Transformers - GPT¶
Modelos de Machine Learning No-Supervisados¶
Dr. Cristian Candia¶
Universidad del Desarrollo (UDD), Chile¶
- Director, Computational Research in Social Sciences Lab
- Faculty, Data Science Institute, School of Engineering
Northwestern University, United States¶
- External Faculty, Northwestern Institute on Complex Systems (NICO), Kellogg School of Management
Founder & CSTO¶
- Capybara. Capybara ayuda a establecimiento educacionales a detectar señales tempranas de bullying, medir convivencia escolar y tomar decisiones basadas en evidencia para prevenir conflictos a tiempo.
GPT: Generative Pretrained Transformers¶



GPT, 2018: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
GPT-3, 2020: https://arxiv.org/pdf/2005.14165
GPT-4 Technical Report, 2023: https://arxiv.org/abs/2303.08774
De GPT-1 a GPT-4: modelos autoregresivos a gran escala¶
1. ¿Qué es un modelo GPT?¶
Los GPT (Generative Pretrained Transformers) son modelos de lenguaje autoregresivos. Entrenan la probabilidad del siguiente token dado el contexto anterior:
$$ P(x_t \mid x_{1:t-1}) $$La arquitectura base es Transformer decoder-only con atención causal: cada posición puede atender a tokens anteriores, pero no a tokens futuros.
2. Arquitectura base: Transformer decoder¶
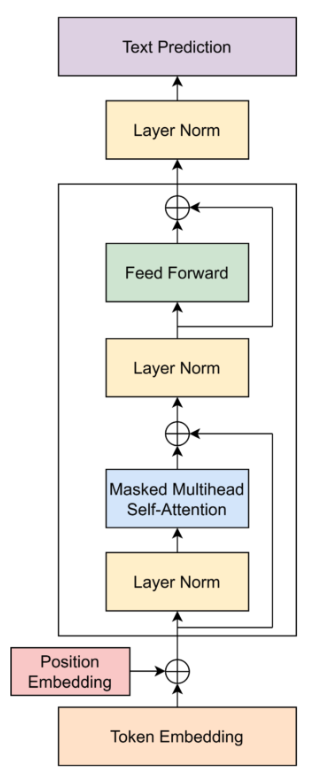
Cada bloque incluye:
- self-attention causal multi-cabeza;
- normalización y conexiones residuales;
- red feed-forward por posición;
- una máscara triangular que impide mirar tokens futuros.
3. Evolución histórica¶
| Modelo | Año | Parámetros publicados | Contexto reportado | Aporte principal |
|---|---|---|---|---|
| GPT-1 | 2018 | 117M | 512 tokens | Preentrenamiento generativo + fine-tuning. |
| GPT-2 | 2019 | hasta 1.5B | 1024 tokens | Escalamiento y generación más coherente. |
| GPT-3 | 2020 | 175B | 2048 tokens | Few-shot e in-context learning emergente. |
| InstructGPT / ChatGPT | 2022 | no siempre público | variable | Post-entrenamiento para seguir instrucciones y preferencias humanas. |
| GPT-4 | 2023 | no público | variantes con contexto extendido | Mejor desempeño en razonamiento, robustez y multimodalidad reportada. |
Los límites de contexto, capacidades multimodales y nombres comerciales cambian por producto y versión. En una clase conviene separar la idea arquitectónica estable de los detalles de API vigentes.
4. GPT-4 en el Technical Report¶
GPT-4 se presenta como un modelo autoregresivo de gran escala con post-entrenamiento orientado a utilidad, seguridad y robustez. El reporte no publica arquitectura, tamaño ni datos exactos, por lo que no corresponde asumir esos detalles.
