Modelos de Machine Learning No-Supervisados¶
Fundamentos de Redes Neuronales para Aprendizaje de Representaciones¶
Dr. Cristian Candia¶
Universidad del Desarrollo (UDD), Chile¶
- Director, Computational Research in Social Sciences Lab
- Faculty, Data Science Institute, School of Engineering
Northwestern University, United States¶
- External Faculty, Northwestern Institute on Complex Systems (NICO), Kellogg School of Management
Founder & CSTO¶
- Capybara. Capybara ayuda a establecimiento educacionales a detectar señales tempranas de bullying, medir convivencia escolar y tomar decisiones basadas en evidencia para prevenir conflictos a tiempo.
Pueden visitar esta version interactiva complementaria del curso: https://rrnn.criss-lab.com/
Notas sobre Redes Neuronales¶
1.1 Fundamentos de Redes Neuronales (Libro ISLP 10.1)¶
Una red neuronal básica aplica una secuencia de transformaciones lineales y no lineales sobre la entrada. En una red de dos capas, podemos escribir:
$$ f(x) = \sigma_2 \!\left(W_2 \, \sigma_1(W_1 x + b_1) + b_2\right) $$La idea clave es que cada capa toma una representación de los datos y la vuelve un poco más útil para la tarea final. Las primeras capas a menudo capturan patrones relativamente simples; las capas más profundas pueden combinarlos en representaciones más abstractas y útiles para la tarea.
Donde:
- $\sigma_1$ y $\sigma_2$ son funciones de activación.
- $W_1, W_2$ y $b_1, b_2$ son parámetros aprendidos durante el entrenamiento.
- $x$ es la entrada y $f(x)$ es la salida del modelo.
Las redes neuronales ajustan sus pesos $\theta$ minimizando una función de pérdida sobre los datos observados:
$$ \mathcal{L}(\theta) = \frac{1}{n} \sum_{i=1}^n \text{loss}(y_i, f_\theta(x_i)) $$Una forma útil de pensar el entrenamiento es:
$$ x \rightarrow \text{forward pass} \rightarrow \hat{y} \rightarrow \mathcal{L}(y,\hat{y}) \rightarrow \text{backpropagation} \rightarrow \text{update} $$¿Qué significa cada parte?¶
- $x$: es la entrada a la red.
- forward pass: la red transforma la entrada capa por capa hasta producir una predicción.
- $\hat{y}$: es la salida predicha por el modelo.
- $\mathcal{L}(y,\hat{y})$: mide qué tan lejos está la predicción $\hat{y}$ del valor real $y$.
- backpropagation: calcula cómo cambia la pérdida respecto a cada parámetro de la red.
- update: ajusta los parámetros usando esa información.
¿Qué se actualiza exactamente?¶
En la etapa de update, lo que se actualiza son los parámetros aprendibles de la red, es decir:
- los pesos $W_1, W_2, \dots$
- los sesgos $b_1, b_2, \dots$
En conjunto, solemos escribir todos esos parámetros como:
$\theta = \{W_1, b_1, W_2, b_2, \dots\}$
¿Qué hace backpropagation antes del update?¶
La etapa de backpropagation calcula los gradientes de la pérdida con respecto a cada parámetro. Por ejemplo:
$\frac{\partial \mathcal{L}}{\partial W_1}, \frac{\partial \mathcal{L}}{\partial b_1}, \frac{\partial \mathcal{L}}{\partial W_2}, \frac{\partial \mathcal{L}}{\partial b_2}$
Estos gradientes indican:
- en qué dirección conviene mover cada parámetro
- y cuánto debería cambiar
¿Cómo ocurre el update?¶
Una regla básica de actualización, usando gradient descent, es:
$W \leftarrow W - \eta \frac{\partial \mathcal{L}}{\partial W}$
$b \leftarrow b - \eta \frac{\partial \mathcal{L}}{\partial b}$
donde $\eta$ es el learning rate o tasa de aprendizaje.
Intuición¶
La lógica es la siguiente:
- si un peso está contribuyendo mucho al error, se corrige más
- si está contribuyendo poco, se corrige menos
- repitiendo este proceso muchas veces, la red aprende
Idea clave¶
La etapa de update no cambia los datos ni las activaciones intermedias:
cambia los pesos y sesgos del modelo para reducir la pérdida en la siguiente iteración.
