Reducción de Dimensionalidad: PCA¶
Modelos de Machine Learning No-Supervisados¶
📌 Dr. Cristian Candia¶
🎓 Universidad del Desarrollo (UDD), Chile¶
- 🏢 Director, Computational Research in Social Sciences Lab
- 🔬 Faculty, Data Science Institute, School of Engineering
🎓 Northwestern University, United States¶
- 🔬 External Faculty, Northwestern Institute on Complex Systems (NICO), Kellogg School of Management
🚀 Founder¶
- 🦫 Capybara
La mayoría de los métodos de aprendizaje automático pertenecen al aprendizaje supervisado, donde el objetivo es predecir una variable de respuesta $ Y $ a partir de un conjunto de características $( X_1, X_2, \dots, X_p )$ observadas en $ n $ instancias. Matemáticamente, se define como:
$Y = f(X_1, X_2, \dots, X_p) + \epsilon$
donde:
- $ f $ es una función desconocida que relaciona las características $ X_i $ con la respuesta $ Y $.
- $ \epsilon $ representa el ruido o error aleatorio, es decir, la variabilidad en $ Y $ que no puede explicarse por $ f(X) $.
Sin embargo, en aprendizaje no supervisado, no disponemos de la variable respuesta $ Y $, por lo que el objetivo cambia. Ahora, buscamos descubrir estructuras o patrones en los datos $ X_1, X_2, \dots, X_p $ sin un criterio explícito de predicción.
$X = \{X_{i,j}\} \quad \text{con } i = 1, \dots, n \text{ (observaciones), } j = 1, \dots, p \text{ (características)}$
o, de manera más compacta:
$X \in \mathbb{R}^{n \times p}$
donde:
- $ n $ es el número de observaciones (filas de la matriz).
- $ p $ es el número de características (columnas de la matriz).
Preguntas clave en aprendizaje no supervisado:¶
- ¿Existe una forma óptima de visualizar los datos en un espacio de menor dimensión?
- ¿Podemos identificar subgrupos dentro de las observaciones o entre las variables?
- ¿Podemos reducir la complejidad de los datos preservando su estructura más relevante?
- ¿Existen puntos de datos que no siguen el comportamiento general del conjunto?
El aprendizaje no supervisado abarca un conjunto diverso de técnicas para resolver estos problemas.
Análisis de Componentes Principales (PCA) — Fundamentos¶
Objetivo¶
El Análisis de Componentes Principales (PCA, por sus siglas en inglés) es una técnica de reducción de dimensionalidad que transforma los datos en un nuevo sistema de coordenadas, preservando la mayor cantidad posible de variabilidad en los datos originales. En otras palabras, su objetivo es encontrar una representación de menor dimensión de los datos que capture la máxima varianza posible, mediante combinaciones lineales ortogonales de las variables originales.
Definición:¶
Matemáticamente, dados los datos centrados $ X $, buscamos una transformación lineal $ Z $ tal que:
$Z = XW$
donde:
- $ Z $ representa los datos transformados en el nuevo espacio de componentes principales.
- $ W $ es la matriz de componentes principales, cuyas columnas son los autovectores de la matriz de covarianza de $ X $.
Conceptos clave en PCA:¶
- Reducción de dimensionalidad: El proceso de representar datos en un espacio de menor dimensión mientras se conserva la mayor cantidad posible de información.
- Autovectores y autovalores: Los autovectores de la matriz de covarianza indican las direcciones principales de variabilidad en los datos, mientras que los autovalores indican la magnitud de esa variabilidad.
- Proporción de varianza explicada: La cantidad de información conservada en cada componente principal.
Intuición¶
PCA puede entenderse como una técnica que reorganiza el espacio de las variables originales para eliminar redundancias debidas a la correlación entre variables.
PCA busca una nueva base de menor dimensión que represente de manera eficiente la información contenida en un conjunto de datos. En lugar de describir los datos con las variables originales $ X_1, \ldots, X_p $, lo haremos con nuevas variables no correlacionadas $ Z_1, \ldots, Z_M $ (con $ M < p $) que son combinaciones lineales de las anteriores y que maximizan la varianza.
¿Por qué importa la correlación?¶
Cuando dos variables están altamente correlacionadas (positiva o negativamente), en realidad están midiendo parcialmente lo mismo. Esto significa que hay una redundancia en la información: no necesitas ambas para entender la estructura del fenómeno.
Ejemplo sencillo:
- Supón que tienes dos variables:
- $ X_1 = \text{Estatura} $
- $ X_2 = \text{Longitud de pierna} $
Estas variables estarán fuertemente correlacionadas (personas más altas tienden a tener piernas más largas). En este caso, PCA detecta esa correlación y crea una nueva variable $ Z_1 $ (el primer componente principal) que combina ambas en una sola dirección que captura la mayoría de la varianza.
La segunda nueva variable $ Z_2 $ estará en la dirección perpendicular (ortogonal) y capturará solo la variabilidad que no es explicada por la relación entre estatura y pierna (probablemente ruido o variación individual).
¿Qué hace exactamente PCA en este contexto?¶
Geométricamente:¶
- PCA rota el sistema de coordenadas original para que:
- El primer eje (componente) esté alineado con la dirección de mayor dispersión de los datos.
- El segundo eje esté en la dirección ortogonal siguiente de mayor dispersión, y así sucesivamente.
Estadísticamente:¶
- PCA transforma variables correlacionadas en nuevas variables no correlacionadas.
Cada nueva variable es una combinación lineal de las originales:
$Z_1 = a_{11} X_1 + a_{12} X_2 + \dots + a_{1p} X_p$
Ejemplo clásico e intuitivo¶
Problema:¶
Una empresa de marketing recolecta datos de clientes:
- $ X_1 $: Cantidad de compras al año
- $ X_2 $: Monto total gastado
- $ X_3 $: Número de visitas al sitio web
Estas variables probablemente están fuertemente correlacionadas: quien gasta más, compra más y visita más.
Objetivo:¶
Reducir la dimensionalidad del dataset para:
- Visualizar mejor a los clientes
- Agruparlos con técnicas de clustering
- Eliminar redundancias
Solución con PCA:¶
PCA descubre que:
- El primer componente $ Z_1 $ captura la tendencia general de engagement del cliente (una combinación de las 3 variables).
- El segundo componente $ Z_2 $ puede capturar una dimensión más sutil, como clientes que visitan mucho pero compran poco (comportamiento atípico).
- El tercer componente explica muy poca varianza → puede descartarse.
Así, la empresa reduce de 3 dimensiones a 2 sin perder mucha información, y puede hacer visualizaciones o agrupamientos más eficientemente.
Conclusión¶
PCA condensa la información dispersa y redundante en un conjunto más pequeño de variables nuevas:
- Que no están correlacionadas entre sí
- Que capturan la máxima varianza en orden descendente
- Que permiten trabajar en un espacio más simple y mejor interpretado
Es como mirar los datos desde el ángulo más informativo posible.
Caso de estudio real: Wine Dataset (Clasificación de vinos)¶
El dataset Wine está disponible en sklearn.datasets y contiene datos químicos de vinos cultivados en una misma región de Italia, pero provenientes de 3 variedades diferentes de uvas.
Estructura del dataset:¶
- 178 observaciones (muestras de vino)
- 13 variables numéricas, como:
- Alcohol
- Malic acid
- Ash
- Alcalinidad de la ceniza
- Magnesio
- Fenoles, etc.
- Variable objetivo (no usada en PCA): tipo de vino (clase 0, 1 o 2)
Objetivo del análisis con PCA:¶
- Reducir la dimensionalidad de los datos (de 13 a 2 o 3 dimensiones)
- Visualizar los vinos en el espacio proyectado
- Evaluar si PCA separa naturalmente las variedades de vino (sin saber las etiquetas)
# EJEMPLO
# Importamos las bibliotecas necesarias
import pandas as pd # Para manipulación de datos en formato tabular
from sklearn.datasets import load_wine # Dataset real: datos químicos de vinos
from sklearn.preprocessing import StandardScaler # Para estandarizar (escalar) los datos
from sklearn.decomposition import PCA # Algoritmo de PCA de sklearn
import matplotlib.pyplot as plt # Para visualización gráfica
# Cargar el dataset Wine (vino) incluido en sklearn
wine = load_wine()
X = wine.data # Matriz de características: 178 observaciones x 13 variables (químicas del vino)
y = wine.target # Etiqueta/clase del vino (0, 1 o 2), según la variedad de uva
features = wine.feature_names # Nombres de las variables (alcohol, ácido málico, etc.)
