Transformers - BERT¶
Modelos de Machine Learning No-Supervisados¶
Dr. Cristian Candia¶
Universidad del Desarrollo (UDD), Chile¶
- Director, Computational Research in Social Sciences Lab
- Faculty, Data Science Institute, School of Engineering
Northwestern University, United States¶
- External Faculty, Northwestern Institute on Complex Systems (NICO), Kellogg School of Management
Founder & CSTO¶
- Capybara. Capybara ayuda a establecimiento educacionales a detectar señales tempranas de bullying, medir convivencia escolar y tomar decisiones basadas en evidencia para prevenir conflictos a tiempo.
BERT: Bidirectional Encoder Representations from Transformers¶

¿Qué es BERT?¶
BERT es un modelo de lenguaje profundamente preentrenado sobre grandes corpus (Wikipedia + BooksCorpus), basado exclusivamente en la arquitectura Transformer, usando solo el encoder.
Fue propuesto por Devlin et al., 2019 en el paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
A diferencia de modelos como GPT (que son autoregresivos), BERT es bidireccional:
aprende representaciones considerando simultáneamente el contexto a la izquierda y a la derecha de cada token.
Esto lo hace altamente efectivo para tareas de comprensión de lenguaje natural (NLU) como:
- Clasificación de texto
- Pregunta-respuesta
- Inferencia textual
- Reconocimiento de entidades (NER)
Objetivo de preentrenamiento #1: Masked Language Modeling (MLM)¶
BERT no predice la siguiente palabra, sino que enmascara aleatoriamente algunos tokens del input y entrena el modelo para predecirlos usando el contexto completo.
Ejemplo:¶
El `[MASK]` corre por el parque.BERT predice:
niño,perro,hombre, etc.
Usando toda la oración, antes y después de la máscara.
Esto fuerza al modelo a construir representaciones verdaderamente contextuales.
Detalles técnicos del paper:¶
Inspiración:
MLM se basa en el clásico Cloze Task (Taylor, 1953), donde se eliminan palabras de una frase y se deben recuperar.Cómo se construye el enmascaramiento (Apéndice A.1 del paper):
- 15% de los tokens se seleccionan para predicción.
- 80% se reemplazan por
[MASK] - 10% se reemplazan por una palabra aleatoria
- 10% se dejan sin cambiar
- 80% se reemplazan por
- Esto evita que el modelo dependa exclusivamente del token
[MASK](que no aparece en fine-tuning).
- 15% de los tokens se seleccionan para predicción.
Comparación con otros modelos:
- GPT es unidireccional (solo ve tokens anteriores).
- ELMo combina dos modelos independientes left-to-right y right-to-left.
- BERT aplica atención bidireccional en cada capa → mayor contextualización.
Construcción de los embeddings y enmascaramiento¶
La figura a continuación ilustra cómo se construyen los embeddings de entrada para BERT y cómo se aplica el enmascaramiento.
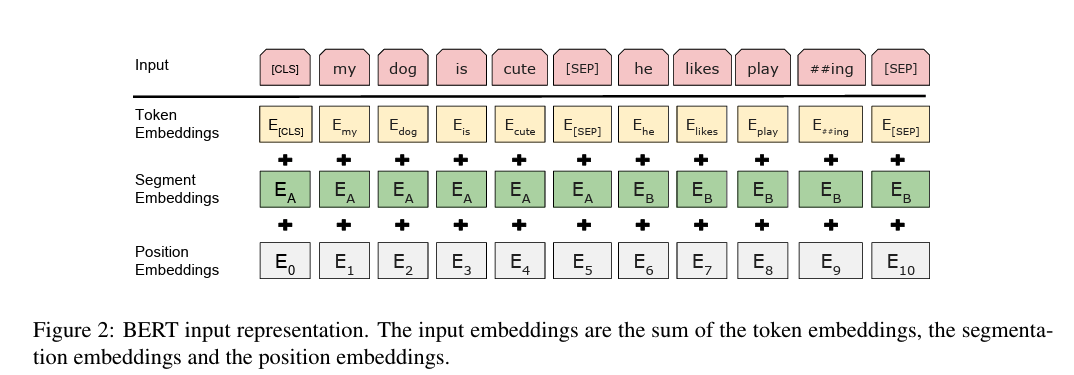
La figura muestra cómo BERT construye la representación de entrada combinando tres tipos de vectores:
1. Token Embeddings (Fila amarilla)¶
- Representan el significado del token (palabra o subpalabra).
- Se obtiene a partir de una tabla de embeddings aprendida (como en Word2Vec).
Incluye tokens especiales como:
[CLS]: resumen de toda la secuencia (para clasificación)[SEP]: separador entre oraciones A y B##ing: indica que es una subpalabra (WordPiece)
Ejemplo:
"playing"puede tokenizarse como"play"+"##ing"Nota: BERT usa WordPiece para tokenizar, lo que permite manejar vocabularios grandes y palabras raras.
¿Cómo se reconoce una subpalabra?¶
Se agrega el prefijo ## al token para indicar que esa pieza va unida a la palabra anterior. Ejemplo:
plaintext
"playing" → ["play", "##ing"]
"unbelievable" → ["un", "##bel", "##iev", "##able"]Esto es una convención del tokenizer, no una predicción del modelo.
¿Cómo funciona WordPiece?¶
- Se entrena un vocabulario de tokens basado en frecuencia sobre un gran corpus de texto.
- Comienza con un vocabulario que contiene solo caracteres individuales.
- Luego, fusiona los pares de subpalabras más frecuentes repetidamente hasta llegar al tamaño deseado del vocabulario (por ejemplo, 30.000).
- El resultado es un conjunto de unidades comunes: palabras completas frecuentes + subpalabras útiles.
¿Por qué es útil?¶
- Maneja palabras desconocidas: si no está la palabra completa, la descompone.