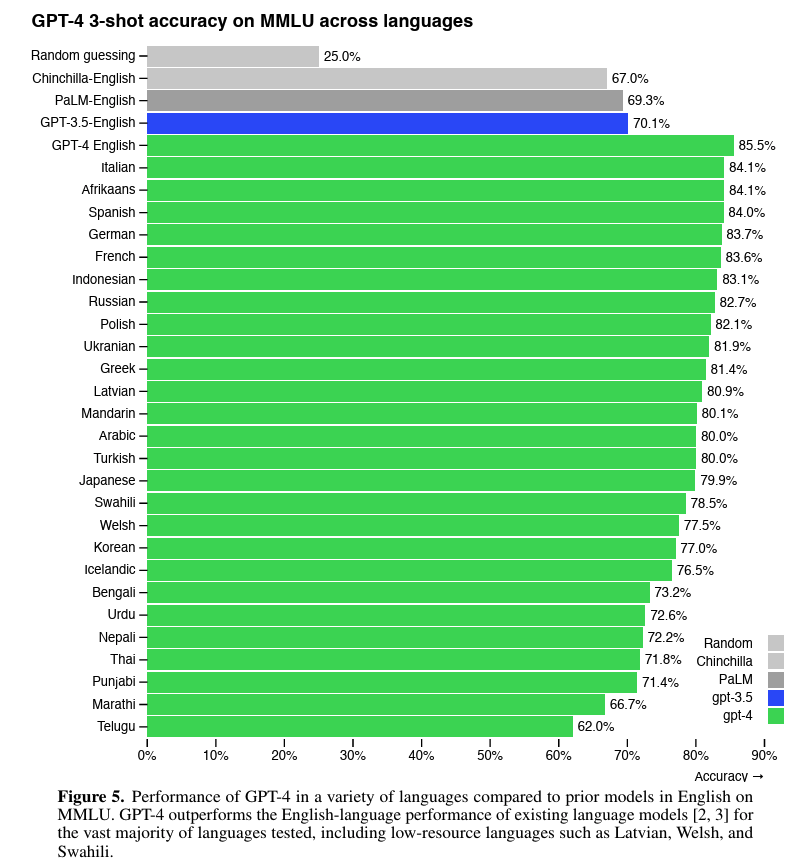
5. Benchmarks: ¿realmente mejora?¶
En el reporte técnico, GPT-4 supera a GPT-3.5 en múltiples evaluaciones académicas y profesionales. Por ejemplo, en MMLU se reporta una mejora amplia frente a GPT-3.5.
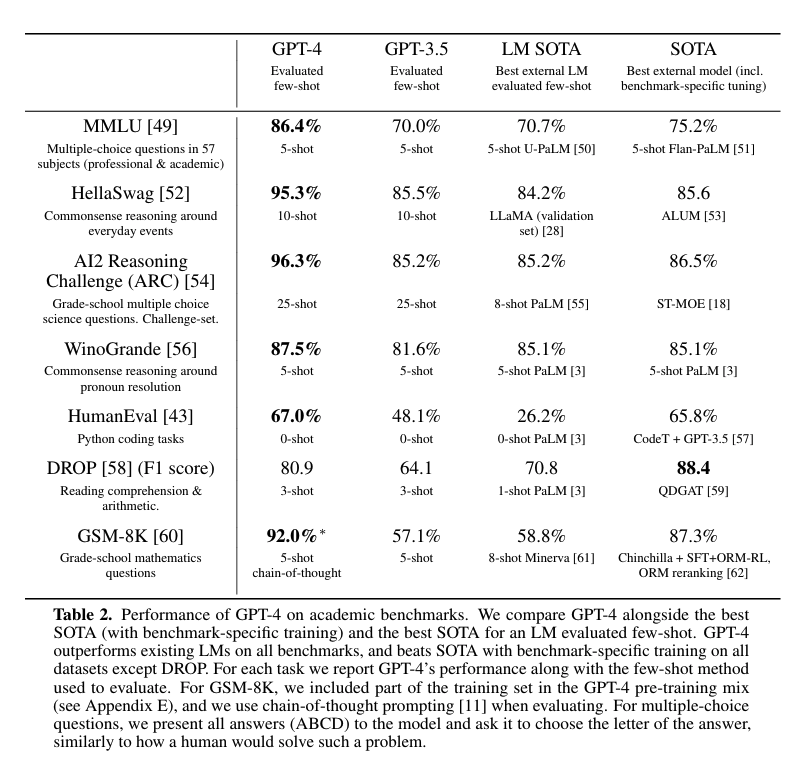
6. Escalamiento predecible¶
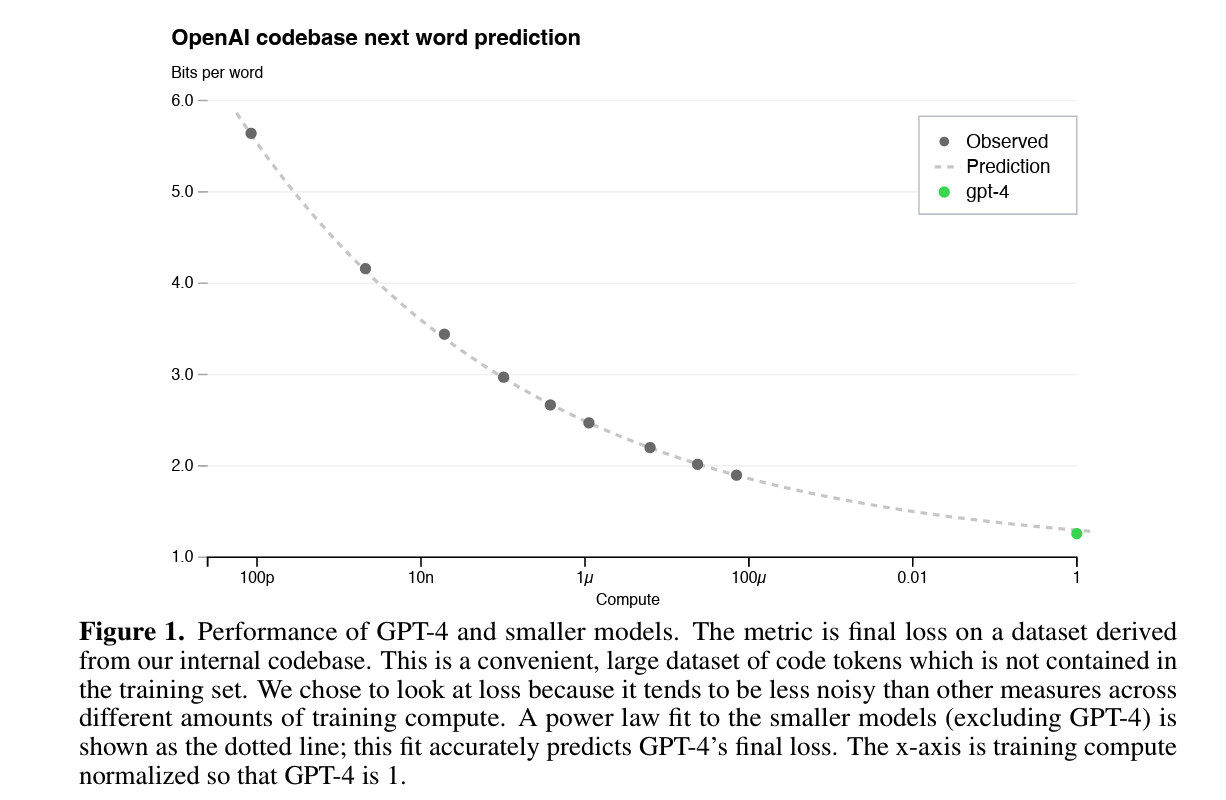
El reporte de GPT-4 describe predicciones de pérdida usando leyes de potencia sobre modelos más pequeños:
$$ L(C) = a C^b + c $$donde $C$ representa cómputo de entrenamiento y $L(C)$ la pérdida esperada. La idea central es que, bajo ciertas condiciones, el desempeño de modelos grandes puede estimarse a partir de corridas más pequeñas.
7. Seguridad, factualidad y alineación¶
GPT-4 fue evaluado con red-teaming, pruebas de factualidad y prompts adversariales. Aun así, el propio reporte enfatiza limitaciones: puede cometer errores, inventar información plausible y reflejar sesgos de datos o de post-entrenamiento.