# Escalar los datos (muy importante para PCA)
#PCA es sensible a la escala de las variables. Si una variable tiene mayor rango numérico (como alcohol), dominará la varianza total.
#Por eso usamos StandardScaler(), que transforma cada variable para que tenga media 0 y desviación estándar 1.
X_scaled = StandardScaler().fit_transform(X)
# Aplicar PCA conservando sólo las dos primeras componentes principales
pca = PCA(n_components=2) # Creamos un objeto PCA que conservará solo 2 dimensiones
X_pca = pca.fit_transform(X_scaled) # Ajustamos el modelo PCA y transformamos los datos escalados
#X_pca es ahora una matriz de 178 observaciones en 2 dimensiones. Cada fila es una observación proyectada en el nuevo espacio de componentes principales.
# Visualización en 2D
plt.figure(figsize=(8, 6))
# Dibujar los puntos usando los dos componentes principales (PC1 y PC2)
for target in set(y): # Iteramos por cada clase de vino (0, 1, 2)
plt.scatter(
X_pca[y == target, 0], # Coordenadas en PC1 para la clase 'target'
X_pca[y == target, 1], # Coordenadas en PC2 para la clase 'target'
label=wine.target_names[target], # Nombre de la clase
alpha=0.7 # Transparencia para mejor visualización
)
# Etiquetas de los ejes y título del gráfico
plt.xlabel("PC1") # Primer componente principal
plt.ylabel("PC2") # Segundo componente principal
plt.title("PCA del Wine Dataset (2 componentes)") # Título del gráfico
plt.legend() # Muestra leyenda con nombres de clases
plt.grid(True) # Muestra cuadrícula
plt.show() # Muestra la figura
# Varianza explicada por cada componente
print("Varianza explicada por PC1 y PC2:", pca.explained_variance_ratio_)
print("Varianza acumulada (2D):", sum(pca.explained_variance_ratio_))
print("Features:",features)

Resultados¶
Visualización:
- El gráfico muestra clusters bien definidos que corresponden en gran parte a las clases reales, sin haber usado las etiquetas para entrenar.
- Esto indica que los primeros dos componentes principales ya capturan buena parte de la estructura latente.
Varianza explicada:
- PC1 + PC2 suelen explicar más del 55% de la varianza total.
- Con 3 componentes, se supera el 80% en la mayoría de los casos.
¿Qué aprendemos de este ejemplo?¶
- PCA redujo de 13 a 2 dimensiones preservando gran parte de la información.
- Nos permitió visualizar relaciones y posibles agrupamientos naturales sin conocer las etiquetas.
- Esto es clave en análisis exploratorio, detección de outliers, y preprocesamiento antes de clustering o clasificación.
¿Qué es un autovector en PCA?¶
En el contexto de PCA:
- Cada autovector (o vector propio) es una dirección en el espacio original hacia la cual se proyectan los datos.
- Cada autovector está asociado a un autovalor que indica cuánta varianza explican los datos proyectados sobre esa dirección.
- Estos autovectores forman las nuevas bases del espacio de los datos (son las columnas de la matriz de rotación de PCA).
Matemáticamente¶
Si $ \Sigma $ es la matriz de covarianza de los datos escalados, entonces:
$\Sigma \mathbf{v}_j = \lambda_j \mathbf{v}_j$
- $ \mathbf{v}_j \in \mathbb{R}^p $ es el j-ésimo componente principal (autovector)
- $ \lambda_j $ es su autovalor asociado
- Cada $ \mathbf{v}_j $ tiene $ p $ entradas, una por variable original
¿Qué representa cada entrada de un autovector?¶
Las entradas de $ \mathbf{v}_j $ indican cuánto contribuye cada variable original al componente principal $ j $.
Ejemplo: si tenemos variables $ X_1 = \text{alcohol} $, $ X_2 = \text{magnesio} $, $ X_3 = \text{fenoles} $, etc., entonces:
$\text{PC1} = 0.45 \cdot X_1 + 0.10 \cdot X_2 - 0.38 \cdot X_3 + \cdots$
- Los coeficientes (también llamados loadings) indican importancia y dirección:
- Un valor alto (positivo o negativo) → alta influencia en el componente
- Un valor cercano a 0 → baja contribución
import numpy as np
import pandas as pd
# Obtener los autovectores (componentes principales)
componentes = pca.components_ # Cada fila: un componente principal
# Crear DataFrame con nombres de variables y componentes
df_componentes = pd.DataFrame(componentes, columns=features, index=['PC1', 'PC2'])
# Reordenar columnas según importancia en PC1 (en valor absoluto)
orden_pc1 = df_componentes.loc['PC1'].abs().sort_values(ascending=False).index# Ordenamos las columnas del DataFrame según el orden de importancia en PC1
df_componentes_ordenado = df_componentes[orden_pc1] # Reordenamos las columnas del DataFrame según el orden obtenido
# Mostrar tabla bonita y ordenada
print("\n🔍 Carga de variables en cada componente principal (ordenadas por |PC1|):\n")
print(df_componentes_ordenado.T.round(3))# Transponemos para mostrar variables como filas y componentes como columnas, y redondeamos a 3 decimales
Esto genera una tabla con los "loadings" de cada variable en PC1 y PC2.
¿Cómo interpretar esta tabla?¶
Supongamos que obtienes:
| alcohol | malic_acid | ash | ... | |
|---|---|---|---|---|
| PC1 | 0.39 | 0.23 | 0.28 | ... |
| PC2 | -0.02 | 0.56 | -0.41 | ... |
- PC1 está más relacionado con alcohol y ash → puede interpretarse como un eje de "potencia química".
- PC2 está influido por malic_acid (positivo) y ash (negativo) → puede capturar un contraste ácido vs mineralidad.
Visualización de los autovectores: “biplot” (opcional)¶
Una forma visual de interpretarlos es graficar los vectores sobre la proyección de PCA:
plt.figure(figsize=(10, 8))
plt.scatter(X_pca[:, 0], X_pca[:, 1], alpha=0.4, s=40, edgecolors='k', c='skyblue')
# Dibujar autovectores como flechas (escaladas)
for i, var in enumerate(features):
x = df_componentes.loc['PC1', var]
y = df_componentes.loc['PC2', var]
plt.arrow(0, 0, x * 3, y * 3, color='darkred', alpha=0.6, width=0.01, head_width=0.1)
plt.text(x * 3.4, y * 3.4, var, color='darkred', fontsize=10, ha='center', va='center')
# Líneas guía de los ejes
plt.axhline(0, color='gray', linestyle='--', linewidth=1)
plt.axvline(0, color='gray', linestyle='--', linewidth=1)
# Etiquetas y título
plt.xlabel("PC1", fontsize=12)
plt.ylabel("PC2", fontsize=12)
plt.title("Biplot de PCA (Wine Dataset)", fontsize=14)
plt.grid(True, linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()

Este gráfico ayuda a visualizar qué variables originales tiran de los ejes principales y cómo se relacionan entre ellas.
Conclusión¶
- Cada componente principal es una combinación lineal de las variables originales.
- Las entradas del autovector nos dicen qué variables son más influyentes en esa dirección.
- Esta interpretación ayuda a dar significado a los nuevos ejes creados por PCA y comunicar resultados de forma más útil.
Formulación Matemática Paso a Paso¶
1. Supuestos y preparación¶
Sea una matriz de datos: $\mathbf{X} \in \mathbb{R}^{n \times p}$
donde:
- $ n $ es el número de observaciones,
- $ p $ es el número de características (features).
Asumimos que los datos están centrados en media: $\frac{1}{n} \sum_{i=1}^{n} \mathbf{x}_i = \mathbf{0}$ lo que se puede hacer restando la media columna por columna.
