra pesos entre tokens de salida y tokens de entrada.
- Cada fila representa un paso del decoder.
- Cada columna representa un token del encoder.
- Un valor alto indica que ese token de entrada influyó más en la mezcla ponderada para ese paso.
Por ejemplo:
- Al generar chat, el modelo puede asignar alto peso a cat.
- Al generar noir, puede asignar alto peso a Black.
- Al generar souris, puede asignar alto peso a mouse.
Interpretación (con cuidado)¶
Las matrices de atención son útiles para inspeccionar alineamientos, pero no deben confundirse automáticamente con una explicación causal completa del modelo.
Pedagógicamente, sirven para ver qué información se mezcló en una capa o paso. Científicamente, la interpretación requiere cautela: distintos patrones internos pueden producir salidas similares y los pesos de atención no siempre explican por sí solos la decisión final.
Qué resuelve la atención¶
Reduce el bottleneck de contexto
El decoder ya no depende solo del último estado del encoder.Aprende alineamientos flexibles
La relación input-output puede cambiar según el token generado.Usa contexto dinámico
Cada paso tiene su propio vector de contexto $c_t$.Mejora el manejo de secuencias largas
El decoder tiene una ruta más directa hacia todos los estados del encoder.
Qué no resuelve por sí sola¶
La atención dentro de una red neuronal no elimina la secuancialidad. El encoder y el decoder siguen procesando tokens secuencialmente.
La gran novedad del Transformer es usar self-attention como operación principal, eliminando las capas recurrentes y permitiendo mucho más paralelismo.
Entonces¶
La atención no es “mirar” en sentido humano; es aprender pesos que determinan qué representaciones se mezclan en cada paso.
En modelos encoder-decoder recurrentes, esto mejora la alineación y reduce el cuello de botella. En Transformers, la self-attention se convierte en el bloque central para mezclar información entre tokens de forma paralela.
Self-attention y cross-attention en Transformers¶
En un Transformer, cada token no se usa directamente como query, key o value. Primero, cada token se representa como un vector contextual inicial, llamado embedding. Luego, el modelo aprende tres transformaciones lineales distintas para producir:
- Query (Q): representa qué información está buscando una posición.
- Key (K): representa qué tipo de información ofrece una posición para ser encontrada.
- Value (V): representa la información que esa posición entrega si recibe atención.
Por lo tanto, query, key y value no son tokens en sí mismos. Son vectores aprendidos a partir de las representaciones de los tokens.
La atención se calcula en dos pasos. Primero, la query de una posición se compara con las keys de otras posiciones. Esa comparación produce puntajes de compatibilidad. Luego, esos puntajes se normalizan con una softmax para obtener pesos de atención. Finalmente, esos pesos se usan para combinar los values.
En forma simplificada:
$ \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V $
La parte $QK^\top$ mide compatibilidad entre queries y keys. La softmax convierte esas compatibilidades en pesos. El término $V$ contiene la información que será mezclada para construir el nuevo contexto.
Scaled Dot-Product Attention¶
Este es el bloque de atención usado en el Transformer original.
La idea es: una posición formula una consulta (query), compara esa consulta con claves (keys) y usa el resultado para promediar contenidos (values).
Definición formal¶
En el caso general:
- $Q \in \mathbb{R}^{m \times d_k}$: queries.
- $K \in \mathbb{R}^{n \times d_k}$: keys.
- $V \in \mathbb{R}^{n \times d_v}$: values.
Entonces:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V $$La salida tiene dimensión:
$$ \mathbb{R}^{m \times d_v} $$En self-attention, $Q$, $K$ y $V$ provienen de la misma secuencia, por eso normalmente $m=n$.
En encoder-decoder attention, las queries vienen del decoder y las keys/values vienen del encoder, por eso $m$ y $n$ pueden ser distintos.