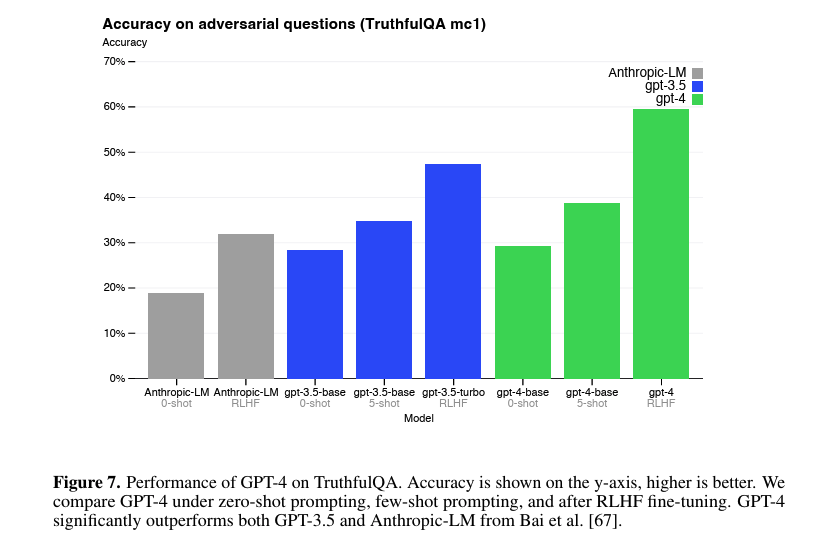
8. Limitaciones¶
- Alucinaciones: puede producir afirmaciones falsas con alta confianza.
- Sesgos: puede reflejar sesgos de datos, usuarios o procesos de alineación.
- No aprende online durante inferencia: responder a un prompt no actualiza sus pesos.
- Dependencia del contexto: la respuesta depende del prompt, instrucciones de sistema, historial y herramientas disponibles.
- Detalles no públicos: para GPT-4 no se conocen tamaño, arquitectura exacta ni corpus de entrenamiento.
9. ¿Por qué importa?¶
GPT ilustra cómo una tarea simple, predecir el siguiente token, puede escalar hacia capacidades de generación, traducción, programación, razonamiento aproximado e interacción en lenguaje natural cuando se combina con suficiente escala y post-entrenamiento.
import os
os.environ["USE_TF"] = "0"
os.environ["TRANSFORMERS_NO_TF"] = "1"
os.environ["TOKENIZERS_PARALLELISM"] = "false"
import torch
import matplotlib.pyplot as plt
from transformers import AutoTokenizer, AutoModelForCausalLM
from torch.nn.functional import softmax
SEED = 42
torch.manual_seed(SEED)
device = torch.device("cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
print(f"Device: {device}")
# Cargamos GPT-2 porque sus pesos son públicos y es suficiente para ilustrar autoregresión.
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
model.eval()
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
input_text = "In a future where artificial intelligence dominates"
inputs = tokenizer(input_text, return_tensors="pt").to(device)
torch.manual_seed(SEED)
output_ids = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
top_k=50,
temperature=0.9,
pad_token_id=tokenizer.eos_token_id,
)
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print("Texto generado:\n")
print(output_text)
Este ejemplo muestra el funcionamiento clásico del modelo autoregresivo: dado un prompt en inglés, predice token por token usando su entrenamiento previo. No tiene acceso a una "idea general", solo a probabilidades de ocurrencia de palabras dentro de secuencias de entrenamiento similares.