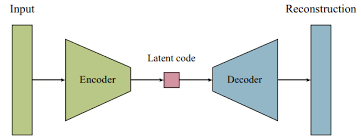
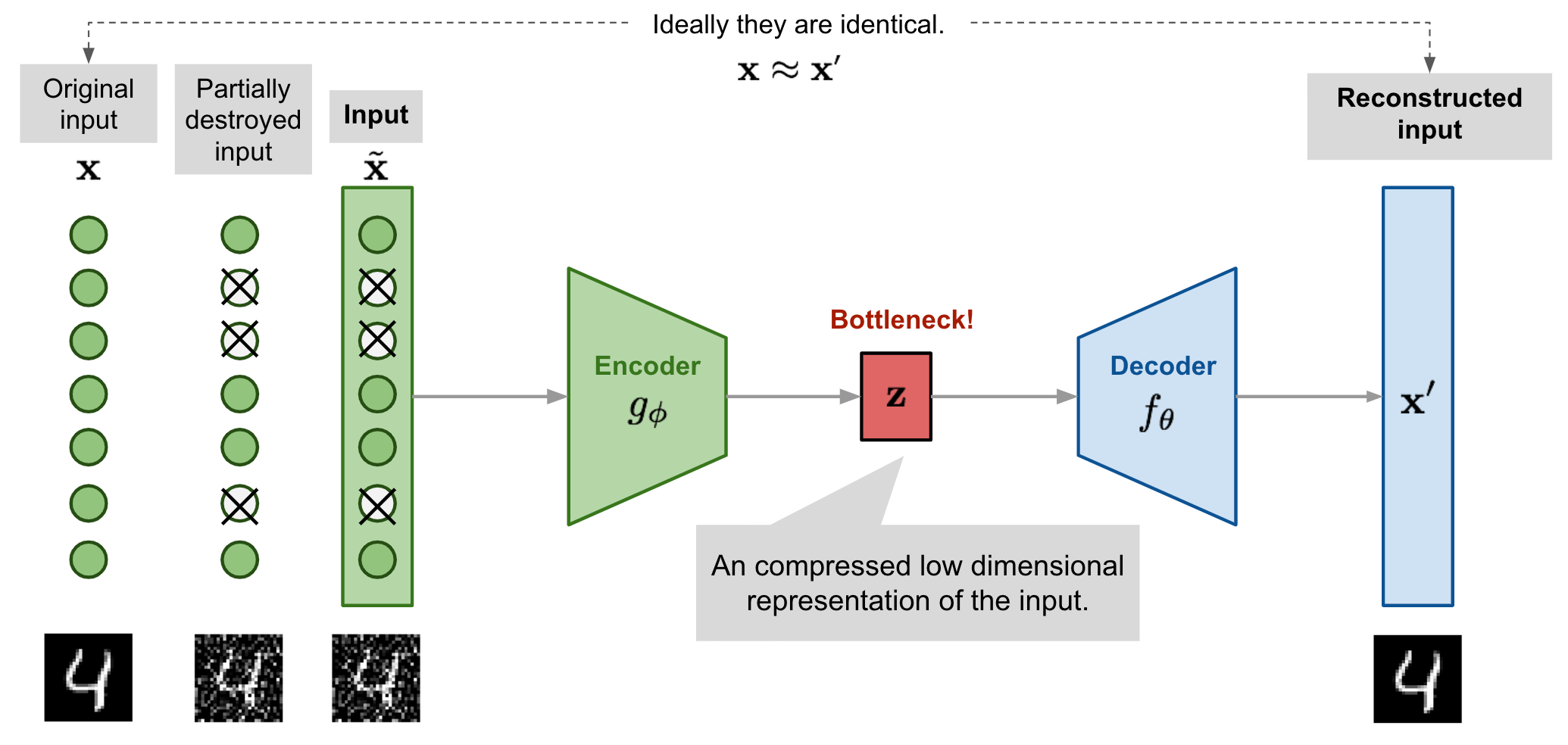
1.2 ¿Qué es un Autoencoder? (Libro DLB Cap. 14)¶
Un autoencoder es una red neuronal que intenta aprender una representación interna de los datos obligándose a reconstruir su propia entrada:
$x \xrightarrow{f_\theta} h \xrightarrow{g_\phi} \hat{x}$
- Encoder: $h = f_\theta(x)$
- Decoder: $\hat{x} = g_\phi(h)$
- Código latente: $h$ es una representación interna o comprimida de $x$
La idea general es simple: la red recibe un dato, lo transforma en una representación intermedia y luego trata de reconstruirlo lo mejor posible. Si esta tarea está bien restringida —por ejemplo, mediante un código latente pequeño, ruido de entrada o regularización— el modelo puede aprender patrones, regularidades y estructura en los datos, en lugar de limitarse a copiar la entrada de manera trivial.
Una pérdida común es el error cuadrático medio:
$\mathcal{L}(x, \hat{x}) = \|x - \hat{x}\|^2$
Sin embargo, la función de pérdida depende del tipo de dato que queremos reconstruir. Para variables continuas suele usarse MSE; para variables binarias o intensidades en $[0,1]$, puede ser más natural usar una salida sigmoidal con una pérdida tipo Bernoulli o binary cross-entropy.
Tipos de autoencoder¶
Un autoencoder no es útil por el mero hecho de reconstruir bien, sino porque la forma en que se le obliga a reconstruir induce una representación interna informativa.