Queries, keys y values¶
La analogía con una base de datos ayuda:
| Elemento | Intuición | Rol técnico |
|---|---|---|
| Query | Qué estoy buscando | Vector desde el cual se pregunta |
| Key | Qué ofrece cada posición | Vector contra el cual se compara la query |
| Value | Qué información recupero | Vector que se promedia ponderadamente |
Ejemplo: traducir “el gato negro” como “the black cat”¶
Supongamos que el modelo está generando la palabra black en el decoder. En ese momento, el decoder tiene una representación interna de lo que necesita producir. Esa representación genera una query.
Esa query se compara con las keys producidas por el encoder para los tokens de entrada:
- el
- gato
- negro
Si la query del decoder es compatible con la key asociada a negro, entonces el peso de atención sobre negro será alto. Pero lo que se incorpora al decoder no es la key ni el token directamente: se incorpora principalmente el value asociado a negro, ponderado por ese peso de atención.
Es decir, la key sirve para decidir dónde mirar.
El value contiene qué información traer desde esa posición.
El peso de atención indica cuánto de esa información usar.
Paso a paso¶
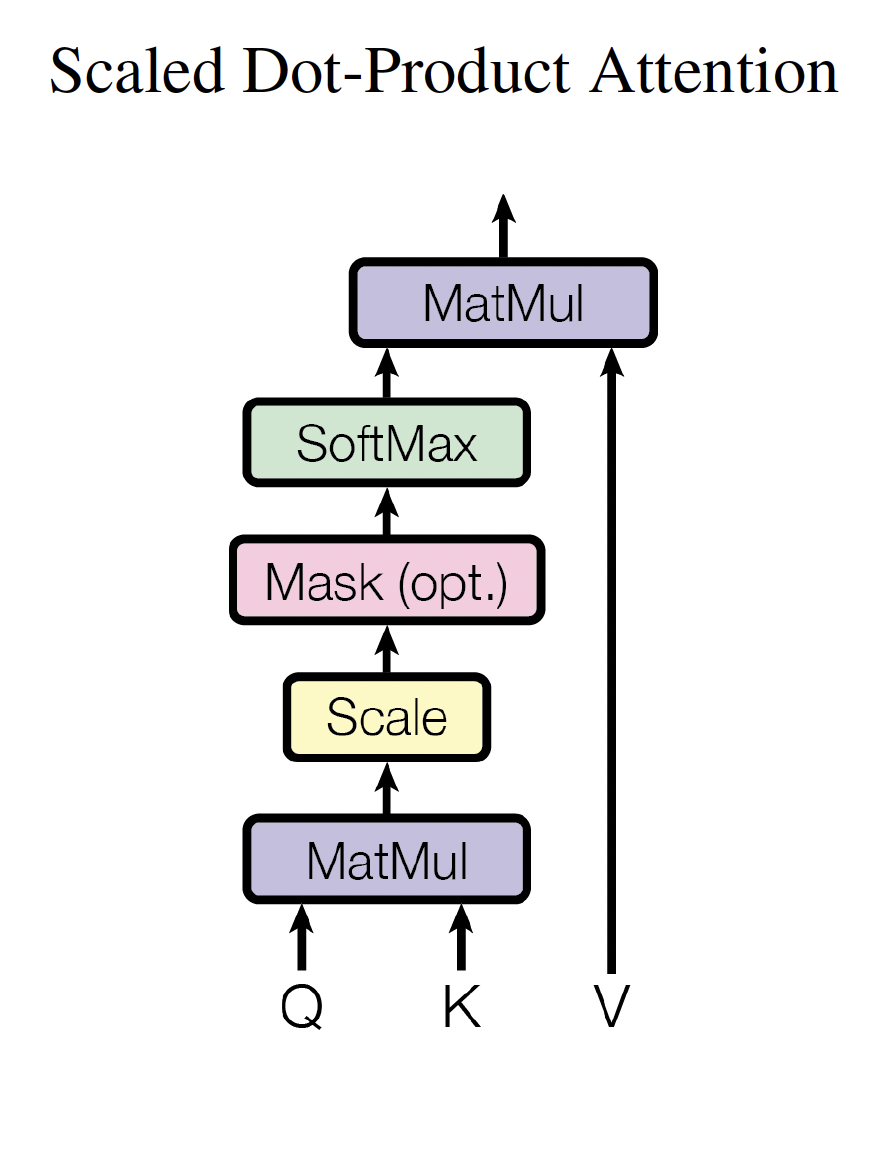
1. Scores de compatibilidad¶
$$ S = QK^\top $$Cada elemento $S_{i,j}$ mide la compatibilidad entre la query $i$ y la key $j$.