- Reduce el tamaño del vocabulario → modelo más eficiente.
- Conserva significado semántico parcial.
¿Dónde vive esto en BERT?¶
Cuando usas el tokenizer de Hugging Face:
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
Internamente usa un archivo vocab.txt con los tokens (palabras y subpalabras) y aplica WordPiece para dividir el texto. No es un modelo, sino un algoritmo + tabla de frecuencias preentrenada.
En resumen:¶
| ¿Es otro modelo? | ❌ No |
|---|---|
| ¿Es aprendido? | ✅ Sí, pero offline, antes del preentrenamiento |
| ¿Es determinista? | ✅ Sí, una vez fijado el vocabulario |
| ¿Cómo marca una subpalabra? | Con el prefijo ## |
2. Segment Embeddings (Fila verde)¶
- Indican a qué oración pertenece cada token.
BERT trabaja con pares de oraciones (A y B).
- Tokens de la primera oración → etiqueta $E_A$
- Tokens de la segunda oración → etiqueta $E_B$
Esto permite al modelo "razonar" sobre relaciones entre frases (por ejemplo, en Next Sentence Prediction o en Pregunta-Respuesta).
3. Position Embeddings (Fila gris)¶
- Codifican la posición del token en la secuencia.
- Como BERT no es secuencial, necesita información explícita de orden.
- Se usa codificación posicional aprendida (o sinusoidal en otros modelos).
Cada token recibe un vector que representa su posición: $E_0, E_1, E_2, \dots$
Composición final¶
Para cada token, BERT suma los tres vectores:
$$ \text{InputEmbedding} = \text{TokenEmbedding} + \text{SegmentEmbedding} + \text{PositionEmbedding} $$Esta suma da como resultado una representación rica y diferenciada para cada token, que luego es procesada por las capas del Transformer.
Notas clave:¶
- Todos los vectores tienen dimensión $d = 768$ (en BERT base).
La figura muestra un ejemplo con dos oraciones:
[CLS] my dog is cute [SEP]→ segmento Ahe likes play ##ing [SEP]→ segmento B
- La máscara (MLM) se aplica después de construir este embedding.
Conclusión¶
Esta construcción tridimensional (token + segmento + posición) permite a BERT:
- Entender el significado, la estructura y el orden del input
- Manejar tareas con una o dos oraciones
- Generalizar a múltiples tareas downstream con una única arquitectura
Masked Language Modeling permite a BERT aprender representaciones profundamente contextuales y bidireccionales, lo cual es esencial para tareas como clasificación, NER, inferencia y QA.
BERT es el primer modelo ampliamente exitoso que usa este tipo de preentrenamiento, y sentó las bases para modelos posteriores como RoBERTa, DistilBERT, ALBERT, SpanBERT y muchos otros.
Segunda tarea de preentrenamiento: Next Sentence Prediction (NSP)¶
Además de la tarea principal de Masked Language Modeling (MLM), BERT se preentrena con una tarea auxiliar llamada Next Sentence Prediction (NSP).
Objetivo¶
Dado un par de oraciones (A, B), el modelo debe predecir si B sigue inmediatamente a A en el texto original o si B es una oración aleatoria.
Esta tarea busca entrenar a BERT para comprender relaciones entre frases, lo que es crucial en tareas como:
- Inferencia textual (e.g., MNLI, RTE)
- Preguntas y respuestas (e.g., SQuAD)
- Parafraseo, resumen y búsqueda semántica
Ejemplos del paper¶
Ejemplo positivo (IsNext) Entrada:
[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]Etiqueta:
IsNextEjemplo negativo (NotNext) Entrada:
[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flightless birds [SEP]Etiqueta:
NotNext
¿Cómo se construyen los datos?¶
- 50% de los pares (A, B) son frases consecutivas reales del corpus →
IsNext - 50% de los pares son frases aleatorias emparejadas artificialmente →
NotNext
Ambas se concatenan en un único input con tokens especiales:
[CLS] oración A [SEP] oración B [SEP]Además, cada token recibe un segment embedding que indica si pertenece a la oración A o a la B.
¿Cómo se usa?¶
- El vector correspondiente al token
[CLS]se interpreta como una representación agregada del par (A, B). - Este vector se pasa por una capa softmax para resolver una clasificación binaria: ¿es B la siguiente oración?
Evidencia empírica del paper¶
BERT logra 97–98% de accuracy en la tarea de NSP durante el preentrenamiento.
Además, la sección de ablation studies (Tabla 5) muestra que quitar NSP produce caídas de rendimiento significativas en tareas como:
| Modelo | QNLI | MNLI | SQuAD 1.1 |
|---|---|---|---|
| BERTBASE (con NSP) | 88.4 | 84.4 | 88.5 |
| BERTBASE (sin NSP) | 84.9 | 83.9 | 87.9 |
| LTR (sin NSP, estilo GPT) | 84.3 | 82.1 | 77.8 |
Conclusión: NSP ayuda a capturar relaciones discursivas, especialmente importantes en tareas que involucran múltiples frases o razonamiento contextual.
¿Por qué modelos posteriores lo eliminaron?¶
Modelos como RoBERTa (Robustly Optimized BERT Approach) eliminaron NSP y aun así mejoraron resultados, entrenando con más datos y más pasos. Pero el paper de BERT demuestra que, en su configuración original, NSP sí mejora el desempeño en múltiples tareas.
Hoy se considera que NSP:
- Es útil si el corpus tiene relaciones frase a frase (Wikipedia, libros).
- No siempre es necesaria si se entrena con más datos y por más tiempo (como en RoBERTa).
En resumen¶
NSP entrena a BERT para reconocer relaciones entre frases, crucial para tareas complejas de comprensión. Aunque ha sido debatida y reemplazada en modelos posteriores, fue clave para el éxito de BERT y su capacidad de generalización.