input_text = "In a future where artificial intelligence dominates"
inputs = tokenizer(input_text, return_tensors="pt").to(device)
with torch.no_grad():
logits = model(**inputs).logits
logits_ultimo_token = logits[0, -1, :]
probs = softmax(logits_ultimo_token, dim=0)
topk = torch.topk(probs, k=15)
indices_top = topk.indices.tolist()
probs_top = topk.values.detach().cpu().tolist()
tokens_top = [tokenizer.decode([idx]).replace("\n", "\\n") for idx in indices_top]
plt.figure(figsize=(10, 5))
plt.barh(tokens_top[::-1], probs_top[::-1], color="#4c72b0")
plt.title("Distribución de probabilidad: siguiente token tras el prompt")
plt.xlabel("Probabilidad")
plt.ylabel("Token candidato")
plt.grid(axis="x", alpha=0.25)
plt.show()
contexto = "artificial intelligence is"
inputs_contexto = tokenizer(contexto, return_tensors="pt").to(device)
with torch.no_grad():
logits = model(**inputs_contexto).logits
ultimos_logits = logits[0, -1, :]
probs = softmax(ultimos_logits, dim=0)
topk = torch.topk(probs, k=10)
indices_top = topk.indices.tolist()
probs_top = topk.values.detach().cpu().tolist()
tokens_top = [tokenizer.decode([idx]).replace("\n", "\\n") for idx in indices_top]
plt.figure(figsize=(10, 4))
plt.barh(tokens_top[::-1], probs_top[::-1], color="#55a868")
plt.title("Top-10 tokens predichos por GPT-2")
plt.xlabel("Probabilidad")
plt.ylabel("Token")
plt.grid(axis="x", alpha=0.25)
plt.show()
En modelos autoregresivos como GPT, la distribución de probabilidad para el siguiente token depende únicamente del contexto previo. Si ese contexto no cambia, la distribución es determinística y estable.¶
Entonces ¿Por qué ChatGPT (basado en GPT-3.5 o GPT-4) da respuestas distintas con el mismo prompt?¶
La razón es simple:
ChatGPT tiene activado el sampling.
1. Sampling = aleatoriedad controlada¶
ChatGPT, por defecto, genera texto usando:
do_sample=Truetemperature=~0.7–1.0top_p=0.9otop_k=50
Eso significa que no elige siempre el token más probable, sino que muestrea de la distribución $P(x_t \mid x_{1:t-1})$, lo que introduce diversidad en las respuestas.
2. ChatGPT = modelo + sistema de producto¶
Además, ChatGPT no es solo el modelo:
| Componente | Ejemplo |
|---|---|
| Modelo base | GPT-3.5 / GPT-4 |
| Sampling activado | Controla diversidad |
| Prompt implícito | "You are a helpful assistant..." |
| Historial de conversación | Condiciona respuesta cuando está dentro del contexto |
| Herramientas externas | Pueden incorporarse según el producto y la configuración |
Aunque repitas tu parte del prompt, el contexto total puede incluir instrucciones de sistema, historial, herramientas o parámetros de muestreo.
3. ¿Qué pasa en tu notebook?¶
Cuando usas model(...) sin generate(), o usas generate() con do_sample=False, estás en modo greedy:
- Siempre elige el token más probable
- Resultado = determinista
- Es útil para análisis teóricos, no para creatividad
En resumen:¶
| Situación | ¿Mismo prompt → misma salida? | ¿Por qué? |
|---|---|---|
generate(..., do_sample=False) |
✅ Sí | Determinismo puro (modo greedy) |
generate(..., do_sample=True) |
❌ No | Sampling activo |
| ChatGPT | ❌ No | Sampling + temperatura + contexto |
torch.manual_seed(SEED + 1)
output_ids = model.generate(
**inputs,
max_new_tokens=120,
do_sample=True,
top_k=50,
temperature=0.9,
pad_token_id=tokenizer.eos_token_id,
)
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print("Texto generado:\n")
print(output_text)
Arquitectura decoder-only¶
- Multi-head causal self-attention con máscara triangular.
- Feed-forward network por posición.
- Normalización y conexiones residuales.
- No hay encoder: el modelo genera autoregresivamente de izquierda a derecha.
Comparación GPT vs BERT¶
| Aspecto | BERT | GPT |
|---|---|---|
| Dirección de atención | Bidireccional durante MLM | Causal / unidireccional |
| Uso típico | Comprensión y representación | Generación y completado |
| Arquitectura base | Encoder Transformer | Decoder Transformer |
| Preentrenamiento | Masked Language Modeling | Autoregressive Language Modeling |
| Adaptación | Fine-tuning por tarea | Prompting, fine-tuning, instruction tuning y post-entrenamiento |
¿Qué hace especial a GPT-4 en el reporte técnico?¶
El reporte no publica tamaño, datos ni arquitectura exacta. Lo que sí documenta es:
- evaluación fuerte en tareas académicas y profesionales;
- capacidades multilingües y multimodales reportadas;
- contexto extendido en variantes del sistema;
- red teaming y post-entrenamiento orientado a alineación y seguridad.
La lección técnica estable no es un número específico de tokens o parámetros, sino el efecto de escalar modelos autoregresivos y post-entrenarlos para interacción útil.