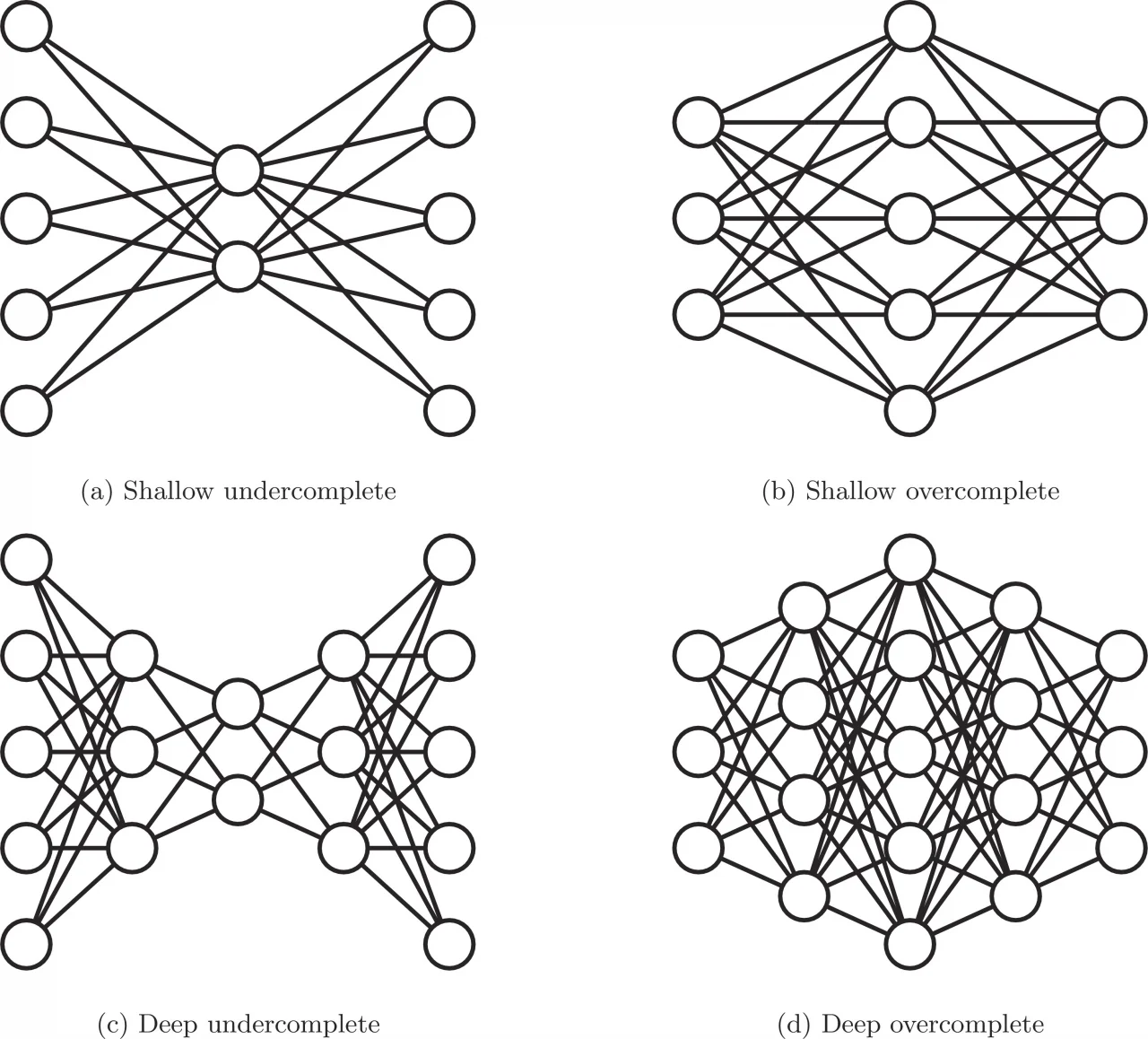
Undercomplete autoencoder¶
En un undercomplete autoencoder, el código latente $h$ tiene menor dimensión que la entrada $x$.
Por ejemplo:
- si $x \in \mathbb{R}^{100}$,
- el modelo podría aprender un código $h \in \mathbb{R}^{10}$
La intuición es que estamos forzando a la red a pasar por un “cuello de botella”. Como no puede guardar toda la información original, debe aprender a conservar solo lo más importante para reconstruir bien la entrada.
Eso obliga al modelo a responder, implícitamente, la siguiente pregunta:
¿Qué parte de la información es realmente esencial y qué parte puede descartarse?
Por eso, este tipo de autoencoder se parece conceptualmente a PCA: ambos buscan una representación más compacta de los datos. La diferencia es que PCA solo aprende transformaciones lineales, mientras que un autoencoder puede aprender transformaciones no lineales.
Overcomplete autoencoder¶
En un overcomplete autoencoder, el código latente $h$ tiene una dimensión igual o incluso mayor que la de la entrada $x$.
Por ejemplo:
- si $x \in \mathbb{R}^{100}$,
- podríamos tener $h \in \mathbb{R}^{150}$
A primera vista, esto parece extraño: si la representación interna es más grande que la entrada, ¿no sería demasiado fácil copiar el dato?
Sí: ese es justamente el riesgo. Si no imponemos ninguna restricción adicional, la red podría aprender una solución trivial: simplemente copiar la entrada en lugar de aprender estructura útil. En ese caso, el autoencoder reconstruye bien, pero no aprende una representación interesante.
Por eso, un overcomplete autoencoder solo tiene sentido si agregamos regularización. La idea es impedir que el modelo use toda su capacidad de manera trivial. Algunas estrategias comunes son:
- sparsity: obligar a que solo unas pocas unidades del código latente se activen
- ruido: corromper la entrada para que no pueda simplemente copiarla
- penalizaciones adicionales: castigar soluciones demasiado simples o poco robustas
La intuición es:
- undercomplete: aprende porque lo obligamos a comprimir
- overcomplete: aprende porque lo restringimos para que no copie
Denoising autoencoder¶
En un denoising autoencoder, no le damos a la red la entrada limpia directamente, sino una versión alterada o corrupta, y le pedimos reconstruir la original.