Arquitectura de BERT¶
BERT (Bidirectional Encoder Representations from Transformers) se basa exclusivamente en encoders del Transformer. No utiliza decodificadores, ya que su objetivo no es generar texto secuencialmente, sino entenderlo profundamente.
BERT es una pila de bloques Transformer encoder. Cada capa incluye:
- Multi-head self-attention (bidireccional)
- Feedforward network (con activación GELU en BERT original)
- Normalización + conexiones residuales
Variantes principales¶
| Modelo | Capas (L) | Dimensión oculta (H) | Cabezas de atención (A) | Parámetros |
|---|---|---|---|---|
| BERT Base | 12 | 768 | 12 | 110M |
| BERT Large | 24 | 1024 | 16 | 340M |
- El tamaño del feedforward es típicamente
4 * H(3072 en Base, 4096 en Large). - Los outputs de cada token son contextualizados por múltiples capas de atención bidireccional.
Pipeline completo¶
La siguiente figura resume el flujo completo de entrenamiento y fine-tuning de BERT:
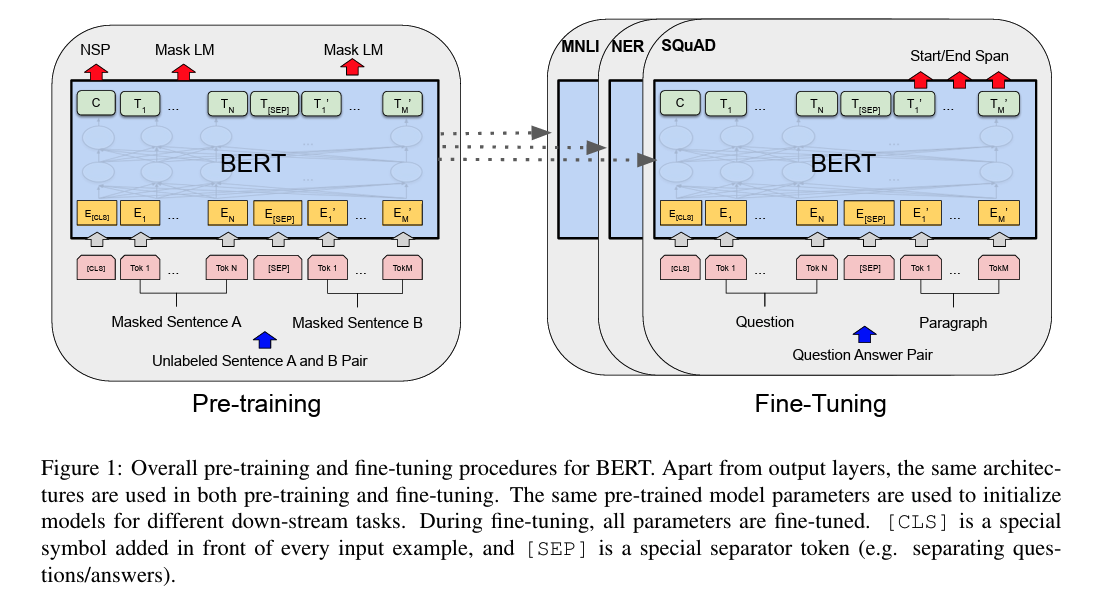
La figura ilustra el proceso de preentrenamiento y ajuste fino (fine-tuning) de BERT, mostrando cómo se adapta a diferentes tareas de procesamiento del lenguaje natural (NLP). La figura está dividida en dos grandes bloques:
Izquierda: Pre-Training¶
Este bloque ilustra cómo se entrena BERT originalmente antes de usarlo en tareas específicas.
Input: Pares de oraciones¶
- BERT recibe un par de oraciones no etiquetadas, llamadas sentence A y sentence B.
El input total tiene el siguiente formato:
[CLS] oración A [SEP] oración B [SEP]Cada token es representado por:
- Token embedding (rosado claro)
- Segment embedding (A o B)
- Positional embedding (no visible aquí, pero implícito)
Dos tareas de preentrenamiento:¶
NSP (Next Sentence Prediction)
- Usando el vector final del token
[CLS](izquierda arriba: “C”), el modelo predice si la oración B sigue naturalmente a la A. - Esto se representa con la flecha roja hacia NSP (izquierda arriba).
- Usando el vector final del token
MLM (Masked Language Modeling)
- Algunos tokens en las frases A y B están reemplazados por
[MASK]. - El modelo predice el token original solo a partir del contexto.
- Flechas rojas etiquetadas como Mask LM apuntan a los embeddings de tokens enmascarados: $T_M'$, $T_N$, etc.
Todo esto se realiza sobre datos no anotados, como Wikipedia o BooksCorpus.
- Algunos tokens en las frases A y B están reemplazados por
Derecha: Fine-Tuning¶
Una vez preentrenado, BERT se adapta a tareas específicas con mínimos cambios. Este bloque muestra cómo la misma arquitectura base (la caja azul “BERT”) se reutiliza para tareas diferentes al agregar una capa de salida específica.
Ejemplos en la figura:¶
- MNLI / NER: tareas de clasificación de frases o etiquetado por token.
Se conecta una capa sobre
[CLS]o sobre cada token según la tarea.
¿Qué significan MNLI y NER?¶
Ambos son tareas estándar de NLP (Natural Language Processing) que BERT puede resolver, y que aparecen en la parte de Fine-Tuning de la Figura 1 del paper.
MNLI — Multi-Genre Natural Language Inference¶
- Es un benchmark de inferencia textual (textual entailment).
Objetivo: dado un par de frases (premisa + hipótesis), predecir si la hipótesis:
- Se infiere de la premisa (entailment)
- La contradice (contradiction)
- Es neutral (no hay suficiente info)
Ejemplo:¶
Premisa: “El hombre está comiendo pasta.” Hipótesis: “La persona está cenando.” → Entailment
NER — Named Entity Recognition¶
- Tarea clásica de etiquetado secuencial (token-level).