Técnicas modernas en modelos GPT: Prompt Engineering, In-Context Learning y Chain-of-Thought¶
A medida que los modelos como GPT-3.5 y GPT-4 se vuelven más potentes, también cambia la forma en que los usamos. Ya no es necesario reentrenar el modelo para cada tarea: basta con diseñar el prompt adecuado. A esto se le llama aprendizaje en contexto o in-context learning, y se potencia con estrategias como prompt engineering y chain-of-thought.
🔹 Prompt Engineering¶
Prompt Engineering es el arte de diseñar cuidadosamente la entrada al modelo (el "prompt") para inducir el comportamiento deseado, sin necesidad de fine-tuning.
Ejemplo:
Traduce al inglés: El conocimiento es poder.Este tipo de instrucción textual funciona porque los modelos han sido expuestos masivamente a tareas similares durante el preentrenamiento.
prompt = "Translate to English: El conocimiento es poder."
inputs_prompt = tokenizer(prompt, return_tensors="pt").to(device)
output_ids = model.generate(
**inputs_prompt,
max_new_tokens=30,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
)
print("Traducción inducida por prompt:\n")
print(tokenizer.decode(output_ids[0], skip_special_tokens=True))
GPT-2 no interpretó el prompt como instrucción y tendió a repetir la frase o partes de ella.¶
¿Por qué falló?¶
GPT-2 fue entrenado como modelo de completado de texto, sin instruction tuning ni RLHF, a diferencia de los modelos conversacionales modernos. No entiende bien prompts tipo:
“Traduce al inglés: ...”
porque en su entrenamiento no vio suficientes ejemplos de este estilo como para “aprender a obedecer”.
- GPT-2 no es un modelo instructivo: no fue entrenado con instruct tuning ni RLHF.
Prompt Engineering solo funciona bien en modelos que entienden instrucciones, como:
- modelos instructivos y conversacionales modernos;
- modelos abiertos con sufijo instruct o chat;
- modelos encoder-decoder entrenados explícitamente para seguir instrucciones, como FLAN-T5.
- Lo que ves aquí es completado textual, no interpretación de intención.
Chain-of-Thought (CoT)¶
Chain-of-Thought es una técnica que induce al modelo a razonar paso a paso. Consiste en incluir frases como "Pensemos paso a paso" o mostrar ejemplos con razonamientos intermedios.
Ejemplo:
Pregunta: Si tengo 3 manzanas y luego compro 2 más, ¿cuántas tengo en total?
Pensamiento: Primero tengo 3 manzanas. Luego compro 2 más. En total tengo 5 manzanas.
Respuesta: 5Esta técnica mejora notablemente el rendimiento en tareas complejas de razonamiento, aritmética y lógica simbólica, especialmente en modelos grandes (GPT-3.5+ y GPT-4).
prompt = "Question: If I have 3 apples and then buy 2 more, how many apples do I have?\nReasoning:"
inputs_cot = tokenizer(prompt, return_tensors="pt").to(device)
torch.manual_seed(SEED + 2)
output_ids = model.generate(
**inputs_cot,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.eos_token_id,
)
print("Chain-of-Thought prompt con GPT-2:\n")
print(tokenizer.decode(output_ids[0], skip_special_tokens=True))
Esto es un ejemplo de cómo GPT-2 no es capaz de realizar Chain-of-Thought (CoT) de forma efectiva. Vamos a desglosarlo:
¿Qué pasó?¶
Tu prompt era:
Question: If I have 3 apples and then buy 2 more, how many apples do I have?
Reasoning:
Y GPT-2 puede generar una continuación gramatical, pero no hay garantía de que siga una cadena de razonamiento correcta:
Pensamiento: salida anterior...
¿Por qué falla GPT-2 aquí?¶
- GPT-2 no fue post-entrenado para obedecer prompts estructurados ni para resolver tareas con razonamiento explícito.
- GPT-2 solo ve texto plano, sin "intenciones" explícitas.
- No ha sido expuesto a ejemplos tipo “Pensamiento: ... Respuesta: ...” como lo fueron GPT-3.5+ y GPT-4.
- El modelo tiene capacidad limitada de razonamiento multistep.