2. Varianza de una proyección¶
Queremos proyectar los datos sobre un vector unitario $ \mathbf{v} \in \mathbb{R}^p $ (es decir, $ \|\mathbf{v}\| = 1 $). La proyección de $ \mathbf{x}_i $ sobre $ \mathbf{v} $ es: $z_i = \mathbf{x}_i^\top \mathbf{v}$
La varianza de las proyecciones es:
$\mathrm{Var}(z) = \frac{1}{n} \sum_{i=1}^n z_i^2 = \frac{1}{n} \sum_{i=1}^n (\mathbf{x}_i^\top \mathbf{v})^2 = \mathbf{v}^\top \Sigma \mathbf{v}$
donde $ \Sigma = \frac{1}{n} \mathbf{X}^\top \mathbf{X} $ es la matriz de covarianza muestral.
Demostración¶
Queremos encontrar una dirección $ \mathbf{v} $ en el espacio de las variables originales $ \mathbb{R}^p $, tal que al proyectar nuestros datos sobre esa dirección, la varianza de las proyecciones sea máxima. Esta es la base del primer componente principal.
Paso a paso: proyección sobre un vector $ \mathbf{v} $¶
2.1. ¿Qué significa "proyectar"?¶
Sea una observación $ \mathbf{x}_i \in \mathbb{R}^p $ (es decir, un punto en un espacio de $ p $ dimensiones). Si proyectamos ese punto sobre un vector unitario $ \mathbf{v} $, obtenemos un valor escalar:
$z_i = \mathbf{x}_i^\top \mathbf{v}$
Esto es el producto punto: mide cuánto de $ \mathbf{x}_i $ está alineado con $ \mathbf{v} $.
Entonces, $ z_i $ es la proyección escalar de la observación $ \mathbf{x}_i $ sobre la dirección $ \mathbf{v} $.
2.2. ¿Por qué queremos la varianza de $ z_i $?¶
Porque queremos encontrar la dirección $ \mathbf{v} $ que maximiza la varianza de esas proyecciones. En PCA, esa dirección se considera la más informativa de los datos (la que captura más estructura).
2.3. Cómo se calcula la varianza de las proyecciones¶
La varianza muestral de los valores proyectados $ z_i $ es:
$\mathrm{Var}(z) = \frac{1}{n} \sum_{i=1}^n z_i^2$
Recordemos que ya centramos los datos, así que la media de $ z $ es cero y podemos omitir $ \bar{z} $.
Ahora sustituimos $ z_i = \mathbf{x}_i^\top \mathbf{v} $:
$\mathrm{Var}(z) = \frac{1}{n} \sum_{i=1}^n (\mathbf{x}_i^\top \mathbf{v})^2$
Esta fórmula expresa cómo varía la proyección de los datos en la dirección $ \mathbf{v} $.
Este término es un escalar al cuadrado (porque $ \mathbf{x}_i^\top \mathbf{v} \in \mathbb{R} $). Lo podemos reescribir como:
$(\mathbf{x}_i^\top \mathbf{v})^2 = (\mathbf{v}^\top \mathbf{x}_i)(\mathbf{x}_i^\top \mathbf{v}) = \mathbf{v}^\top \mathbf{x}_i \mathbf{x}_i^\top \mathbf{v}$
Porque:
- $ \mathbf{x}_i^\top \mathbf{v} $ es un escalar,
- $ \mathbf{x}_i \mathbf{x}_i^\top \in \mathbb{R}^{p \times p} $, es un producto externo,
- La expresión completa está "envuelta" por $ \mathbf{v}^\top $ y $ \mathbf{v} $.
2.4. Escribir esto como forma cuadrática¶
$\mathrm{Var}(z) = \frac{1}{n} \sum_{i=1}^{n} \mathbf{v}^\top \mathbf{x}_i \mathbf{x}_i^\top \mathbf{v}$
Podemos sacar $ \mathbf{v}^\top $ y $ \mathbf{v} $ fuera de la suma, porque no dependen de $ i $:
$\mathrm{Var}(z) = \mathbf{v}^\top \left( \frac{1}{n} \sum_{i=1}^{n} \mathbf{x}_i \mathbf{x}_i^\top \right) \mathbf{v}$
Y ese término central es, por definición, la matriz de covarianza muestral (si los datos están centrados):
$\Sigma = \frac{1}{n} \sum_{i=1}^{n} \mathbf{x}_i \mathbf{x}_i^\top$
Por lo tanto:
$\mathrm{Var}(z) = \mathbf{v}^\top \Sigma \mathbf{v}$
¿Qué representa esto?¶
- $ \mathbf{v}^\top \Sigma \mathbf{v} $ es una forma cuadrática: describe la varianza de los datos proyectados en la dirección $ \mathbf{v} $.
- Esta fórmula es la función objetivo que queremos maximizar en PCA para encontrar la primera componente principal.
Intuición¶
- Queremos encontrar una dirección $ \mathbf{v} $ sobre la cual, si lanzamos todos los puntos del dataset, caigan lo más dispersos posible (alta varianza).
- Ese eje será la primera componente principal.
- Lo que sigue en el procedimiento es maximizar esta varianza bajo la restricción $ \|\mathbf{v}\| = 1 $, lo que nos lleva a un problema de autovalores.
3. Optimización principal (primer componente)¶
Buscamos el primer componente principal $ \mathbf{v}_1 $ como la dirección que maximiza la varianza de la proyección:
$\max_{\mathbf{v}_1 \in \mathbb{R}^p} \mathbf{v}_1^\top \Sigma \mathbf{v}_1 \quad \text{sujeto a } \|\mathbf{v}_1\| = 1$
Este es un problema clásico de optimización cuadrática con restricción cuadrática, cuya solución es:
$ \mathbf{v}_1 $ es el autovector principal de $ \Sigma $ (el asociado al mayor autovalor $ \lambda_1 $).
La varianza máxima obtenida es:
$\mathbf{v}_1^\top \Sigma \mathbf{v}_1 = \lambda_1$
3.0 Vamos por parte¶
Objetivo: Encontrar la dirección que maximiza la varianza proyectada¶
Queremos encontrar un vector unitario $ \mathbf{v} $ (es decir, $ \|\mathbf{v}\| = 1 $) tal que la varianza de los datos proyectados sobre él sea máxima.
Nuestra función a maximizar es:¶
$\mathrm{Var}(z) = \mathbf{v}^\top \Sigma \mathbf{v}$
Sujeto a la restricción de normalización:¶
$\|\mathbf{v}\|^2 = \mathbf{v}^\top \mathbf{v} = 1$
Planteamiento como problema de optimización con restricción¶
Este es un problema clásico de optimización cuadrática con restricción cuadrática. Se resuelve usando el método de multiplicadores de Lagrange.
Paso a paso¶
3.1. Definimos la función Lagrangiana:¶
$\mathcal{L}(\mathbf{v}, \lambda) = \mathbf{v}^\top \Sigma \mathbf{v} - \lambda (\mathbf{v}^\top \mathbf{v} - 1)$
- El primer término es lo que queremos maximizar: la varianza proyectada.
- El segundo término impone la restricción de norma 1.
3.2. Derivamos con respecto a $ v $ y la igualamos a cero¶
Partimos de la Lagrangiana:
$ \mathcal{L}(v,\lambda) = v^\top \Sigma v - \lambda (v^\top v - 1) $
Paso 1: expandimos la Lagrangiana
Distribuyendo el término con $ \lambda $:
$ \mathcal{L}(v,\lambda) = v^\top \Sigma v - \lambda v^\top v + \lambda $
Ahora derivamos con respecto a $ v $:
$ \nabla_v \mathcal{L} = \nabla_v (v^\top \Sigma v) - \lambda \nabla_v (v^\top v) + \nabla_v(\lambda) $
Como $ \lambda $ es constante respecto de $ v $:
$ \nabla_v(\lambda) = 0 $
Entonces:
$ \nabla_v \mathcal{L} = \nabla_v (v^\top \Sigma v) - \lambda \nabla_v (v^\top v) $
Paso 2: derivamos el término $ v^\top \Sigma v $
Primero escribimos el producto en forma expandida:
$ v^\top \Sigma v = \sum_{i=1}^p \sum_{j=1}^p v_i \Sigma_{ij} v_j $
Ahora derivamos respecto de una componente cualquiera $ v_k $:
$ \frac{\partial}{\partial v_k}(v^\top \Sigma v) = \frac{\partial}{\partial v_k} \left( \sum_{i=1}^p \sum_{j=1}^p v_i \Sigma_{ij} v_j \right) $
La derivada actúa sobre todos los términos donde aparece $ v_k $. Eso ocurre en dos casos:
cuando $ i = k $, cuando $ j = k $.