Es decir, en vez de aprender:
$x \rightarrow x$
aprende algo más desafiante:
$\tilde{x} \rightarrow x$
donde $\tilde{x}$ es una versión ruidosa o incompleta de $x$.
Por ejemplo, podemos:
- agregar ruido gaussiano
- borrar algunas entradas
- perturbar píxeles en una imagen
La intuición es muy importante: si el modelo recibe una entrada dañada y aun así logra reconstruir la señal limpia, entonces no puede estar simplemente copiando. Tiene que aprender patrones más estables y más profundos de los datos.
En otras palabras, el modelo aprende:
- qué variaciones parecen ser solo ruido
- qué estructura permanece aunque la entrada esté perturbada
- qué información es suficientemente robusta como para reconstruir el dato original
Por eso, los denoising autoencoders suelen aprender representaciones más útiles y más robustas que un autoencoder que solo intenta copiar la entrada exacta.
Resumen¶
- Undercomplete: el modelo aprende porque tiene poco espacio y debe comprimir bien.
- Overcomplete: el modelo tiene mucho espacio, así que necesitamos restricciones para evitar que copie.
- Denoising: el modelo aprende a reconstruir la señal verdadera a partir de una versión corrupta, lo que lo obliga a capturar estructura más robusta.
En este notebook primero revisamos las piezas generales de una red neuronal y luego vemos por qué esas mismas piezas permiten construir autoencoders capaces de aprender representaciones útiles de los datos.
Funciones de Activación¶
Las funciones de activación introducen no linealidad en una red neuronal. Sin funciones de activación no lineales, una composición de capas afines sigue siendo una sola transformación afín, por lo que la red pierde capacidad para modelar relaciones no lineales complejas.
Activación en una neurona¶
En una neurona, el forward pass ocurre en dos pasos. Primero se calcula una combinación lineal de entradas, pesos y sesgo:
Luego se aplica una función no lineal para producir la salida activada:
$$ a = \sigma(z) $$- $z$ se llama preactivación.
- $a$ es la activación que se entrega a la siguiente capa.
Esta separación es importante: la parte lineal mezcla información y la parte no lineal le da poder expresivo al modelo.
¿Por qué es tan importante la función de activación?¶
Porque sin activaciones no lineales, una red neuronal profunda colapsa a una sola transformación lineal. Aunque tenga muchas capas, no gana poder real de representación: sigue haciendo algo equivalente a $f(x) = Ax + c$.
La función de activación rompe esa linealidad y permite que la red aprenda relaciones complejas, fronteras de decisión curvas y representaciones internas mucho más ricas. En otras palabras, la profundidad solo aporta valor cuando entre capas introducimos no linealidad.
Propiedades deseables de una buena función de activación¶
1. No linealidad¶
- Permite aprender fronteras de decisión complejas.
- Hace posible separar patrones que una regresión lineal no podría modelar.
Sin no linealidad, una red profunda es solo una regresión lineal disfrazada.
2. Derivabilidad¶
- Las redes se entrenan con backpropagation, que necesita derivadas.
- Si la activación no es derivable, el flujo del gradiente se vuelve problemático.
ReLU no es derivable exactamente en $z = 0$. Sin embargo, esto no genera problemas prácticos importantes, porque la no derivabilidad ocurre solo en un punto y, en entrenamiento, usualmente se maneja mediante una convención o subgradiente en $z=0$.
3. Derivadas bien comportadas¶
- Derivadas muy pequeñas producen desvanecimiento del gradiente: al propagarse hacia atrás, el gradiente se vuelve cada vez más cercano a cero, y las capas iniciales aprenden muy poco o casi nada.
- Derivadas muy grandes pueden generar explosión de gradientes: al propagarse hacia atrás, el gradiente crece demasiado, haciendo que las actualizaciones sean inestables y el entrenamiento se vuelva errático.
- En sigmoid, cuando $|z| \gg 0$, suele ocurrir saturación y la derivada se acerca a 0.
- En ReLU, para $z < 0$, la derivada es 0 y una neurona puede dejar de activarse.
4. Simplicidad computacional¶
- Conviene que sean rápidas de evaluar y fáciles de derivar.
- ReLU es popular justamente porque computa algo muy simple:
max(0, z).
5. Salida centrada en cero¶
- Idealmente, es útil que las activaciones tengan media cercana a $0$.
- Cuando las salidas de una capa están muy sesgadas hacia valores positivos, la señal que recibe la siguiente capa también queda desbalanceada.
- Eso puede hacer que las actualizaciones de los pesos sean menos estables y que el entrenamiento avance con más oscilación.
tanhcumple mejor esta propiedad quesigmoid, porque produce valores entre $-1$ y $1$, mientras quesigmoidproduce valores entre $0$ y $1$.
> Activaciones centradas en cero suelen favorecer una optimización más equilibrada.¶
6. Buen flujo de gradientes¶
- Una buena activación deja pasar información útil hacia adelante y gradientes útiles hacia atrás.