Objetivo: detectar entidades nombradas en un texto y clasificar su tipo:
- Persona, Organización, Lugar, Fecha, etc.
Ejemplo:¶
Texto: “Barack Obama fue presidente de Estados Unidos.” Etiquetas:
Barack → B-PER
Obama → I-PER
fue → O
presidente → O
Estados → B-LOC
Unidos → I-LOCEn el fine-tuning de BERT, se puede adaptar:
- A tareas tipo MNLI usando el token
[CLS]→ clasificación a nivel frase o par de frases. - A tareas tipo NER usando los embeddings por token → clasificación a nivel palabra.
- A tareas tipo MNLI usando el token
La figura muestra cómo la misma arquitectura base sirve para tareas con objetivos y granularidades diferentes.
SQuAD (Pregunta-Respuesta):
- Input = pregunta + párrafo, separados por
[SEP]. - El modelo predice la posición de inicio y fin de la respuesta en el párrafo.
- Esto se muestra con las flechas rojas a “Start/End Span” en el bloque final.
- Cada token del párrafo (por ejemplo, $T'_1$, $T'_M$) recibe una puntuación para indicar si es inicio o fin de la respuesta.
- Input = pregunta + párrafo, separados por
Detalles clave de la arquitectura (en ambas fases):¶
[CLS]:- Token inicial especial.
- Su embedding final se usa para clasificación a nivel frase o par.
[SEP]:- Separador entre frases o entre pregunta y contexto.
- También marca el final de la secuencia.
$E_{\text{[CLS]}}, E_i, \dots$:
Representaciones de entrada de los tokens, que combinan:
- Embedding del token
- Segment embedding (A o B)
- Positional embedding
BERT (bloque azul):
- Es la pila de N codificadores Transformer que procesan la secuencia.
- La arquitectura es la misma en preentrenamiento y en fine-tuning.
¿Qué representa esta figura conceptualmente?¶
Que una sola arquitectura universal puede aprender representaciones del lenguaje a gran escala (pre-training), y luego adaptarse con mínimos cambios (fine-tuning) a una gran variedad de tareas downstream: clasificación, QA, NER, etc.
Esto es el corazón del éxito de BERT y el motivo de su enorme impacto en NLP moderno.
En resumen¶
| Elemento | Rol en la figura |
|---|---|
[CLS] |
Resumen global para clasificación (MLM o downstream) |
[SEP] |
Separador de frases/pregunta-contexto |
| MLM | Predice tokens ocultos durante preentrenamiento |
| NSP | Predice si la segunda oración sigue a la primera |
| Fine-tuning | Reutiliza BERT para tareas específicas con mínima adaptación |
| Start/End Span | En QA, predice posiciones de respuesta en el contexto |
¿Por qué BERT marcó un antes y un después?¶
- Introduce el paradigma de preentrenamiento universal + fine-tuning.
- Representaciones altamente contextuales y bidireccionales.
- Puede adaptarse con poca información etiquetada a tareas específicas.
- Rompió récords en múltiples benchmarks: GLUE, SQuAD, MNLI, SST, etc.
Legado de BERT¶
Inspiró toda una generación de modelos derivados:
- RoBERTa: elimina NSP y entrena más tiempo con más datos.
- DistilBERT: versión más liviana por destilación.
- ALBERT: comparte parámetros y reduce dimensionalidad.
- SpanBERT, BioBERT, CodeBERT: adaptaciones a tareas/dominios específicos.
En resumen¶
- BERT se basa en encoders bidireccionales del Transformer.
- Usa preentrenamiento con MLM + NSP sobre corpus masivos.
- Produce embeddings profundamente contextuales.
- Se adapta fácilmente a múltiples tareas con una arquitectura fija.
- Ha sido la base de toda la evolución moderna en NLP.
Conclusión¶
La atención es el corazón del Transformer.
Permite que el modelo aprenda dinámicamente qué partes del input son relevantes para construir representaciones contextualizadas de cada token.
La atención se puede aplicar a diferentes niveles de granularidad, desde palabras individuales hasta frases completas, lo que la hace versátil para diversas tareas de procesamiento del lenguaje natural.
La atención se puede ver como un mecanismo de filtrado que decide qué información es relevante y cómo combinarla para formar una representación contextualizada.
La atención permite capturar dependencias de largo alcance y ha sido uno de los avances más influyentes en la historia reciente del procesamiento de lenguaje natural.
Benchmarks y datasets clásicos en NLP¶
GLUE — General Language Understanding Evaluation¶
GLUE es un benchmark compuesto por 9 tareas de comprensión de lenguaje natural, diseñado para evaluar modelos preentrenados en una variedad de capacidades: clasificación, inferencia, correlación semántica, etc.
Fue propuesto por Wang et al. (2018) y contiene tareas como:
- MNLI: inferencia textual
- SST-2: análisis de sentimiento
- QQP: detección de preguntas duplicadas
CoLA: aceptabilidad gramatical
Se mide con una métrica agregada del desempeño promedio en todas las tareas (macro score). BERT fue el primer modelo en superar el rendimiento humano promedio en GLUE.
SQuAD — Stanford Question Answering Dataset¶
Dataset de pregunta-respuesta extractiva sobre párrafos reales de Wikipedia.
Hay dos versiones:
SQuAD v1.1: Cada pregunta tiene una respuesta siempre contenida literalmente en el texto.
SQuAD v2.0: Introduce preguntas sin respuesta posible, forzando al modelo a aprender cuándo no debe responder.
Formato:
Input: (pregunta, párrafo)
- Output: (índice de inicio, índice de fin) de la respuesta en el texto.