Entonces:
$ \frac{\partial}{\partial v_k}(v^\top \Sigma v) = \sum_{j=1}^p \Sigma_{kj} v_j + \sum_{i=1}^p v_i \Sigma_{ik} $
El primer término corresponde a la componente $ k $ de $ \Sigma v $:
$ \sum_{j=1}^p \Sigma_{kj} v_j = (\Sigma v)_k $
El segundo término corresponde a la componente $ k $ de $ \Sigma^\top v $:
$ \sum_{i=1}^p v_i \Sigma_{ik} = (\Sigma^\top v)_k $
Por tanto:
$ \frac{\partial}{\partial v_k}(v^\top \Sigma v) = (\Sigma v)_k + (\Sigma^\top v)_k $
En forma vectorial:
$ \nabla_v (v^\top \Sigma v) = \Sigma v + \Sigma^\top v $
Como $ \Sigma $ es una matriz de covarianza, es simétrica, así que:
$ \Sigma^\top = \Sigma $
Luego:
$ \nabla_v (v^\top \Sigma v) = 2\Sigma v $
Paso 3: derivamos el término $ v^\top v $
Tenemos:
$ v^\top v = \sum_{i=1}^p v_i^2 $
Derivando respecto de $ v_k $:
$ \frac{\partial}{\partial v_k}(v^\top v) = \frac{\partial}{\partial v_k} \left( \sum_{i=1}^p v_i^2 \right) = 2v_k $
Entonces, en forma vectorial:
$ \nabla_v (v^\top v) = 2v $
Paso 4: reemplazamos en la derivada total
Sustituyendo ambos resultados en la Lagrangiana:
$ \nabla_v \mathcal{L} = 2\Sigma v - \lambda(2v) $
$ \nabla_v \mathcal{L} = 2\Sigma v - 2\lambda v $
Igualamos a cero:
$ 2\Sigma v - 2\lambda v = 0 $
Dividimos ambos lados por 2:
$ \Sigma v = \lambda v $
Resultado
Llegamos a la ecuación:
$ \Sigma v = \lambda v $
Aquí aparecen los autovalores y autovectores!¶
La ecuación anterior es la definición del problema de autovalores: estamos diciendo que $ \mathbf{v} $ es un autovector de $ \Sigma $ y que $ \lambda $ es su correspondiente autovalor.
Conclusión¶
- La dirección que maximiza la varianza proyectada de los datos centrados es el autovector principal de $ \Sigma $, el asociado al mayor autovalor $ \lambda_1 $.
- La varianza máxima obtenida en esa dirección es precisamente: $\mathbf{v}^\top \Sigma \mathbf{v} = \lambda_1$
Resumen¶
| Concepto | Significado |
|---|---|
| $ \Sigma \mathbf{v} = \lambda \mathbf{v} $ | $ \mathbf{v} $ es un autovector de la matriz de covarianza |
| $ \lambda $ | Varianza explicada por el componente |
| Primer componente | Dirección de máxima varianza |
| Restricción $ |\mathbf{v}| = 1 $ | Para evitar que $ \mathbf{v} $ crezca indefinidamente y trivialice la maximización |
| Autovalores ordenados $ \lambda_1 \ge \lambda_2 \ge \cdots $ | Prioridad de componentes |
4. Componentes subsiguientes¶
Para obtener los siguientes componentes principales:
- Se resuelve el mismo problema, añadiendo la restricción de ortogonalidad con los autovectores ya encontrados.
- Es decir, el segundo componente principal es el autovector asociado al segundo mayor autovalor y es ortogonal al primero.
Para obtener el segundo componente principal $ \mathbf{v}_2 $, resolvemos el mismo problema, pero añadiendo la restricción de ortogonalidad:
$\max_{\mathbf{v}_2 \in \mathbb{R}^p} \mathbf{v}_2^\top \Sigma \mathbf{v}_2 \quad \text{sujeto a } \|\mathbf{v}_2\| = 1 \text{ y } \mathbf{v}_2^\top \mathbf{v}_1 = 0$
Y así sucesivamente.
En general, los componentes principales son los autovectores ortogonales de $ \Sigma $, y la varianza explicada por cada componente es su autovalor asociado.
5. Representación de los datos en el nuevo espacio¶
Los datos proyectados (scores) en los primeros $ k $ componentes son:
$\mathbf{Z} = \mathbf{X} \mathbf{V}_k$
donde $ \mathbf{V}_k \in \mathbb{R}^{p \times k} $ contiene en sus columnas los primeros $ k $ autovectores.
Esto nos da una nueva representación de los datos en un espacio de menor dimensión $ \mathbb{R}^k $, preservando la mayor parte de la varianza.
Interpretación Geométrica¶
- Cada componente principal representa un eje en una nueva base ortogonal.
- El primer eje apunta en la dirección de mayor varianza de los datos.
- Los siguientes ejes son ortogonales al anterior y capturan la siguiente mayor varianza disponible.
- PCA es equivalente a reescalar y rotar el espacio para alinear los ejes con las direcciones más informativas.
Varianza explicada acumulada¶
Se define como:
$\text{Varianza Explicada Acumulada}(k) = \frac{\sum_{j=1}^{k} \lambda_j}{\sum_{j=1}^{p} \lambda_j}$
Sirve para elegir cuántos componentes usar. Por ejemplo, si los primeros 2 componentes explican el 95% de la varianza, probablemente sean suficientes para representar los datos.
Propiedades clave de PCA¶
| Propiedad | Explicación breve |
|---|---|
| Linealidad | PCA es una transformación lineal. |
| Ortogonalidad | Los componentes son ortogonales entre sí. |
| No usa etiquetas | Es una técnica no supervisada. |
| Sensible a escala | Es importante escalar los datos si las variables están en distintas unidades. |
Resumen¶
- PCA transforma los datos a un nuevo sistema de coordenadas donde las variables están desacopladas.
- Se utiliza para reducción de dimensionalidad, visualización, preprocesamiento, y eliminación de ruido.
- Su base matemática es sólida y se conecta con el álgebra lineal (autovalores/autovectores de la matriz de covarianza).
¿Qué muestra este GIF? — Intuición visual de PCA¶
Contexto¶
Este GIF ilustra el proceso central de Análisis de Componentes Principales (PCA) cuando tenemos dos variables altamente correlacionadas. Visualmente, vemos una nube de puntos rojos en 2D que será transformada por PCA.
Paso a paso¶
Distribución inicial de los datos
- Cada punto rojo representa una observación con dos variables: $ X_1 $ y $ X_2 $.
- Las variables están correlacionadas → los puntos forman una nube en forma de elipse inclinada.
- El sistema de coordenadas original está alineado con los ejes cartesianos.
- Se estandarizan los datos.