- Esta es una de las razones por las que ReLU y sus variantes dominaron el aprendizaje profundo moderno. La ventaja concreta de ReLU es que, para entradas positivas, su derivada es $1$. Eso evita que el gradiente se haga cada vez más pequeño al atravesar muchas capas, como sí puede ocurrir con activaciones como sigmoid o tanh.
- Gracias a eso, las redes profundas con ReLU suelen entrenarse de manera más estable, más rápida y con menos problemas de desvanecimiento del gradiente.
Nota: Aunque ReLU es lineal en la región positiva, no es lineal en todo su dominio, porque corta todos los valores negativos en $0$. Ese quiebre en $z=0$ introduce la no linealidad que la red necesita para aprender funciones complejas. Además, para valores positivos su derivada es $1$, lo que ayuda a mantener un buen flujo de gradientes y facilita el entrenamiento de redes profundas.
Conexión con backpropagation¶
En backpropagation, el gradiente se va propagando desde la salida hacia las capas anteriores. En ese proceso, la derivada de la función de activación, $\sigma'(z)$, aparece multiplicando la señal de error.
Por eso, si $\sigma'(z)$ es muy pequeña, el gradiente también se achica. Y si esto ocurre repetidamente a través de muchas capas, la señal de aprendizaje se debilita cada vez más.
La consecuencia es que los pesos de las primeras capas cambian muy poco, por lo que la red aprende lentamente o casi no aprende en esas capas.
Intuición¶
Las funciones de activación son las que introducen no linealidad en una red neuronal. Gracias a ellas, la red puede aprender relaciones que una transformación lineal no puede capturar. Un ejemplo clásico es XOR, un problema donde la salida vale $1$ cuando las dos entradas son distintas y vale $0$ cuando son iguales. Ese patrón no puede resolverse con una sola frontera lineal. Sin funciones de activación, incluso una red con muchas capas seguiría comportándose como una transformación lineal. Con activaciones, en cambio, la red puede aprender desde relaciones simples no lineales como XOR hasta tareas mucho más complejas, como reconocimiento de imágenes o generación de texto.
Ejemplo: red con 5 entradas, una capa oculta de 2 neuronas y una salida de 5 neuronas¶
Supongamos que la entrada es:
$x = (x_1, x_2, x_3, x_4, x_5)$
Paso 1: capa oculta¶
La capa oculta tiene 2 neuronas.
Cada una recibe las 5 entradas, pero con pesos y sesgo propios.
Neurona oculta 1¶
Primero calcula la combinación lineal:
$z_1^{(1)} = w_{11}^{(1)}x_1 + w_{12}^{(1)}x_2 + w_{13}^{(1)}x_3 + w_{14}^{(1)}x_4 + w_{15}^{(1)}x_5 + b_1^{(1)}$
Luego aplica la activación:
$h_1 = \sigma(z_1^{(1)})$
Neurona oculta 2¶
Primero calcula:
$z_2^{(1)} = w_{21}^{(1)}x_1 + w_{22}^{(1)}x_2 + w_{23}^{(1)}x_3 + w_{24}^{(1)}x_4 + w_{25}^{(1)}x_5 + b_2^{(1)}$
Luego aplica la activación:
$h_2 = \sigma(z_2^{(1)})$
Entonces, la salida de la capa oculta es:
$h = (h_1, h_2)$
Paso 2: capa de salida con 5 neuronas¶
Ahora cada una de las 5 neuronas de salida recibe como entrada las 2 activaciones ocultas.
Neurona de salida 1¶
$z_1^{(2)} = w_{11}^{(2)}h_1 + w_{12}^{(2)}h_2 + b_1^{(2)}$
$\hat{x}_1 = \sigma_{\text{out}}(z_1^{(2)})$
Neurona de salida 2¶
$z_2^{(2)} = w_{21}^{(2)}h_1 + w_{22}^{(2)}h_2 + b_2^{(2)}$
$\hat{x}_2 = \sigma_{\text{out}}(z_2^{(2)})$
Neurona de salida 3¶
$z_3^{(2)} = w_{31}^{(2)}h_1 + w_{32}^{(2)}h_2 + b_3^{(2)}$
$\hat{x}_3 = \sigma_{\text{out}}(z_3^{(2)})$
Neurona de salida 4¶
$z_4^{(2)} = w_{41}^{(2)}h_1 + w_{42}^{(2)}h_2 + b_4^{(2)}$
$\hat{x}_4 = \sigma_{\text{out}}(z_4^{(2)})$
Neurona de salida 5¶
$z_5^{(2)} = w_{51}^{(2)}h_1 + w_{52}^{(2)}h_2 + b_5^{(2)}$
$\hat{x}_5 = \sigma_{\text{out}}(z_5^{(2)})$
Entonces la salida completa de la red es:
$\hat{x} = (\hat{x}_1, \hat{x}_2, \hat{x}_3, \hat{x}_4, \hat{x}_5)$
Forma matricial¶
Entrada¶
$x = \begin{pmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \\ x_5 \end{pmatrix}$
Capa oculta¶
$z^{(1)} = W^{(1)}x + b^{(1)}$
donde