2. Escalamiento por $\sqrt{d_k}$¶
$$ S_{scaled} = \frac{QK^\top}{\sqrt{d_k}} $$¿Por qué dividir por $\sqrt{d_k}$?
Si los componentes de $q$ y $k$ tienen media 0 y varianza 1, entonces el producto punto:
$$ q \cdot k = \sum_{r=1}^{d_k} q_r k_r $$tiene varianza proporcional a $d_k$. Cuando $d_k$ crece, los scores pueden tener magnitudes grandes. Eso empuja al softmax hacia regiones saturadas, con distribuciones demasiado concentradas y gradientes pequeños.
Dividir por $\sqrt{d_k}$ mantiene la varianza de los scores en una escala más estable.
3. Máscaras¶
A veces se suma una máscara antes del softmax:
$$ S_{masked} = S_{scaled} + M $$Casos comunes:
- Máscara causal: impide mirar tokens futuros en el decoder.
- Máscara de padding: impide atender a posiciones que solo son relleno.
En la práctica, $M$ usa valores muy negativos en posiciones prohibidas para que después del softmax reciban probabilidad cercana a cero.
4. Softmax por fila¶
$$ A = \text{softmax}(S_{masked}) $$El softmax se aplica por fila. Cada fila de $A$ suma 1 y representa una distribución sobre las posiciones disponibles para una query.
5. Mezcla ponderada de values¶
$$ \text{Attention}(Q, K, V) = A V $$Cada salida es una suma ponderada de los values. Los pesos vienen de la compatibilidad entre queries y keys.
Intuición¶
Para cada token, la atención responde tres preguntas:
- ¿Desde dónde pregunto? -> query.
- ¿Con qué posiciones comparo? -> keys.
- ¿Qué contenido incorporo? -> values.
La atención no elimina la necesidad de orden. Si no agregamos codificación posicional, una capa de self-attention no distingue naturalmente entre permutaciones de los mismos tokens.
Propiedades clave¶
| Propiedad | Descripción |
|---|---|
| Diferenciable | Se entrena con backpropagation |
| Paralelizable | Todas las posiciones se pueden calcular en paralelo dentro de una capa |
| Flexible | Permite relaciones entre posiciones lejanas |
| Costosa en secuencias largas | La atención completa requiere una matriz $n \times n$, con costo $O(n^2)$ en longitud |
Multi-Head Attention¶
En lugar de calcular una sola atención, el Transformer calcula varias atenciones en paralelo y luego combina sus salidas.
Cada cabeza tiene sus propias proyecciones lineales. Esto permite que el modelo use distintos subespacios de representación para calcular patrones de compatibilidad.
Fórmula general¶
$$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h) W^O $$donde:
$$ \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) $$En el Transformer base original:
- $h = 8$ cabezas.
- $d_{model} = 512$.
- $d_k = d_v = d_{model}/h = 64$.
Las matrices típicas son:
- $W_i^Q \in \mathbb{R}^{d_{model} \times d_k}$
- $W_i^K \in \mathbb{R}^{d_{model} \times d_k}$
- $W_i^V \in \mathbb{R}^{d_{model} \times d_v}$
- $W^O \in \mathbb{R}^{h d_v \times d_{model}}$
Por qué usar múltiples cabezas¶
Una sola atención puede representar relaciones útiles, pero queda limitada a una única proyección de queries, keys y values. Varias cabezas permiten que el modelo aprenda distintos criterios de compatibilidad al mismo tiempo.
Ejemplos posibles:
- Una cabeza puede enfocarse en relaciones locales.
- Otra puede capturar dependencias sintácticas.
- Otra puede atender a marcadores posicionales o tokens especiales.
Esto no significa que cada cabeza tenga siempre una interpretación humana limpia. La especialización puede ocurrir, pero no está garantizada.