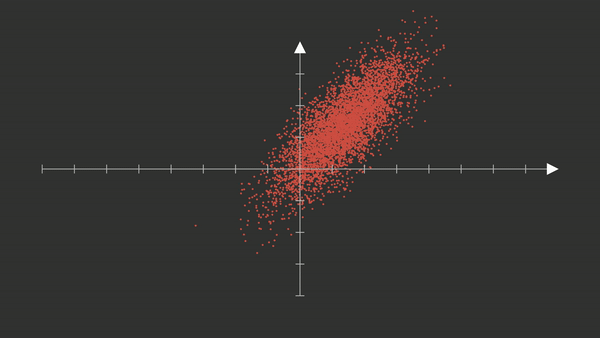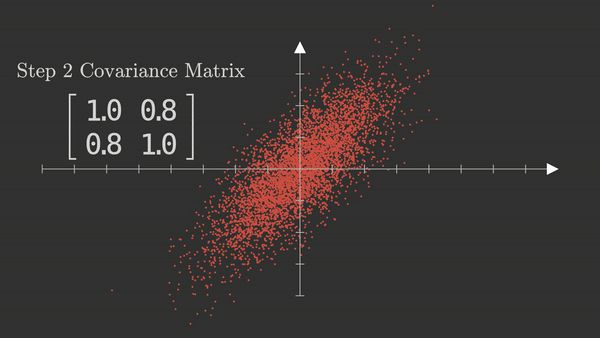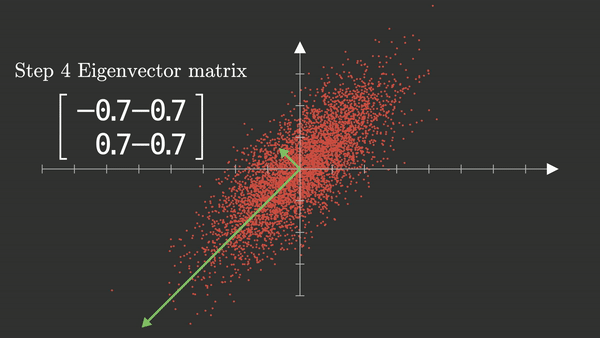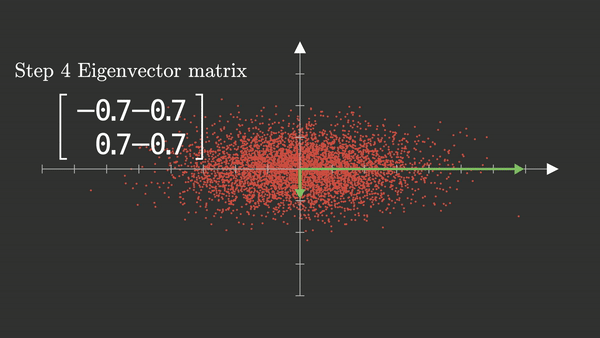
Matriz de covarianza
Diagonal ($ \Sigma_{11} = \Sigma_{22} = 1.0 $):
Las dos variables tienen varianza unitaria, es decir, ya han sido escaladas (standardizadas). Esto es habitual antes de aplicar PCA.Fuera de la diagonal ($ \Sigma_{12} = \Sigma_{21} = 0.8 $):
Hay una covarianza positiva alta entre ambas variables.
Esto implica que los valores de $ X_1 $ y $ X_2 $ tienden a subir y bajar juntos → es lo que genera la inclinación de la nube.
Esta matriz nos dice que ambas variables tienen la misma variabilidad (1.0, datos estandarizacos), pero además están correlacionadas positivamente (0.8). PCA va a 'leer' esta estructura, identificar que hay información redundante, y crear una nueva base donde la mayoría de la varianza esté en un solo eje.
Cálculo de los componentes principales: Eigenvectors
- PCA encuentra una nueva base ortogonal (ejes verdes):
- El primer componente principal (PC1) apunta en la dirección de máxima varianza.
- El segundo componente (PC2) es perpendicular a PC1.
- PCA encuentra una nueva base ortogonal (ejes verdes):
Matriz de eigenvectors: Rotación del sistema de coordenadas
- La imagen muestra la matriz de autovectores y una flecha verde que apunta hacia abajo a la izquierda, alineada con la diagonal negativa del plano.
- Cada columna es un autovector de la matriz de covarianza $ \Sigma $.
- Primer autovector $ \mathbf{v}_1 = [-0.7,\ -0.7] $ (notar que en la imagen los vectores columna están al revés) apunta desde el centro hacia la izquierda y abajo. Es la dirección principal (PC1), alineada con la mayor varianza. Captura la inclinación positiva de los datos, aunque tenga signo negativo: recuerda, el signo no importa, solo la dirección.
- Segundo autovector $ \mathbf{v}_2 = [-0.7,\ 0.7] $ apunta hacia la izquierda y hacia arriba. Es perpendicular a $ \mathbf{v}_1 $, como debe ser (los autovectores de matrices simétricas como $ \Sigma $ son ortogonales). Captura la segunda dirección de variabilidad, mucho menor.
- PCA rota el sistema para que PC1 quede alineado con la dirección de mayor dispersión de los datos.
- Esta rotación no cambia los datos — solo cambia la forma en que los miramos.
Los signos en la matriz de autovectores no importan por sí solos, lo importante es la orientación relativa de los vectores. En esta figura, PCA encontró que la dirección de mayor varianza está diagonalizada hacia abajo a la izquierda (por eso el autovector tiene ambas componentes negativas). El otro eje está perpendicular a ese, y apunta hacia arriba a la izquierda.
¿Qué enseña este GIF?¶
- PCA encuentra la dirección más informativa de los datos.
- Reduce redundancia cuando las variables están correlacionadas.
- Proyectar los datos sobre PC1 nos permite trabajar con menos dimensiones conservando la mayoría de la varianza.
- Es un método lineal, geométrico y basado en rotación del sistema de coordenadas.
Aplicaciones prácticas¶
- Visualización de datos multivariados en 2D.
- Preprocesamiento antes de clustering o modelos supervisados.
- Interpretación de fenómenos latentes (como tamaño, intensidad, complejidad...).
# Simularemos el proceso del GIF paso a paso con datos sintéticos
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 1. Generar datos 2D correlacionados
np.random.seed(42)
n_samples = 1000
mean = [0, 0]
cov = [[3, 2.5], [2.5, 3]] # correlación alta entre X1 y X2 (la covarianza entre X1 y X2 es 2.5, lo que indica que tienden a aumentar juntos)
X = np.random.multivariate_normal(mean, cov, size=n_samples) # datos sintéticos con correlación entre las dos variables (X1 y X2)
# 2. Estandarizar los datos
X_scaled = StandardScaler().fit_transform(X) # PCA es sensible a la escala de las variables, por eso es importante estandarizar antes de aplicar PCA. Esto asegura que cada variable contribuya por igual a la varianza total.
# 3. Aplicar PCA
pca = PCA(n_components=2) # Creamos un objeto PCA que conservará solo 2 dimensiones
X_pca = pca.fit_transform(X_scaled) # Ajustamos el modelo PCA y transformamos los datos escalados
components = pca.components_ # Autovectores (direcciones de los componentes principales)
explained_var = pca.explained_variance_ # Varianza explicada por cada componente
# 4. Visualización paso a paso
fig, axs = plt.subplots(1, 3, figsize=(18, 5))
# A. Datos originales
axs[0].scatter(X_scaled[:, 0], X_scaled[:, 1], alpha=0.4, color='tomato')
axs[0].set_title("Datos originales (correlacionados)")
axs[0].set_xlabel("X1 (escalado)")
axs[0].set_ylabel("X2 (escalado)")
axs[0].axis('equal')
axs[0].grid(True)
# Dibujar componentes en los datos originales
origin = np.mean(X_scaled, axis=0)
for length, vector in zip(np.sqrt(explained_var), components):
v = vector * length * 3
axs[0].arrow(origin[0], origin[1], v[0], v[1],
color='black', head_width=0.2, linewidth=2)
# B. Datos rotados (cambio de base)
X_rotated = X_scaled @ components.T
axs[1].scatter(X_rotated[:, 0], X_rotated[:, 1], alpha=0.4, color='mediumseagreen')
axs[1].set_title("Datos en la base de componentes principales")
axs[1].set_xlabel("PC1")
axs[1].set_ylabel("PC2")
axs[1].axis('equal')
axs[1].grid(True)
# C. Proyección sobre PC1 (reducción)
axs[2].scatter(X_rotated[:, 0], np.zeros_like(X_rotated[:, 0]), alpha=0.4, color='steelblue')
axs[2].set_title("Proyección sobre PC1 (reducción a 1D)")
axs[2].set_xlabel("PC1")
axs[2].set_yticks([])
axs[2].grid(True)
plt.tight_layout()
plt.show()

# --- Imprimir componentes de los vectores principales ---
print("Vectores de las componentes principales:\n")
print(components)
for i, vec in enumerate(components, start=1):
print(f"PC{i}: {vec}")
print(f" Componente en X1: {vec[0]:.4f}") # Imprime la componente en X1 con 4 decimales, usamos el vector columna porque cada fila es un componente principal, y cada columna es una variable original (X1, X2)
print(f" Componente en X2: {vec[1]:.4f}\n")
# Verificar ortogonalidad
producto_punto = np.dot(components[0], components[1])
print(f"Producto punto entre PC1 y PC2: {producto_punto:.6f}")
explained_var_ratio = pca.explained_variance_ratio_ # proporción de varianza explicada
print("Varianza explicada:\n")
for i, vec in enumerate(components, start=1):
print(f"PC{i}:")
print(f" Vector: {vec}")
print(f" Varianza explicada: {explained_var[i-1]:.4f}")
print(f" Proporción de varianza explicada: {explained_var_ratio[i-1]:.4%}\n")
Simulación del proceso de PCA sobre datos correlacionados¶
Panel 1: Datos originales¶
- Los puntos rojos representan observaciones con dos variables altamente correlacionadas.