Lección clave:¶
Chain-of-Thought necesita modelos grandes y entrenados con ejemplos de razonamiento paso a paso. GPT-2 principalmente completa texto a partir del patrón local del prompt, incluso si la forma del prompt parece lógica.
¿Cómo simular algo funcional con GPT-2?¶
Una opción es usar few-shot prompting manual con ejemplos previos:
prompt = (
"Pregunta: Si tengo 1 manzana y compro 1 más, ¿cuántas tengo?\n"
"Pensamiento: 1 + 1 = 2. Respuesta: 2\n\n"
"Pregunta: Si tengo 3 manzanas y luego compro 2 más, ¿cuántas tengo en total?\n"
"Pensamiento:"
)
Este tipo de prompting puede ligeramente mejorar la coherencia porque le estás dando un patrón semántico aprendido, aunque sigue siendo limitado en GPT-2.
Notas¶
Este ejemplo muestra que no basta con un buen prompt: la capacidad del modelo y su entrenamiento son críticos. Lo que GPT-4 logra con mayor facilidad (razonamiento paso a paso), GPT-2 no fue entrenado ni escalado para aprenderlo de forma robusta.
In-Context Learning (ICL)¶
Aunque GPT-2 no fue entrenado para seguir instrucciones explícitas, sí puede aprender a imitar patrones de texto dentro del prompt.
Esto se conoce como In-Context Learning, y consiste en mostrar ejemplos previos directamente en la entrada.
El modelo no ajusta sus pesos, solo generaliza en función del texto de entrada.
Ejemplo: preguntamos por la capital de países tras mostrar un par de ejemplos.
def generar(prompt, model, tokenizer, max_tokens=20, temperatura=0.7, sample=True):
inputs_local = tokenizer(prompt, return_tensors="pt").to(device)
generation_kwargs = {
"max_new_tokens": max_tokens,
"do_sample": sample,
"pad_token_id": tokenizer.eos_token_id,
}
if sample:
generation_kwargs["temperature"] = temperatura
output_ids = model.generate(**inputs_local, **generation_kwargs)
return tokenizer.decode(output_ids[0], skip_special_tokens=True)
prompt_icl = """Question: What is the capital of France?
Answer: Paris
Question: What is the capital of Italy?
Answer: Rome
Question: What is the capital of Germany?
Answer:"""
respuesta = generar(prompt_icl, model, tokenizer, max_tokens=15, sample=False)
print("Resultado con In-Context Learning:\n")
print(respuesta)
¿Qué aprendemos de este comportamiento?¶
GPT-2 puede imitar el formato del prompt (Question / Answer) y a veces completar hechos frecuentes correctamente. Eso no significa que haya aprendido una regla general confiable dentro del contexto.
Lectura rigurosa¶
- Si responde correctamente, puede deberse a conocimiento memorizado durante preentrenamiento o a completado de patrón.
- Si falla, muestra una limitación esperable de un modelo pequeño, no instructivo y sensible al idioma/formato del prompt.
- El in-context learning robusto aparece con mucha más fuerza en modelos más grandes y post-entrenados.
Qué probar¶
- Agregar más ejemplos correctos.
- Usar el idioma dominante del modelo base (inglés para GPT-2).
- Comparar
do_sample=Falsecontra muestreo con temperatura. - Probar un modelo instructivo y comparar el cambio de comportamiento.
Reflexión final¶
GPT se basa en una idea simple y potente: predecir el siguiente token con atención causal.
Al escalar datos, cómputo y post-entrenamiento, esa base permite generación de texto, aprendizaje en contexto y uso conversacional.
La comparación con BERT muestra una diferencia central: BERT representa y comprende secuencias con atención bidireccional; GPT genera secuencias de forma autoregresiva.
Nota práctica¶
- En GPT-2 estas técnicas funcionan de forma limitada porque el modelo fue entrenado para completar texto, no para obedecer instrucciones.
- En modelos instructivos modernos, prompt engineering e in-context learning son herramientas mucho más efectivas.
- Chain-of-thought puede mejorar tareas de razonamiento en modelos grandes, pero no garantiza factualidad ni corrección; siempre debe evaluarse contra criterios externos.