Explicación visual¶
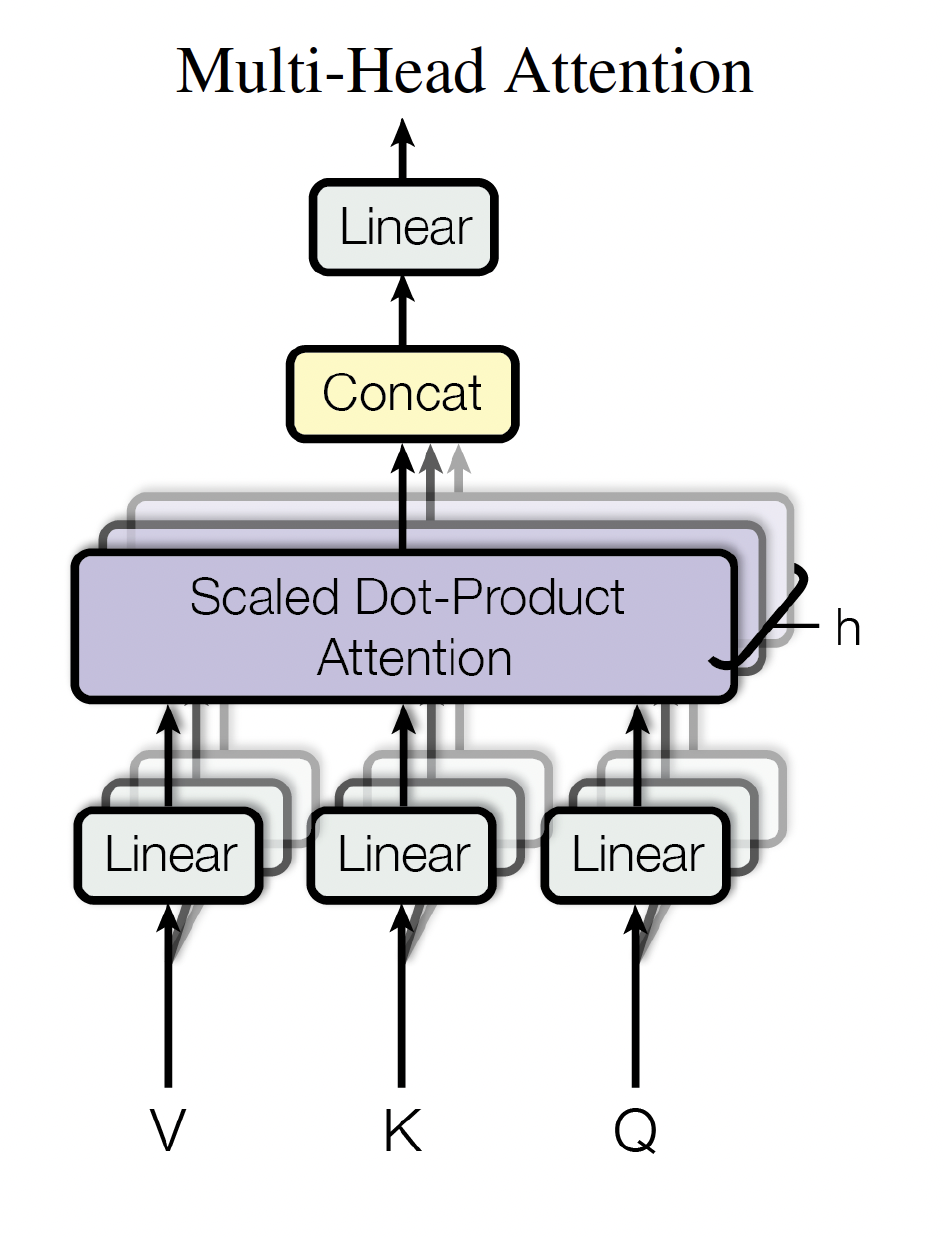
Proyecciones lineales independientes $Q$, $K$ y $V$ se proyectan a $h$ subespacios.
Atención paralela Cada cabeza calcula scaled dot-product attention.