BERT estableció nuevos SOTA (state-of-the-art) en F1 y Exact Match cuando fue publicado.
MNLI — Multi-Genre Natural Language Inference¶
Tarea de inferencia textual a gran escala y en múltiples géneros.
El modelo debe decidir si una hipótesis es:
- una inferencia de la premisa (Entailment),
- una contradicción (Contradiction), o
neutral (Neutral).
Ejemplo:
Premisa: “Un hombre está tocando la guitarra.”
- Hipótesis: “Una persona está haciendo música.” → Entailment
Incluye ejemplos de libros, transcripciones de habla, artículos de viaje, etc.
SST-2 — Stanford Sentiment Treebank (versión 2)¶
Tarea clásica de análisis de sentimiento binario (positivo vs. negativo).
Cada ejemplo es una frase extraída de críticas de películas, que debe ser clasificada como:
- Positiva (e.g., “A triumph of independent cinema.”)
- Negativa (e.g., “Wasted talent and missed opportunity.”)
SST-2 es parte de GLUE y ha sido usada como benchmark para modelos desde RNNs hasta Transformers.
En resumen¶
| Benchmark | Tarea principal | Tipo de salida | Aplicación clave |
|---|---|---|---|
| GLUE | Varias tareas NLU | Clasificación, regresión | Evaluación general de NLP |
| SQuAD | Pregunta-respuesta | Índice (start, end) | QA extractiva sobre texto |
| MNLI | Inferencia textual | 3 clases | Razonamiento semántico |
| SST-2 | Análisis de sentimiento | Positivo / Negativo | Opinión y clasificación |
Ejemplo: Pregunta-Respuesta extractiva en español con BERT¶
Objetivo:¶
Usar BERT para responder una pregunta basada en un contexto real.
Contexto (extraído de Wikipedia):¶
El ajedrez es un juego de estrategia entre dos jugadores. Se juega en un tablero cuadrado dividido en 64 casillas, alternando colores. El objetivo es dar jaque mate al rey del oponente, lo que significa que el rey está amenazado y no puede escapar del ataque.
Pregunta:¶
¿Cuál es el objetivo del ajedrez?
¿Qué hace BERT?¶
Encuentra el fragmento del texto que responde a la pregunta. En este caso, BERT debería extraer:
dar jaque mate al rey del oponente
Código con transformers de Hugging Face (Python)¶
import os
os.environ["USE_TF"] = "0"
os.environ["TRANSFORMERS_NO_TF"] = "1"
os.environ["TOKENIZERS_PARALLELISM"] = "false"
import torch
from transformers import pipeline
# Usamos un modelo encoder tipo RoBERTa fine-tuneado para QA extractiva en español.
# Conceptualmente ilustra la misma familia encoder-only que BERT, aunque RoBERTa elimina NSP y ajusta el preentrenamiento.
qa_model_name = "PlanTL-GOB-ES/roberta-base-bne-sqac"
device_id = 0 if torch.cuda.is_available() else -1
qa = pipeline(
"question-answering",
model=qa_model_name,
tokenizer=qa_model_name,
device=device_id,
)
contexto = """
El ajedrez es un juego de estrategia entre dos jugadores. Se juega en un tablero cuadrado dividido en 64 casillas,
alternando colores. El objetivo es dar jaque mate al rey del oponente, lo que significa que el rey está amenazado y no puede escapar del ataque.
"""
pregunta = "¿Cuál es el objetivo del ajedrez?"
respuesta = qa(question=pregunta, context=contexto)
print("Respuesta:", respuesta["answer"])
print("Confianza:", round(respuesta["score"], 3))
¿Qué pasa internamente?¶
- El input se tokeniza como una secuencia con tokens especiales de inicio, separación y fin. En BERT suelen representarse como
[CLS]y[SEP]; en RoBERTa se usan tokens equivalentes como<s>y</s>. - El encoder produce embeddings contextuales para cada token.
- Una cabeza de QA predice dos distribuciones: una para el índice de inicio y otra para el índice de fin de la respuesta dentro del contexto.
¿Qué muestra este ejemplo?¶
- La respuesta es extractiva: el modelo selecciona un span presente en el texto, no inventa una respuesta libre.
- El modelo fue fine-tuneado para QA; el BERT/RoBERTa base por sí solo no resuelve esta tarea sin una cabeza entrenada.
- La calidad depende del dominio, del idioma y de que la respuesta esté efectivamente en el contexto.
Tarea: Análisis de Sentimiento en Español¶
Dado un texto (ej. una reseña), el modelo debe predecir si el sentimiento es positivo, negativo o neutral.
Modelo recomendado: pysentimiento/robertuito-sentiment-analysis¶
- Modelo basado en RoBERTa, entrenado específicamente para análisis de sentimiento en español.
- Fine-tuneado sobre corpus anotados como TASS y ML-Senticon.
Uso en código¶
import torch
from transformers import pipeline
device_id = 0 if torch.cuda.is_available() else -1
# Modelo RoBERTa entrenado para sentimiento en español.
sentimiento = pipeline(
"sentiment-analysis",
model="pysentimiento/robertuito-sentiment-analysis",
tokenizer="pysentimiento/robertuito-sentiment-analysis",
truncation=True,
device=device_id,
)
textos = [
"Me encantó la película, fue emocionante de principio a fin.",
"La comida estaba fría y el servicio fue terrible.",
"Está bien, pero no es nada especial.",
"Definitivamente, la mejor forma de quedarme dormido fue ver esta película.",
]
for texto in textos:
resultado = sentimiento(texto)[0]
print(f"Texto: {texto}")
print(f"Sentimiento: {resultado['label']} (confianza: {resultado['score']:.3f})\n")
¿Qué hace el modelo internamente?¶
- Tokeniza el texto y agrega tokens especiales de clasificación/separación según la arquitectura.