- La nube tiene forma de elipse, indicando una dirección dominante de dispersión.
- Las flechas negras muestran los componentes principales encontrados por PCA:
- La flecha más larga (PC1) apunta en la dirección de máxima varianza.
- La flecha perpendicular (PC2) representa la segunda dirección ortogonal con menor varianza.
Panel 2: Datos rotados a la base de componentes principales¶
- Los mismos datos ahora están representados en el nuevo sistema de coordenadas (PC1 y PC2).
- El eje horizontal (PC1) contiene la mayoría de la información (varianza).
- El eje vertical (PC2) apenas varía → puede ser descartado sin perder demasiado.
Panel 3: Proyección sobre PC1¶
- Aquí se muestra la reducción a 1 dimensión: los puntos son proyectados sobre PC1.
- Perdemos algo de información (PC2), pero retenemos la estructura principal de los datos.
- Este paso es útil para:
- Compresión de datos.
- Visualización simplificada.
- Preprocesamiento para modelos supervisados o clustering.
# Cargar los datos Iris correctamente
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import pandas as pd
# Cargar datos
data = load_iris()
X = data.data
y = data.target
features = data.feature_names
# Escalar los datos
X_scaled = StandardScaler().fit_transform(X) #
# Aplicar PCA
pca = PCA(n_components=2) # Creamos un objeto PCA que conservará solo 2 dimensiones
X_pca = pca.fit_transform(X_scaled) # Ajustamos el modelo PCA y transformamos los datos escalados
# 1. Visualización PCA
plt.figure(figsize=(8, 6))
for label in set(y):
plt.scatter(X_pca[y == label, 0], X_pca[y == label, 1],
label=data.target_names[label], alpha=0.7)
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.title("PCA en dataset Iris")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 2. Varianza explicada
explained_var = pca.explained_variance_ratio_ # proporción de varianza explicada por cada componente
plt.figure(figsize=(5, 4))
plt.bar(x=["PC1", "PC2"], height=explained_var * 100, color=["#1f77b4", "#ff7f0e"])
plt.ylabel("% Varianza Explicada")
plt.title("Varianza Explicada por Componentes")
plt.ylim(0, 100)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
# 3. Cargas (loadings)
componentes = pca.components_ # Cada fila es un componente principal, cada columna es una variable original. El valor indica cuánto contribuye cada variable a ese componente.
df_componentes = pd.DataFrame(componentes, columns=features, index=["PC1", "PC2"]) # Creamos un DataFrame para mostrar las cargas de cada variable en cada componente principal, con nombres de columnas y filas
df_top = df_componentes.T.sort_values("PC1", key=abs, ascending=False) # Reordenamos las filas del DataFrame según el orden de importancia en PC1 (en valor absoluto)
# Graficar las cargas principales
df_top.plot(kind='bar', figsize=(8, 5))
plt.axhline(0, color='black', linewidth=0.8)
plt.title("Cargas de las variables originales en PC1 y PC2 (Iris)")
plt.ylabel("Carga")
plt.xticks(rotation=45, ha='right')
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()



features
Análisis PCA en el Dataset Iris¶
1. Visualización en 2D¶
- Se observa una separación clara del grupo Setosa, mientras que Versicolor y Virginica se solapan parcialmente.
- Esto sugiere que con solo 2 componentes principales, ya podemos visualizar gran parte de la estructura del dataset.
2. Varianza explicada¶
- PC1 explica aproximadamente 72% de la varianza.
- PC2 agrega otro 23%, sumando cerca del 95% en total.
- Es decir, PCA reduce de 4 a 2 dimensiones sin perder casi nada de información.
3. Cargas (loadings) de las variables originales¶
| Variable | PC1 | PC2 |
|---|---|---|
| petal length (cm) | 0.58 | 0.02 |
| petal width (cm) | 0.56 | 0.07 |
| sepal length (cm) | 0.52 | 0.38 |
| sepal width (cm) | -0.27 | 0.92 |
- PC1 está dominado por las variables de pétalo → representa tamaño del pétalo.
- PC2 está dominado por sepal width → refleja variación en ancho del sépalo.
Este análisis te permite mostrar cómo PCA no solo reduce la dimensión y visualiza los datos, sino que también revela cuáles variables originales explican mejor la estructura del dataset.
Ejemplo 2: Genómica — Dataset de Cáncer de Mama (Breast Cancer)¶
Contexto:¶
Este dataset contiene medidas bioquímicas de tumores en pacientes. Cada paciente tiene 30 características (como textura, perímetro, etc.) que describen el tumor. Queremos ver si usando PCA podemos visualizar diferencias entre tumores benignos y malignos en solo dos dimensiones.
# Cargamos los datos reales del Breast Cancer dataset
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
data_cancer = load_breast_cancer()
# Estandarizamos las variables: PCA es sensible a la escala
X_cancer = StandardScaler().fit_transform(data_cancer.data)
# Aplicamos PCA para reducir a 2 dimensiones
pca_cancer = PCA(n_components=2)
X_cancer_pca = pca_cancer.fit_transform(X_cancer)
# Visualizamos el resultado
import matplotlib.pyplot as plt
plt.figure(figsize=(6,5))
for target in [0, 1]:
plt.scatter(X_cancer_pca[data_cancer.target == target, 0],
X_cancer_pca[data_cancer.target == target, 1],
label=data_cancer.target_names[target], alpha=0.6)
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.title("PCA - Cáncer de Mama")
plt.legend()
plt.grid(True)
plt.show()

# 2. Varianza explicada por los componentes
explained_var = pca_cancer.explained_variance_ratio_
plt.figure(figsize=(6, 4))
plt.bar(x=[1, 2], height=explained_var * 100, color=["#1f77b4", "#ff7f0e"])
plt.xticks([1, 2], ["PC1", "PC2"])
plt.ylabel("% Varianza Explicada")
plt.title("Varianza Explicada por Componentes Principales")
plt.ylim(0, 100)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
# 3. Cargas (loadings) de cada variable en los componentes principales
import pandas as pd
componentes = pca_cancer.components_
features = data_cancer.feature_names
df_componentes = pd.DataFrame(componentes, columns=features, index=['PC1', 'PC2'])
# Tomar las 8 variables más influyentes en PC1 (por valor absoluto)
top_features_pc1 = df_componentes.loc['PC1'].abs().sort_values(ascending=False).head(8).index
df_top = df_componentes[top_features_pc1].T
# Gráfico de barras de las cargas principales
df_top.plot(kind='bar', figsize=(8, 5))
plt.axhline(0, color='black', linewidth=0.8)
plt.title("Cargas de las variables más influyentes en PC1 y PC2")
plt.ylabel("Carga (Loading)")
plt.xticks(rotation=45, ha='right')
plt.grid(True, axis='y', linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()


Interpretación de Resultados¶
1. Visualización en 2D (PCA)¶
- Se muestra una separación clara entre tumores benignos y malignos en el plano de los dos primeros componentes principales.
- Esto sugiere que la estructura del dato original en 30 dimensiones puede ser capturada en solo 2 dimensiones con bastante eficacia.
2. Varianza explicada¶
- PC1 y PC2 juntos explican un porcentaje importante de la varianza total (visible en el gráfico de barras).
- Esto justifica el uso de PCA como técnica de reducción para análisis visual y exploratorio.