Concatenación y proyección final Las salidas se concatenan y se proyectan con $W^O$ para volver a $d_{model}$.
Beneficios y cautelas¶
| Punto | Lectura rigurosa |
|---|---|
| Diversidad | Puede aprender patrones distintos por cabeza |
| Eficiencia | Las cabezas se calculan en paralelo |
| Capacidad | Aumenta expresividad sin hacer una sola atención enorme |
| Interpretación | Los patrones de atención son inspeccionables, pero no son explicación causal garantizada |
En resumen¶
Multi-head attention permite mezclar información desde varias proyecciones simultáneas. Es uno de los componentes centrales de Transformer, BERT, GPT, T5 y muchas arquitecturas posteriores.
Feed-Forward Networks (FFN)¶
Después de mezclar información entre tokens con atención, el Transformer aplica una red no lineal a cada posición.
En el paper original, esta red es una MLP de dos capas aplicada de forma idéntica e independiente a cada posición.
Definición formal¶
$$ \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 $$Esto corresponde a:
- Una capa lineal.
- Una activación ReLU.
- Una segunda capa lineal.
Cómo se aplica¶
Si la secuencia tiene 128 tokens, la misma FFN se aplica 128 veces, una vez por posición. Los pesos son compartidos entre posiciones.
Esto es importante:
- La atención mezcla información entre tokens.
- La FFN transforma cada representación ya contextualizada.
- La FFN no introduce interacción nueva entre posiciones.
Dimensiones en el Transformer base¶
En Vaswani et al. (2017):
- Entrada: $d_{model} = 512$.
- Capa interna: $d_{ff} = 2048$.
- Salida: $d_{model} = 512$.
Para qué sirve¶
La atención decide qué información combinar. La FFN decide cómo transformar esa información en cada posición.
En términos simples:
- Atención: comunicación entre tokens.
- FFN: procesamiento local por token.
En resumen¶
| Propiedad | Valor |
|---|---|
| Tipo de operación | MLP de dos capas por posición |
| Pesos | Compartidos entre posiciones |
| Interacción entre tokens | No directamente |
| Activación original | ReLU |
| Dimensiones originales | $512 \to 2048 \to 512$ |
Positional Encoding¶
La self-attention no tiene una noción intrínseca de orden. Por eso el Transformer agrega información posicional a los embeddings.
Por qué es necesario¶
La atención compara conjuntos de vectores. Si no agregamos posición, una capa de self-attention es equivarante a permutaciones: reordenar los tokens reordena las salidas, pero la operación no sabe por sí misma cuál token venía primero.
Por eso, frases con las mismas palabras pero distinto orden necesitan una señal adicional:
el gato comió al ratón no significa lo mismo que el ratón comió al gato.
Codificación posicional sinusoidal¶
El paper original usa funciones seno y coseno:
$$ \text{PE}_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) $$$$ \text{PE}_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) $$Donde:
| Término | Significado |
|---|---|
| $pos$ | Posición absoluta del token |
| $i$ | Índice de dimensión |
| $d_{model}$ | Dimensión del embedding del modelo |
| $10000^{2i/d_{model}}$ | Escala que controla la frecuencia |
Qué logra¶
La codificación sinusoidal entrega una señal multiescala:
- Dimensiones de alta frecuencia cambian rápido con la posición.
- Dimensiones de baja frecuencia cambian lento.
- La combinación de senos y cosenos permite representar posiciones absolutas y facilita que el modelo aprenda relaciones relativas.
El paper destaca una propiedad útil: para cualquier desplazamiento fijo $k$, $PE_{pos+k}$ puede expresarse como una transformación lineal de $PE_{pos}$. Esto hace plausible que el modelo aprenda relaciones relativas.
Ejemplo¶
En el Transformer base original:
- $d_{model} = 512$.
- Hay 512 valores posicionales por token.
- La mitad usa seno y la mitad usa coseno.
Para $i=0$, el denominador es $1$, así que la frecuencia es alta. Para dimensiones mayores, el denominador crece y la frecuencia baja.
Importante: BERT base no usa $d_{model}=512$. BERT base usa hidden size 768, 12 capas y 12 cabezas.