- Cada token es embebido y procesado por el encoder.
Un vector agregado de la secuencia se usa para clasificar el texto completo como:
- POS: positivo
- NEG: negativo
- NEU: neutral
¿Por qué es útil este ejemplo?¶
- Funciona con datos reales en español.
- Usa un modelo fine-tuneado específicamente para esta tarea.
- Puede adaptarse fácilmente a aplicaciones reales: redes sociales, reseñas, feedback, etc.
- Es reproducible, didáctico y muestra el uso directo de BERT en tareas prácticas.
¿Qué es una ambigüedad semántica?¶
Es cuando una palabra tiene múltiples significados posibles, y el significado correcto depende del contexto. Ejemplo típico:
Palabra ambigua: "banco"¶
Oración 1 — Sentido financiero:¶
"Fui al banco a retirar dinero."
→ Aquí banco significa institución financiera.
Oración 2 — Sentido físico/objeto:¶
"Nos sentamos en un banco del parque para conversar."
→ Aquí banco es un asiento.
¿Por qué es relevante en modelos de lenguaje?¶
Modelos como Word2Vec o fastText:¶
- Asignan un único vector por palabra.
- No pueden distinguir los significados de "banco" en distintos contextos.
Modelos como BERT:¶
- Generan embeddings contextuales.
- El vector de "banco" depende del resto de la oración.
- Así, "banco" tendrá representaciones diferentes en cada ejemplo.
Ejemplo práctico con BERT¶
from transformers import AutoTokenizer, AutoModel
import torch
modelo_bert = "dccuchile/bert-base-spanish-wwm-uncased"
tokenizer = AutoTokenizer.from_pretrained(modelo_bert)
model = AutoModel.from_pretrained(modelo_bert, add_pooling_layer=False)
model.eval()
def embedding_de_palabra(texto, palabra):
"""Extrae el embedding contextual de una palabra, promediando subtokens si hace falta."""
inputs = tokenizer(texto, return_tensors="pt")
target_ids = tokenizer(palabra, add_special_tokens=False)["input_ids"]
input_ids = inputs["input_ids"][0].tolist()
inicio = None
for i in range(len(input_ids) - len(target_ids) + 1):
if input_ids[i:i + len(target_ids)] == target_ids:
inicio = i
break
if inicio is None:
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
raise ValueError(f"No se encontró '{palabra}' en la tokenización: {tokens}")
with torch.no_grad():
salida = model(**inputs).last_hidden_state[0]
fin = inicio + len(target_ids)
return salida[inicio:fin].mean(dim=0)
oracion1 = "Fui al banco a retirar dinero."
oracion2 = "Nos sentamos en un banco del parque."
vec1 = embedding_de_palabra(oracion1, "banco")
vec2 = embedding_de_palabra(oracion2, "banco")
similitud = torch.nn.functional.cosine_similarity(vec1.unsqueeze(0), vec2.unsqueeze(0)).item()
print(f"Similitud contextual para 'banco': {similitud:.4f}")
Resultado esperado: similitud baja, indicando que la representación contextual de “banco” cambia según el uso de la palabra.
Prueba más ejemplos:¶
| Palabra ambigua | Sentido 1 | Sentido 2 |
|---|---|---|
| batería | Conjunto de instrumentos musicales | Fuente de energía |
| ratón | Animal | Dispositivo de computadora |
| clase | Lección educativa | Categoría o tipo |
| estrella | Astro en el cielo | Celebridad |
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
frases = {
"banco_dinero": ("Fui al banco a retirar dinero.", "banco"),
"banco_parque": ("Nos sentamos en un banco del parque.", "banco"),
"raton_animal": ("El ratón salió corriendo por el jardín.", "ratón"),
"raton_pc": ("Mi ratón inalámbrico dejó de funcionar.", "ratón"),
"estrella_cielo": ("La estrella brillaba en el cielo nocturno.", "estrella"),
"estrella_fama": ("La estrella del cine llegó a la alfombra roja.", "estrella"),
}
vectores = []
labels = []
for etiqueta, (frase, palabra) in frases.items():
vectores.append(embedding_de_palabra(frase, palabra).numpy())
labels.append(etiqueta)
pca = PCA(n_components=2, random_state=42)
vectores_2d = pca.fit_transform(vectores)
plt.figure(figsize=(10, 6))
for i, etiqueta in enumerate(labels):
x, y = vectores_2d[i]
plt.scatter(x, y, s=90)
plt.text(x + 0.01, y + 0.01, etiqueta, fontsize=9)
plt.axhline(0, color="gray", linewidth=0.5)
plt.axvline(0, color="gray", linewidth=0.5)
plt.title("Embeddings contextuales de palabras ambiguas (PCA 2D)")
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
plt.grid(alpha=0.25)
plt.show()
Al usar BERT preentrenado como extractor de features, no estamos entrenando la red. Por eso desactivamos los gradientes: ganamos velocidad y eficiencia en inferencia.
Objetivo del gráfico¶
Visualizar si la representación contextual de una misma palabra cambia cuando cambia su sentido.
Cómo interpretar la figura¶
- PCA 1 y PCA 2 son una proyección de embeddings de 768 dimensiones a 2D. Sirven para visualización, no como prueba estadística formal.
- Cada punto representa el embedding contextual de la palabra ambigua dentro de una oración.
- Si dos usos de una palabra aparecen separados, eso sugiere que el contexto modificó su representación.
Precaución metodológica¶
Una separación visual en PCA no prueba por sí sola que el modelo “entienda” el significado como una persona. Es evidencia útil de que el embedding cambia con el contexto. Para un análisis más riguroso conviene comparar similitudes coseno, usar más ejemplos y evaluar en una tarea downstream.