3. Interpretación de variables más influyentes¶
Se muestran las 8 variables con mayor carga en PC1, las que más contribuyen a la dirección principal:
| Variable | Carga en PC1 |
|---|---|
| mean concave points | 0.26 |
| mean concavity | 0.26 |
| worst concave points | 0.25 |
| mean compactness | 0.24 |
| worst perimeter | 0.24 |
Esto sugiere que la concavidad y compactación del tumor son las características más determinantes para separar los tipos de cáncer en este análisis.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score
# =========================================================
# 1. Cargar datos
# =========================================================
data_digits = load_digits()
X = data_digits.data
y = data_digits.target
print("Shape de X:", X.shape)
print("Número de clases:", len(np.unique(y)))
print("Dimensión original de cada imagen:", X.shape[1]) # 64 pixeles (8x8)
# =========================================================
# 2. Estandarizar
# =========================================================
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# =========================================================
# 3. PCA a 2 dimensiones para visualización
# =========================================================
pca_2d = PCA(n_components=2)
X_pca_2d = pca_2d.fit_transform(X_scaled)
explained_var = pca_2d.explained_variance_
explained_ratio = pca_2d.explained_variance_ratio_
print("=== Varianza explicada en 2D ===")
for i in range(2):
print(f"PC{i+1}:")
print(f" Varianza explicada: {explained_var[i]:.4f}")
print(f" Proporción de varianza explicada: {explained_ratio[i]:.2%}")
print("\nVarianza explicada acumulada:")
print(explained_ratio.cumsum())
# =========================================================
# 4. Scatter plot por dígito
# =========================================================
plt.figure(figsize=(8, 7))
for digit in range(10):
plt.scatter(
X_pca_2d[y == digit, 0],
X_pca_2d[y == digit, 1],
label=str(digit),
alpha=0.5
)
plt.xlabel(f"PC1 ({explained_ratio[0]:.1%} var. explicada)")
plt.ylabel(f"PC2 ({explained_ratio[1]:.1%} var. explicada)")
plt.title("PCA - Dígitos manuscritos (Digits dataset)")
plt.legend(title="Dígito")
plt.grid(True)
plt.show()

# =========================================================
# 5. Centroides por dígito en el espacio PCA
# =========================================================
df_pca = pd.DataFrame(X_pca_2d, columns=["PC1", "PC2"])
df_pca["digit"] = y
centroides = df_pca.groupby("digit")[["PC1", "PC2"]].mean()
print("=== Centroides por dígito en espacio PCA ===")
print(centroides.round(3))
# =========================================================
# 6. Visualización con centroides
# =========================================================
plt.figure(figsize=(8, 7))
for digit in range(10):
datos_d = df_pca[df_pca["digit"] == digit]
plt.scatter(
datos_d["PC1"],
datos_d["PC2"],
alpha=0.35,
label=str(digit)
)
plt.scatter(
centroides["PC1"],
centroides["PC2"],
s=250,
marker="X",
edgecolor="black",
linewidth=1.5,
label="Centroides"
)
for digit, row in centroides.iterrows():
plt.text(
row["PC1"] + 0.15,
row["PC2"] + 0.15,
str(digit),
fontsize=11,
weight="bold"
)
plt.xlabel(f"PC1 ({explained_ratio[0]:.1%} var. explicada)")
plt.ylabel(f"PC2 ({explained_ratio[1]:.1%} var. explicada)")
plt.title("PCA de dígitos manuscritos con centroides")
plt.legend(title="Dígito")
plt.grid(True)
plt.show()

# =========================================================
# 7. Silhouette score usando las etiquetas reales
# =========================================================
sil_score = silhouette_score(X_pca_2d, y)
print(f"Silhouette score en espacio PCA 2D: {sil_score:.4f}")
# =========================================================
# 8. PCA con más componentes para ver varianza acumulada
# =========================================================
pca_full = PCA()
X_pca_full = pca_full.fit_transform(X_scaled)
cum_var = np.cumsum(pca_full.explained_variance_ratio_)
plt.figure(figsize=(8, 5))
plt.plot(range(1, len(cum_var) + 1), cum_var, marker="o")
plt.axhline(0.80, linestyle="--")
plt.axhline(0.90, linestyle="--")
plt.axhline(0.95, linestyle="--")
plt.xlabel("Número de componentes")
plt.ylabel("Varianza explicada acumulada")
plt.title("Varianza explicada acumulada en el dataset de dígitos")
plt.grid(True)
plt.show()
# Cantidad mínima de componentes para ciertos umbrales
k80 = np.argmax(cum_var >= 0.80) + 1
k90 = np.argmax(cum_var >= 0.90) + 1
k95 = np.argmax(cum_var >= 0.95) + 1
print(f"Componentes para explicar al menos 80%: {k80}")
print(f"Componentes para explicar al menos 90%: {k90}")
print(f"Componentes para explicar al menos 95%: {k95}")

# =========================================================
# 9. Visualizar los loadings de PC1 y PC2 como imágenes 8x8
# =========================================================
pc1_img = pca_2d.components_[0].reshape(8, 8)
pc2_img = pca_2d.components_[1].reshape(8, 8)
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
axes[0].imshow(pc1_img, cmap="coolwarm")
axes[0].set_title("Loading de PC1")
axes[0].axis("off")
axes[1].imshow(pc2_img, cmap="coolwarm")
axes[1].set_title("Loading de PC2")
axes[1].axis("off")
plt.tight_layout()
plt.show()

# =========================================================
# 10. Reconstrucción aproximada con distinto número de componentes
# =========================================================
# Elegimos algunas imágenes de ejemplo
indices = [0, 1, 2, 3, 4]
componentes_a_probar = [2, 10, 20, 40]
fig, axes = plt.subplots(len(indices), len(componentes_a_probar) + 1, figsize=(12, 10))
for fila, idx in enumerate(indices):
# Imagen original
axes[fila, 0].imshow(X[idx].reshape(8, 8), cmap="gray_r")
axes[fila, 0].set_title(f"Original\nEtiqueta: {y[idx]}")
axes[fila, 0].axis("off")
for col, k in enumerate(componentes_a_probar, start=1):
pca_k = PCA(n_components=k) # Creamos un objeto PCA que conservará 'k' componentes principales
X_k = pca_k.fit_transform(X_scaled) # Ajustamos el modelo PCA con 'k' componentes y transformamos los datos escalados
X_rec_scaled = pca_k.inverse_transform(X_k) # Reconstruimos los datos aproximados a partir de la reducción a 'k' componentes. Esto nos da una versión aproximada de los datos originales, pero con pérdida de información dependiendo de 'k'.
# Volvemos a escala aproximada original
X_rec = scaler.inverse_transform(X_rec_scaled)
axes[fila, col].imshow(X_rec[idx].reshape(8, 8), cmap="gray_r")
axes[fila, col].set_title(f"{k} comp.")
axes[fila, col].axis("off")
plt.tight_layout()
plt.show()

Ejemplo 4: Segmentación de clientes (datos simulados)¶
Contexto:¶
Simulamos datos de clientes agrupados en 4 segmentos según comportamiento. Cada cliente tiene 6 variables, pero podrías imaginar más (compra promedio, visitas, fidelidad...). Aplicamos PCA para:
- Confirmar si los grupos son distinguibles.