Intuición: representación multiescala¶
Una analogía útil es pensar en una representación binaria distribuida:
| Posición | Binario (8 bits) |
|---|---|
| 0 | 00000000 |
| 1 | 00000001 |
| 2 | 00000010 |
| 3 | 00000011 |
| 4 | 00000100 |
Cada bit cambia a una escala distinta. La codificación sinusoidal hace algo parecido, pero de forma continua y diferenciable.
Esta analogía es pedagógica. No debe leerse como una afirmación de que el paper derive la codificación desde binario.
Alternativa: embeddings posicionales aprendidos¶
Otra opción es aprender una matriz:
$$ P \in \mathbb{R}^{L \times d_{model}} $$Cada posición tiene un vector aprendible.
Ventajas:
- Mayor flexibilidad dentro del rango entrenado.
- Fácil de implementar.
Limitación:
- No extrapola naturalmente a posiciones mayores que las vistas durante entrenamiento.
Evidencia empírica en el paper¶
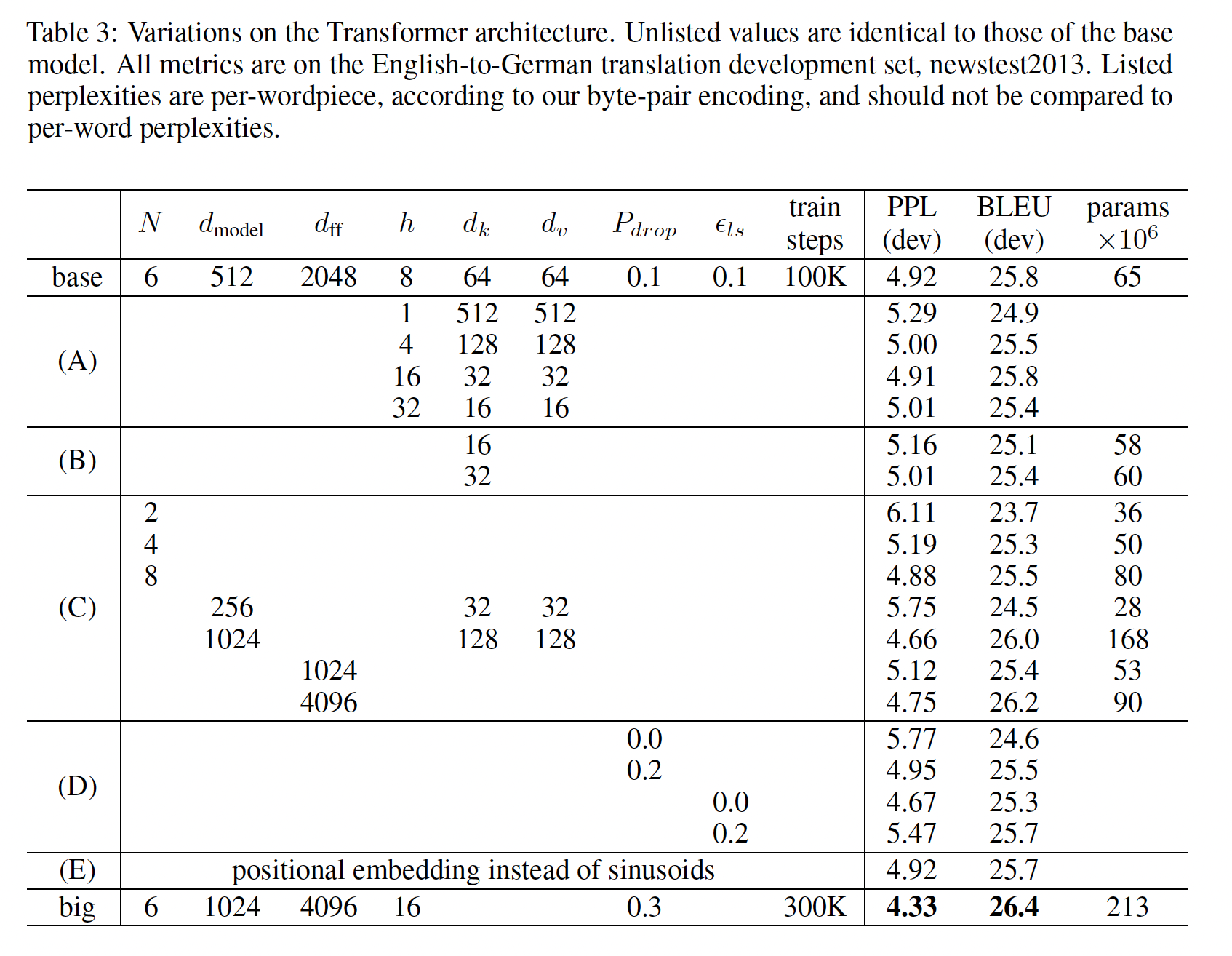
La Tabla 3 de Vaswani et al. compara codificación sinusoidal con embeddings posicionales aprendidos.