Ejercicio práctico¶
from pathlib import Path
import pandas as pd
DATA_DIR = Path("data")
if not ((DATA_DIR / "Political_tweets.csv").exists() or (DATA_DIR / "global_political_tweets.zip").exists()):
DATA_DIR = Path("runs/2026-1-Pregrado/overrides/labs/Modulo 4 Modelos Generativos/data")
csv_path = DATA_DIR / "Political_tweets.csv"
zip_path = DATA_DIR / "global_political_tweets.zip"
if csv_path.exists():
df = pd.read_csv(csv_path, sep=",", encoding="utf-8", low_memory=False)
elif zip_path.exists():
df = pd.read_csv(zip_path, sep=",", encoding="utf-8", low_memory=False, compression="zip")
else:
raise FileNotFoundError("No se encontró Political_tweets.csv ni global_political_tweets.zip")
df = df[df["text"].notna()].sample(n=min(80, len(df)), random_state=42).reset_index(drop=True)
print(f"Filas usadas en la demo: {len(df)}")
df[["date", "text"]].head()
import torch
from transformers import pipeline
device_id = 0 if torch.cuda.is_available() else -1
# El CSV de Political_tweets incluido aquí está mayoritariamente en inglés.
# Para mantener rigor, usamos un clasificador zero-shot RoBERTa-MNLI sobre etiquetas de sentimiento en inglés.
# Si quieres una inferencia más rápida y específica para Twitter, puedes reemplazarlo por un modelo fine-tuneado de sentimiento en inglés.
zero_shot = pipeline(
"zero-shot-classification",
model="roberta-large-mnli",
tokenizer="roberta-large-mnli",
device=device_id,
)
candidate_labels = ["negative", "neutral", "positive"]
hypothesis_template = "This text expresses a {} sentiment."
resultados = zero_shot(
df["text"].astype(str).tolist(),
candidate_labels=candidate_labels,
hypothesis_template=hypothesis_template,
multi_label=False,
batch_size=8,
truncation=True,
)
label_map = {"negative": "NEG", "neutral": "NEU", "positive": "POS"}
df["prediccion"] = [label_map[r["labels"][0]] for r in resultados]
df["confianza"] = [r["scores"][0] for r in resultados]
df[["text", "prediccion", "confianza"]].head()
El corpus
Political_tweets.csvestá mayoritariamente en inglés. Por eso no corresponde aplicar directamente un modelo entrenado solo para español, como RoBERTuito, sobre estos textos.En esta demo se usa
roberta-large-mnlien modo zero-shot classification: el modelo evalúa qué hipótesis de sentimiento es más compatible con cada tweet.Esto es más lento y menos específico que un modelo fine-tuneado de sentimiento, pero es metodológicamente más consistente que usar un clasificador en el idioma equivocado.
df[["text", "prediccion", "confianza"]].head(10)
import matplotlib.pyplot as plt
conteo = df["prediccion"].value_counts().reindex(["NEG", "NEU", "POS"]).fillna(0)
plt.figure(figsize=(6, 4))
plt.bar(conteo.index, conteo.values, color=["#c44e52", "#8172b2", "#55a868"])
plt.title("Distribución de sentimientos predichos")
plt.xlabel("Sentimiento")
plt.ylabel("Cantidad de textos")
plt.grid(axis="y", alpha=0.25)
plt.show()
from wordcloud import WordCloud
for clase in ["NEG", "NEU", "POS"]:
textos_clase = " ".join(df.loc[df["prediccion"] == clase, "text"].astype(str))
if not textos_clase.strip():
print(f"Sin textos para la clase {clase}")
continue
wc = WordCloud(width=800, height=300, background_color="white", collocations=False).generate(textos_clase)
plt.figure(figsize=(10, 4))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.title(f"Nube de palabras - {clase}")
plt.show()
Un poco de preprocesamiento de texto para el análisis de sentimiento.¶
for clase in df["prediccion"].unique():
print(f"\nEjemplos de clase {clase}:")
print(df[df["prediccion"] == clase]["text"].head(3).to_string(index=False))
import re
# Limpieza para visualización exploratoria. No se re-clasifica automáticamente el texto limpio,
# porque cambiar la entrada también cambia el problema que el clasificador está resolviendo.
def limpiar_texto(texto):
texto = str(texto).lower()
texto = re.sub(r"http\S+|www\S+", "", texto)
texto = re.sub(r"\@\w+", "", texto)
texto = re.sub(r"#", "", texto) # conserva la palabra del hashtag
texto = re.sub(r"[^\w\sáéíóúñü]", "", texto)
texto = re.sub(r"\bamp\b", "", texto)
texto = re.sub(r"\d+", "", texto)
texto = re.sub(r"\s+", " ", texto).strip()
return texto
df["texto_limpio"] = df["text"].apply(limpiar_texto)
df[["text", "texto_limpio", "prediccion"]].head()
for clase in ["NEG", "NEU", "POS"]:
textos_clase = " ".join(df.loc[df["prediccion"] == clase, "texto_limpio"].astype(str))
if not textos_clase.strip():
print(f"Sin textos limpios para la clase {clase}")
continue
wc = WordCloud(width=800, height=300, background_color="white", collocations=False).generate(textos_clase)
plt.figure(figsize=(10, 4))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.title(f"Nube de palabras texto limpio - {clase}")
plt.show()
# !pip install bertopic
# !pip install umap-learn
Estimar tópicos con BERTopic¶
import os
os.environ["USE_TF"] = "0"
os.environ["TRANSFORMERS_NO_TF"] = "1"
os.environ["TOKENIZERS_PARALLELISM"] = "false"
corpus = df["texto_limpio"].dropna().astype(str)
corpus = corpus[corpus.str.len() > 20].tolist()
topicos_disponibles = False
modelo_bertopic = None
try:
from bertopic import BERTopic
from sentence_transformers import SentenceTransformer
embedding_model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
embeddings = embedding_model.encode(corpus, show_progress_bar=True, batch_size=32)
modelo_bertopic = BERTopic(
embedding_model=embedding_model,
language="english",
min_topic_size=5,
verbose=False,
)
topics, probs = modelo_bertopic.fit_transform(corpus, embeddings)
df_topics = df.loc[df["texto_limpio"].str.len() > 20].copy().reset_index(drop=True)
df_topics["topico"] = topics
topicos_disponibles = True
print(f"BERTopic ajustado sobre {len(corpus)} documentos.")
except Exception as exc:
print("BERTopic no pudo ejecutarse en este entorno.")
print(f"Detalle: {type(exc).__name__}: {exc}")
Ver resumen de tópicos¶
if topicos_disponibles:
display(modelo_bertopic.get_topic_info().head(10))
else:
print("No hay modelo BERTopic ajustado para mostrar resumen.")