$W^{(1)} = \begin{pmatrix} w_{11}^{(1)} & w_{12}^{(1)} & w_{13}^{(1)} & w_{14}^{(1)} & w_{15}^{(1)} \\ w_{21}^{(1)} & w_{22}^{(1)} & w_{23}^{(1)} & w_{24}^{(1)} & w_{25}^{(1)} \end{pmatrix}$
y
$b^{(1)} = \begin{pmatrix} b_1^{(1)} \\ b_2^{(1)} \end{pmatrix}$
Entonces:
$h = \sigma(z^{(1)})$
o sea,
$h = \sigma(W^{(1)}x + b^{(1)})$
con $h \in \mathbb{R}^2$
Capa de salida¶
$z^{(2)} = W^{(2)}h + b^{(2)}$
donde
$W^{(2)} = \begin{pmatrix} w_{11}^{(2)} & w_{12}^{(2)} \\ w_{21}^{(2)} & w_{22}^{(2)} \\ w_{31}^{(2)} & w_{32}^{(2)} \\ w_{41}^{(2)} & w_{42}^{(2)} \\ w_{51}^{(2)} & w_{52}^{(2)} \end{pmatrix}$
y
$b^{(2)} = \begin{pmatrix} b_1^{(2)} \\ b_2^{(2)} \\ b_3^{(2)} \\ b_4^{(2)} \\ b_5^{(2)} \end{pmatrix}$
Luego aplicamos la activación de salida:
$\hat{x} = \sigma_{\text{out}}(z^{(2)}) = \sigma_{\text{out}}(W^{(2)}h + b^{(2)})$
con $\hat{x} \in \mathbb{R}^5$
Resumen de dimensiones¶
- Entrada: $x \in \mathbb{R}^5$
- Pesos de la capa oculta: $W^{(1)} \in \mathbb{R}^{2 \times 5}$
- Sesgos de la capa oculta: $b^{(1)} \in \mathbb{R}^2$
- Activaciones ocultas: $h \in \mathbb{R}^2$
- Pesos de salida: $W^{(2)} \in \mathbb{R}^{5 \times 2}$
- Sesgos de salida: $b^{(2)} \in \mathbb{R}^5$
- Salida: $\hat{x} \in \mathbb{R}^5$
Interpretación¶
Cada una de las 2 neuronas ocultas aprende una representación distinta de la entrada original de 5 variables. Luego, la capa de salida usa esas 2 activaciones para reconstruir o producir 5 valores de salida. Esta es justamente la estructura típica de un autoencoder simple con cuello de botella: $5 \rightarrow 2 \rightarrow 5$.
from IPython.display import HTML
from pathlib import Path
html = Path("autoencoder_5_2_5_back.html").read_text(encoding="utf-8")
html_escaped = html.replace("&", "&").replace('"', """)
HTML(f'''
<iframe
srcdoc="{html_escaped}"
width="80%"
height="1180"
style="border:none; border-radius:12px; align-self:center; margin: 20px auto; display: block;">
</iframe>
''')
1. Lineal (Identidad)¶
$$ \sigma(z) = z $$Intuición¶
Es equivalente a no usar activación: la salida es igual a la entrada.
Ventajas¶
- Simplicidad
- Útil en la capa de salida para tareas de regresión
Desventajas¶
- Si se usa en capas ocultas, toda la red sigue siendo lineal
- No permite aprender patrones complejos
Derivada¶
$$ \sigma'(z) = 1 $$2. ReLU (Rectified Linear Unit)¶
$$ \text{ReLU}(z) = \max(0, z) $$Intuición¶
“Si la entrada es negativa, apago la neurona. Si es positiva, dejo pasar la señal tal cual”.
Ventajas¶
- Rápida y eficiente
- No satura en el lado positivo, por lo que los gradientes fluyen mejor
- Introduce sparsity: muchas salidas son cero
Desventajas¶
- Para $z \le 0$ la derivada es 0 y algunas neuronas pueden “morir”
- No está centrada en cero
Derivada¶
$$ \text{ReLU}'(z) = \begin{cases} 1 & \text{si } z > 0 \\ 0 & \text{si } z \le 0 \end{cases} $$3. Sigmoid¶
$$ \sigma(z) = \frac{1}{1 + e^{-z}} $$Intuición¶
Convierte cualquier valor real en un número entre 0 y 1, por lo que resulta natural interpretarla como probabilidad.
Ventajas¶
- Muy útil en clasificación binaria en la capa de salida
- Su salida siempre está acotada
Desventajas¶
- Se satura cuando $z \gg 0$ o $z \ll 0$
- No está centrada en cero
- Favorece el desvanecimiento del gradiente en redes profundas
Derivada¶
$$ \sigma'(z) = \sigma(z)(1 - \sigma(z)) $$4. tanh (Tangente hiperbólica)¶
$$ \tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}} = 2\sigma(2z) - 1 $$Intuición¶
Se parece a sigmoid, pero está centrada en cero, lo que suele ayudar al entrenamiento.
Ventajas¶
- Centrada en cero
- Puede funcionar bien cuando los datos están normalizados
Desventajas¶
- También se satura para valores extremos
- Es más costosa computacionalmente que ReLU
Derivada¶
$$ \tanh'(z) = 1 - \tanh^2(z) $$5. Softmax¶
$$ \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_j e^{z_j}} $$Intuición¶
Toma un vector de scores y lo transforma en una distribución de probabilidad donde las salidas compiten entre sí.