| Tipo de codificación | PPL (menor es mejor) | BLEU (mayor es mejor) |
|---|---|---|
| Sinusoidal | 4.92 | 25.8 |
| Aprendida | 4.92 | 25.7 |
Resultado: en ese experimento, el rendimiento fue casi idéntico.
La elección sinusoidal se justifica porque no agrega parámetros y puede facilitar extrapolación a longitudes no vistas. Esa extrapolación no es una garantía universal de buen desempeño; depende del modelo, los datos y la longitud evaluada.
En resumen¶
| Propiedad | Sinusoidal | Aprendida |
|---|---|---|
| Tiene parámetros aprendidos | No | Sí |
| Requiere entrenamiento | No | Sí |
| Extrapolación fuera del rango | Más plausible | Limitada por la matriz aprendida |
| Rendimiento en el paper | Comparable | Comparable |
Comparación entre RNN, CNN y Self-Attention¶
El Transformer no es mejor en todo por definición. Su ventaja principal en el paper es estructural: reduce la longitud de ruta entre posiciones y permite paralelizar el cómputo sobre tokens.
También tiene una limitación importante: la atención completa requiere comparar todos los pares de posiciones.
Tabla 1 del paper¶

Donde:
- $n$: longitud de la secuencia.
- $d$: dimensión de las representaciones.
- $k$: tamaño del kernel convolucional.
- $r$: tamaño de vecindad en atención restringida.
Lectura rigurosa¶
| Capa | Complejidad por capa | Operaciones secuenciales | Longitud máxima de ruta |
|---|---|---|---|
| Self-attention | $O(n^2 d)$ | $O(1)$ | $O(1)$ |
| Recurrente | $O(n d^2)$ | $O(n)$ | $O(n)$ |
| Convolucional | $O(k n d^2)$ | $O(1)$ | $O(\log_k n)$ |
| Self-attention restringida | $O(r n d)$ | $O(1)$ | $O(n/r)$ |
Interpretación¶
1. Paralelización¶
Las RNNs requieren pasos secuenciales sobre la longitud de la secuencia. En self-attention, todas las posiciones de una capa pueden calcularse en paralelo.
2. Dependencias de largo alcance¶
En self-attention completa, una posición puede conectarse con otra en una sola capa. En RNNs, la ruta entre extremos de la secuencia crece con $n$. En CNNs, depende de la profundidad, el kernel y posibles dilataciones.
3. Costo cuadrático¶
La ventaja de self-attention viene con costo $O(n^2)$ en memoria y cómputo respecto de la longitud. Por eso secuencias muy largas requieren variantes eficientes, atención local, sparse attention, recurrencia externa u otras estrategias.
4. Interpretabilidad¶
Las matrices de atención permiten inspeccionar patrones de mezcla de información. Eso ayuda intuitivamente, pero no convierte automáticamente al modelo en interpretable ni prueba causalmente por qué produjo una salida.