Esto te muestra:
Topic: número del tópico (-1es ruido)
Count: número de documentos asignados a ese tópico
Name: resumen de palabras clave por tópico
Ver palabras clave de un tópico específico¶
if topicos_disponibles:
info_topicos = modelo_bertopic.get_topic_info()
topicos_validos = [t for t in info_topicos["Topic"].tolist() if t != -1]
topico_ejemplo = topicos_validos[0] if topicos_validos else -1
print(f"Tópico seleccionado: {topico_ejemplo}")
display(modelo_bertopic.get_topic(topico_ejemplo))
else:
print("No hay tópicos disponibles. Ejecuta primero la celda de BERTopic.")
Visualizar los tópicos¶
if topicos_disponibles:
fig_barras = modelo_bertopic.visualize_barchart(top_n_topics=10)
fig_mapa = modelo_bertopic.visualize_topics()
fig_barras.show()
fig_mapa.show()
else:
print("No hay visualizaciones porque BERTopic no está ajustado.")
Estas visualizaciones permiten:
Ver los temas más frecuentes y sus palabras representativas.
Explorar relaciones entre tópicos.
Bonus: Visualizar ejemplos por tópico¶
if topicos_disponibles:
for topico in sorted(df_topics["topico"].unique()):
if topico == -1:
continue
print(f"\nEjemplos del tópico {topico}:")
print(df_topics.loc[df_topics["topico"] == topico, "texto_limpio"].head(3).to_string(index=False))
else:
print("No hay ejemplos por tópico porque BERTopic no está ajustado.")
¿Qué puedes hacer después?¶
- Combinar predicción de sentimiento + tópico: ¿qué tópicos son más positivos o negativos?
- Visualizar nubes de palabras por tópico.
- Aplicar a clusters dinámicos (por fecha, región, etc.)
DeBERTa V3¶
1. ¿Qué es DeBERTa V3?¶
DeBERTa = Decoding-enhanced BERT with disentangled attention
Es una evolución avanzada del modelo BERT creada por Microsoft Research. La versión V3 incorpora mejoras en la arquitectura, el preentrenamiento y la eficiencia del aprendizaje.
Objetivo: entender mejor el lenguaje con menos errores, menos datos y mayor precisión.
2. ¿Cómo se construye la entrada en BERT?¶
Recordemos que BERT combina 3 embeddings:
plaintext
InputEmbedding = TokenEmbedding + SegmentEmbedding + PositionalEmbeddingPero BERT mezcla la posición y el contenido en la misma representación.
3. ¿Qué mejora DeBERTa?¶
a. Atención desentrelazada (Disentangled Attention)¶
En BERT la atención mezcla contenido y posición en la misma representación; en DeBERTa se separan explícitamente señales de contenido y posición.
Esto permite que DeBERTa:
Entienda mejor las relaciones semánticas entre tokens.
Aprenda estructuras sintácticas más precisas.
b. Preentrenamiento tipo ELECTRA (RTD en vez de MLM)¶
En lugar de ocultar palabras como BERT (Masked Language Modeling), DeBERTa V3 usa Replaced Token Detection:
- Un "generador" reemplaza palabras.
- Un "discriminador" predice si un token es original o falso.
Es más eficiente y aprende mejor con menos pasos.
c. Positional Encoding mejorado¶
- Usa sinusoidales + codificación relativa.
- Esto permite entender distancias entre palabras, no solo su posición absoluta.
d. Gradient Disentangled Sharing¶
- Mejora la manera en que se entrenan juntas las partes generadora y discriminadora.
- Evita interferencias entre sus gradientes.
4. Resultados¶
| Benchmark | BERT Base | DeBERTa V3 Large |
|---|---|---|
| GLUE | ~80 | 91.4 |
| SuperGLUE | ~68 | 91.3 |
| SQuAD 2.0 (F1) | ~88.5 | 96.8 |
En varios benchmarks reportados, supera a modelos fuertes como RoBERTa y ELECTRA bajo configuraciones comparables.
5. ¿Dónde se usa?¶
- Análisis de sentimientos
- QA (preguntas y respuestas)
- Clasificación de texto
- Reconocimiento de entidades (NER)
- Tareas multilingües (con mDeBERTa)
6. ¿Por qué importa?¶
- Muestra cómo pequeñas decisiones arquitectónicas pueden tener gran impacto.
- Es una prueba de que no basta con “más datos”, sino con mejor diseño.
7. En resumen¶
| Característica | DeBERTa V3 |
|---|---|
| Base | Encoder como BERT |
| Atención | Desentrelazada (posición + contenido separados) |
| Preentrenamiento | Replaced Token Detection (RTD) |
| Positional Encoding | Relativa + sinusoidal |
| SOTA en tareas NLU | Sí |
Recursos para profundizar¶
Repositorio oficial: GitHub - Microsoft DeBERTa
Modelos preentrenados: Hugging Face - DeBERTa V3
Artículo académico: DeBERTa V3 en arXiv