- Visualizar el espacio reducido en 2D.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score
# =========================================================
# 1. Simular clientes con estructura latente correlacionada
# =========================================================
np.random.seed(42)
n_por_segmento = 100
segmentos = [0, 1, 2, 3]
datos = []
labels = []
for seg in segmentos:
# Dos factores latentes por segmento:
# F1 = valor / intensidad de compra
# F2 = sensibilidad a promociones / actividad digital
if seg == 0: # premium leales
F1 = np.random.normal(loc=2.2, scale=0.6, size=n_por_segmento)
F2 = np.random.normal(loc=-1.0, scale=0.5, size=n_por_segmento)
elif seg == 1: # cazadores de ofertas
F1 = np.random.normal(loc=0.3, scale=0.6, size=n_por_segmento)
F2 = np.random.normal(loc=2.0, scale=0.5, size=n_por_segmento)
elif seg == 2: # ocasionales de bajo valor
F1 = np.random.normal(loc=-2.0, scale=0.5, size=n_por_segmento)
F2 = np.random.normal(loc=-1.2, scale=0.5, size=n_por_segmento)
elif seg == 3: # frecuentes de ticket medio
F1 = np.random.normal(loc=0.8, scale=0.5, size=n_por_segmento)
F2 = np.random.normal(loc=0.8, scale=0.5, size=n_por_segmento)
# Variables observadas como combinaciones lineales de factores latentes
# + poco ruido para mantener correlación
gasto_promedio = 1.3*F1 + 0.2*F2 + np.random.normal(0, 0.25, n_por_segmento)
frecuencia_compra = 1.1*F1 + 0.3*F2 + np.random.normal(0, 0.25, n_por_segmento)
visitas_web = 0.2*F1 + 1.2*F2 + np.random.normal(0, 0.25, n_por_segmento)
uso_descuentos = -0.1*F1 + 1.3*F2 + np.random.normal(0, 0.25, n_por_segmento)
antiguedad = 0.9*F1 - 0.2*F2 + np.random.normal(0, 0.25, n_por_segmento)
fidelidad = 1.0*F1 - 0.3*F2 + np.random.normal(0, 0.25, n_por_segmento)
X_seg = np.column_stack([
gasto_promedio,
frecuencia_compra,
visitas_web,
uso_descuentos,
antiguedad,
fidelidad
])
datos.append(X_seg)
labels.extend([seg] * n_por_segmento)
X = np.vstack(datos)
y = np.array(labels)
columnas = [
"gasto_promedio",
"frecuencia_compra",
"visitas_web",
"uso_descuentos",
"antiguedad",
"fidelidad"
]
df = pd.DataFrame(X, columns=columnas)
df["segmento_real"] = y
print(df.head())
# =========================================================
# 2. Mirar correlaciones entre variables
# =========================================================
corr = df[columnas].corr()
print(corr.round(2))
# =========================================================
# 3. Estandarizar y aplicar PCA
# =========================================================
scaler = StandardScaler()
X_scaled = scaler.fit_transform(df[columnas])
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
explained_ratio = pca.explained_variance_ratio_
explained_var = pca.explained_variance_
components = pca.components_
print("=== Varianza explicada ===")
for i in range(2):
print(f"PC{i+1}:")
print(f" Varianza explicada: {explained_var[i]:.4f}")
print(f" Proporción de varianza explicada: {explained_ratio[i]:.2%}")
print("\nVarianza explicada acumulada:")
print(explained_ratio.cumsum())
# =========================================================
# 4. Loadings
# =========================================================
loadings = pd.DataFrame(
components.T,
index=columnas,
columns=["PC1", "PC2"]
)
print("=== Loadings ===")
print(loadings.round(3))
# =========================================================
# 5. Visualización PCA
# =========================================================
df_pca = pd.DataFrame(X_pca, columns=["PC1", "PC2"])
df_pca["segmento_real"] = y
plt.figure(figsize=(8, 6))
for grupo in sorted(df_pca["segmento_real"].unique()):
datos_g = df_pca[df_pca["segmento_real"] == grupo]
plt.scatter(
datos_g["PC1"],
datos_g["PC2"],
alpha=0.65,
label=f"Segmento {grupo}"
)
plt.xlabel(f"PC1 ({explained_ratio[0]:.1%} var. explicada)")
plt.ylabel(f"PC2 ({explained_ratio[1]:.1%} var. explicada)")
plt.title("PCA de clientes simulados con variables correlacionadas")
plt.legend()
plt.grid(True)
plt.show()

# =========================================================
# 6. Centroides y silhouette
# =========================================================
centroides = df_pca.groupby("segmento_real")[["PC1", "PC2"]].mean()
print("=== Centroides en el espacio PCA ===")
print(centroides.round(3))
sil_score = silhouette_score(df_pca[["PC1", "PC2"]], df_pca["segmento_real"])
print(f"\nSilhouette score en espacio PCA: {sil_score:.4f}")
# recuerda que el silhouette score mide qué tan bien separados están los grupos en el espacio PCA,
# usando las etiquetas reales de segmento. Un valor cercano a 1 indica grupos bien separados,
# mientras que valores cercanos a 0 indican solapamiento.
Interpretación del PCA en el ejemplo de segmentación de clientes¶
En este ejemplo, PCA logra resumir bastante bien la estructura de los datos originales. La primera componente principal, $ PC1 $, explica aproximadamente el $ 65.0% $ de la varianza total, mientras que la segunda componente, $ PC2 $, explica cerca del $ 33.5% $. En conjunto, las dos primeras componentes explican alrededor del $ 98.5% $ de la varianza acumulada. Esto es un resultado muy fuerte: significa que, aunque partimos con 6 variables, casi toda la información relevante puede representarse en solo 2 dimensiones sin perder demasiado contenido.
Interpretación de las componentes¶
A partir de los loadings, podemos interpretar qué representa cada componente.
La componente $ PC1 $ tiene cargas altas y positivas en gasto_promedio, frecuencia_compra, antiguedad y fidelidad, y también una carga positiva menor en visitas_web. Esto sugiere que $ PC1 $ resume algo así como un eje de valor y relación con el cliente. Hacia valores altos de $ PC1 $ encontramos clientes que gastan más, compran con mayor frecuencia, llevan más tiempo en la empresa y muestran mayor fidelidad. Hacia valores bajos de $ PC1 $ encontramos clientes de menor valor y menor vínculo.
La componente $ PC2 $, en cambio, está dominada principalmente por visitas_web y uso_descuentos, con cargas positivas altas, mientras que fidelidad y antiguedad aportan de forma algo negativa. Por eso, $ PC2 $ puede interpretarse como un eje de comportamiento promocional y actividad digital. Los clientes con valores altos en esta componente parecen ser más activos digitalmente y más sensibles a descuentos, mientras que valores más bajos reflejan perfiles menos promocionales o menos digitales.
Separación de segmentos en el plano PCA¶
El gráfico muestra que los segmentos se separan de manera bastante clara en el espacio definido por $ PC1 $ y $ PC2 $. Esto indica que la estructura de los grupos está alineada con las direcciones de mayor varianza de los datos.
- Segmento 2 (verde) aparece muy a la izquierda, con valores bajos de $ PC1 $. Esto sugiere clientes de bajo valor general: menor gasto, menor frecuencia, menor antigüedad y menor fidelidad.
- Segmento 0 (azul) aparece a la derecha pero abajo, es decir, con valores altos de $ PC1 $ y bajos de $ PC2 $. Esto sugiere clientes valiosos y relativamente leales, pero menos orientados a descuentos y menor actividad promocional.
- Segmento 1 (naranjo) aparece arriba, con valores relativamente altos de $ PC2 $. Esto sugiere clientes más intensivos en actividad digital y más sensibles a promociones o descuentos.
- Segmento 3 (rojo) queda en una zona intermedia, lo que sugiere un perfil más mixto o balanceado entre valor del cliente y comportamiento promocional.
Qué nos enseña este ejemplo sobre PCA¶
Este ejemplo ilustra bien una idea clave: PCA no “busca grupos” directamente, como lo haría un método de clustering, sino que busca las direcciones que capturan más variabilidad en los datos. En este caso, ocurre que esas direcciones también ayudan a distinguir segmentos de clientes, lo que hace que la visualización en 2D sea especialmente útil.
También muestra por qué PCA es mucho más informativo cuando trabajamos con varias variables correlacionadas. Aquí, las 6 variables originales pueden resumirse casi por completo en dos ejes interpretables, lo que permite visualizar patrones complejos de forma simple.
Ojo!¶
Una buena separación visual en PCA no siempre ocurrirá. Aquí ocurre porque los segmentos fueron simulados con una estructura latente clara y con correlaciones entre variables. Cuando la máxima varianza del conjunto coincide con diferencias sustantivas entre grupos, PCA puede ser muy útil para exploración y visualización. Pero si la mayor varianza proviene de otra fuente, PCA podría no separar bien los segmentos aunque estos existan.
Conclusión¶
En este caso, PCA logra dos cosas al mismo tiempo: reducir fuertemente la dimensionalidad y producir una representación interpretable del comportamiento de los clientes. $ PC1 $ resume principalmente valor y vínculo con el cliente, mientras que $ PC2 $ resume comportamiento digital y orientación a descuentos. Como ambas componentes juntas explican casi toda la varianza, el gráfico en 2D representa muy bien la estructura de los datos originales.
Reflexión final¶
- PCA es útil para visualizar datasets de muchas dimensiones en 2D o 3D.
- Funciona muy bien en contextos donde hay correlaciones fuertes entre variables.
- No es solo para visualizar: también se usa como preprocesamiento antes de clustering o clasificación.
- Como vimos, en distintos dominios (biología, visión, comercio), PCA reduce complejidad y revela estructura.