Conclusión equilibrada¶
Self-attention ofrece rutas cortas y alta paralelización. Esa combinación explica gran parte del éxito de los Transformers en NLP. Pero no elimina todos los problemas: el costo cuadrático y la interpretación de los pesos de atención siguen siendo temas activos de investigación.
import matplotlib.pyplot as plt
import numpy as np
n = np.arange(1, 129)
k = 2
rnn_path = n
cnn_path = np.maximum(1, np.ceil(np.log2(n)))
attn_path = np.ones_like(n)
plt.figure(figsize=(10, 6))
plt.plot(n, rnn_path, label='RNN: O(n)', linewidth=2, color='orange')
plt.plot(n, cnn_path, label=f'CNN: O(log_{k} n), esquema', linewidth=2, color='brown')
plt.plot(n, attn_path, label='Self-Attention: O(1)', linewidth=2, color='crimson')
plt.title('Longitud máxima de ruta entre posiciones', fontsize=14)
plt.xlabel('Longitud de secuencia (n)', fontsize=12)
plt.ylabel('Longitud máxima de ruta', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.6)
plt.legend(fontsize=12)
plt.tight_layout()
plt.show()

Gráfico: longitud máxima de ruta¶
El gráfico muestra una comparación esquemática de cuántos pasos estructurales necesita la información para viajar entre dos posiciones lejanas.
- RNN: la ruta crece linealmente con la secuencia, $O(n)$.
- CNN: la ruta puede crecer como $O(\log_k n)$ si se apilan capas para expandir el campo receptivo. El valor exacto depende del kernel, dilataciones y arquitectura.
- Self-attention: cualquier posición puede atender a cualquier otra en una sola capa, por eso la ruta máxima es $O(1)$.
Por qué importa¶
Una ruta más corta facilita que información y gradientes conecten posiciones lejanas. Esta es una razón importante para entender el éxito del Transformer frente a modelos recurrentes en muchas tareas de lenguaje.
Pero no es toda la historia:
- Self-attention tiene ruta corta.
- Self-attention completa también tiene costo cuadrático en $n$.
- Para secuencias largas, esa limitación se vuelve central.
Lectura¶
El Transformer no gana porque ignore el orden ni porque la atención sea una explicación perfecta.
Gana porque combina rutas cortas, paralelización, embeddings posicionales y entrenamiento autosupervisado escalable.
Resumen final¶
El Transformer reemplaza las capas recurrentes y convolucionales del encoder-decoder original por atención, FFN, residuales, normalización y codificación posicional.
Ideas centrales:
- La motivación original fue traducción automática neuronal y transducción de secuencias.
- La atención encoder-decoder reduce el cuello de botella de contexto y aprende alineamientos flexibles.
- La self-attention mezcla información entre tokens de una misma secuencia.
- La multi-head attention calcula varias atenciones en paralelo sobre subespacios distintos.
- La codificación posicional agrega información de orden que la atención no tiene por sí sola.
- La gran ventaja estructural es paralelización y ruta corta entre posiciones.
- La gran limitación técnica es el costo cuadrático de la atención completa en secuencias largas.
- La interpretabilidad de la atención debe tratarse con cautela: ayuda a inspeccionar, pero no garantiza explicación causal.
- Las capacidades emergentes en LLMs posteriores no deben atribuirse solo al Transformer: dependen también de escala, datos, objetivo de entrenamiento, optimización y evaluación.
Literatura clave¶
- Wu et al. (2016). Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.
- Vaswani et al. (2017). Attention Is All You Need. NeurIPS.
- Bahdanau, Cho & Bengio (2014). Neural Machine Translation by Jointly Learning to Align and Translate.
- Luong, Pham & Manning (2015). Effective Approaches to Attention-based Neural Machine Translation.
- Devlin et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Radford et al. (2018). Improving Language Understanding by Generative Pre-Training.
- Radford et al. (2019). Language Models are Unsupervised Multitask Learners.
- Brown et al. (2020). Language Models are Few-Shot Learners.
- Jain & Wallace (2019). Attention is not Explanation.
- Wiegreffe & Pinter (2019). Attention is not not Explanation.
- Tay et al. (2020). Efficient Transformers: A Survey.
- Wei et al. (2022). Emergent Abilities of Large Language Models.
- Schaeffer, Miranda & Koyejo (2023). Are Emergent Abilities of Large Language Models a Mirage?