Propiedad clave¶
$$ \sum_i \text{softmax}(z_i) = 1 $$Ventajas¶
- Ideal para clasificación multiclase
- Cada salida puede interpretarse como probabilidad de una clase
Desventajas¶
- Se usa casi siempre solo en la capa de salida
- Puede ser numéricamente inestable si no se normalizan los logits
Comparación visual¶
| Función | Rango | Centrada en 0 | Saturación | Ideal para... |
|---|---|---|---|---|
| Lineal | $(-\infty, \infty)$ | Sí | No | Regresión |
| ReLU | $[0, \infty)$ | No | No en el lado positivo | Capas ocultas |
| Sigmoid | $(0, 1)$ | No | Sí | Salida binaria |
tanh |
$(-1, 1)$ | Sí | Sí | Capas ocultas como alternativa |
| Softmax | $(0, 1)$ (vector) | No aplica | No aplica | Clasificación multiclase |
Conclusión¶
- En capas ocultas, ReLU suele ser la primera opción práctica.
- En la capa de salida, la activación depende de la tarea:
- Regresión: lineal
- Clasificación binaria: sigmoid
- Clasificación multiclase: softmax
No existe una activación universalmente mejor: su valor depende del rol que cumple la capa dentro del modelo.
from IPython.display import HTML
from pathlib import Path
html = Path("autoencoder_5_2_5_back.html").read_text(encoding="utf-8")
html_escaped = html.replace("&", "&").replace('"', """)
HTML(f'''
<iframe
srcdoc="{html_escaped}"
width="80%"
height="1180"
style="border:none; border-radius:12px; align-self:center; margin: 20px auto; display: block;">
</iframe>
''')
import numpy as np
import matplotlib.pyplot as plt
# Funciones de activación
def linear(x):
return x
def relu(x):
return np.maximum(0, x)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def tanh(x):
return np.tanh(x)
def softmax(z):
e_z = np.exp(z - np.max(z, axis=0, keepdims=True)) # estabilidad numérica
return e_z / e_z.sum(axis=0, keepdims=True)
# Rango de valores
x = np.linspace(-3, 3, 400)
# Activaciones estándar
activations = {
"Lineal": linear(x),
"ReLU": relu(x),
"Sigmoid": sigmoid(x),
"Tanh": tanh(x),
}
# Plot activaciones estándar
plt.figure(figsize=(6, 3))
for name, y in activations.items():
plt.plot(x, y, label=name)
plt.title("Funciones de Activación (Lineal, ReLU, Sigmoid, Tanh)")
plt.axhline(0, color='gray', linestyle='--', linewidth=0.5)
plt.axvline(0, color='gray', linestyle='--', linewidth=0.5)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
## Softmax con z = [x, 0.1, 0] para mostrar cómo varía la
# probabilidad de la primera componente con x, mientras
# las otras dos componentes permanecen constantes.
# z es una matriz 3xN donde la primera fila varía con x, y
# las otras dos filas son constantes
z = np.vstack([x, np.zeros_like(x)+.1, np.zeros_like(x)])
s = softmax(z)
plt.figure(figsize=(6, 3))
plt.plot(x, s[0], label='Softmax comp. 1')
plt.plot(x, s[1], label='Softmax comp. 2')
plt.plot(x, s[2], label='Softmax comp. 3')
plt.title("Softmax con z = [x, 0.1, 0]")
plt.xlabel("x")
plt.ylabel("Probabilidad")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()


Cómo leer estas curvas¶
- Lineal no cambia la forma de la señal: por eso no agrega poder expresivo si la usamos en capas ocultas.
- ReLU deja pasar la parte positiva y anula la negativa: eso explica por qué suele entrenar rápido y por qué también puede producir neuronas muertas.
- Sigmoid y tanh se aplanan en los extremos: visualmente ya se ve por qué pueden producir desvanecimiento del gradiente.
- Softmax no actúa sobre un escalar, sino sobre un vector completo: convierte scores en probabilidades relativas que suman 1.
Idea práctica para lo que viene: en autoencoders la activación de salida no se elige por moda, sino por el rango y naturaleza de los datos que queremos reconstruir.
- Si la salida representa variables continuas sin cota clara, suele usarse una salida lineal.
- Si reconstruimos intensidades o variables en $[0,1]$, una salida sigmoid puede tener más sentido.
- Softmax no suele ser la salida natural de un autoencoder básico, porque obliga a que las salidas compitan entre sí en lugar de reconstruirse de manera independiente.
¿Qué es backpropagation?¶
Backpropagation es el algoritmo que permite ajustar los pesos de una red propagando el error desde la salida hacia las capas anteriores.
Conviene pensar el entrenamiento en dos fases:
- Forward pass: la red produce una predicción y calcula la pérdida.
- Backward pass: la red usa derivadas locales para saber cómo debe cambiar cada peso.
Todo se apoya en la regla de la cadena:
$$ \frac{\partial \mathcal{L}}{\partial w} = \frac{\partial \mathcal{L}}{\partial a} \cdot \frac{\partial a}{\partial z} \cdot \frac{\partial z}{\partial w} $$Donde:
- $\mathcal{L}$ es la función de pérdida
- $a = \sigma(z)$ es la salida activada
- $z = w^T x + b$ es la preactivación
- $\frac{\partial a}{\partial z} = \sigma'(z)$ es la derivada de la activación
El truco computacional de backpropagation es que reutiliza resultados intermedios: no recalcula todo desde cero para cada peso, sino que va propagando gradientes capa por capa.
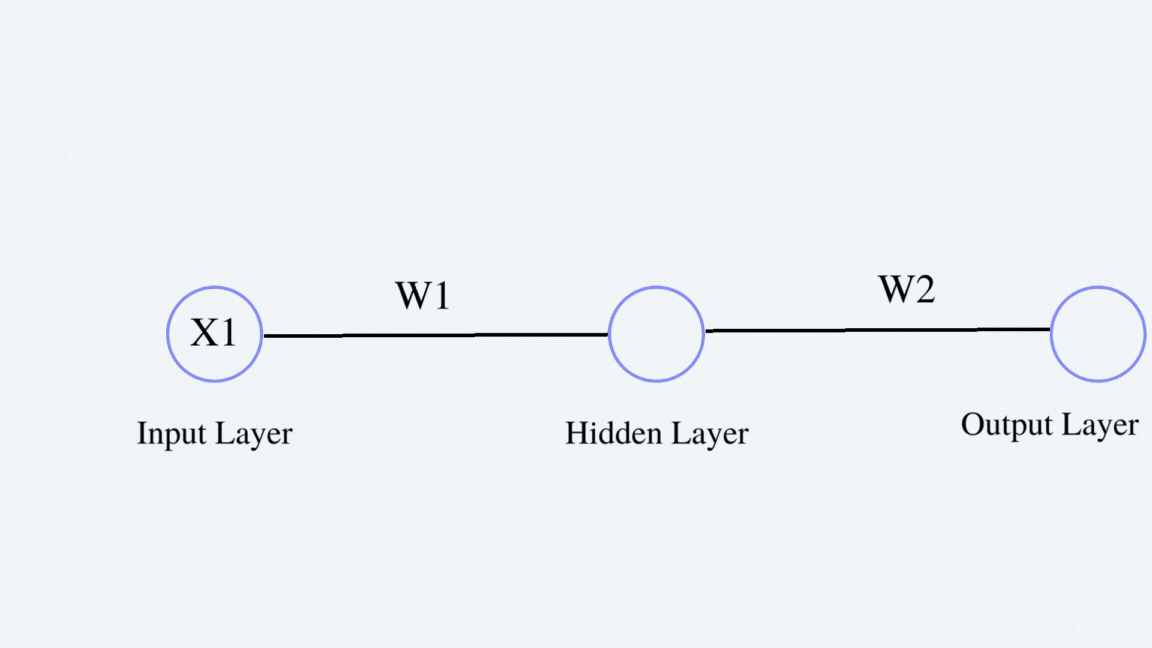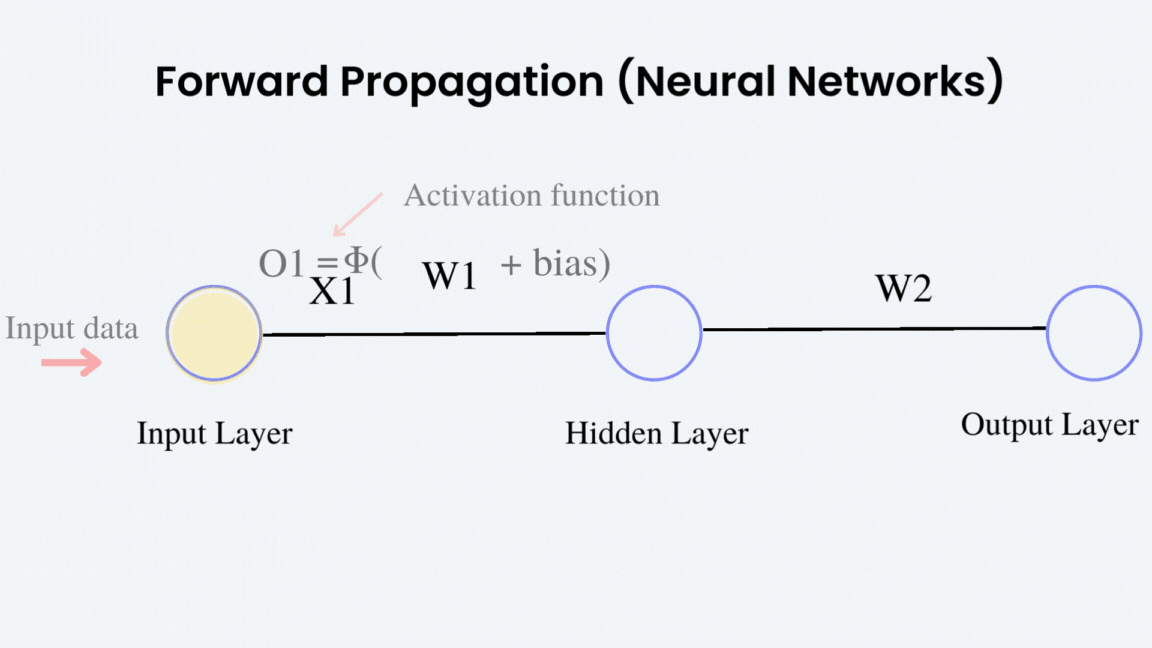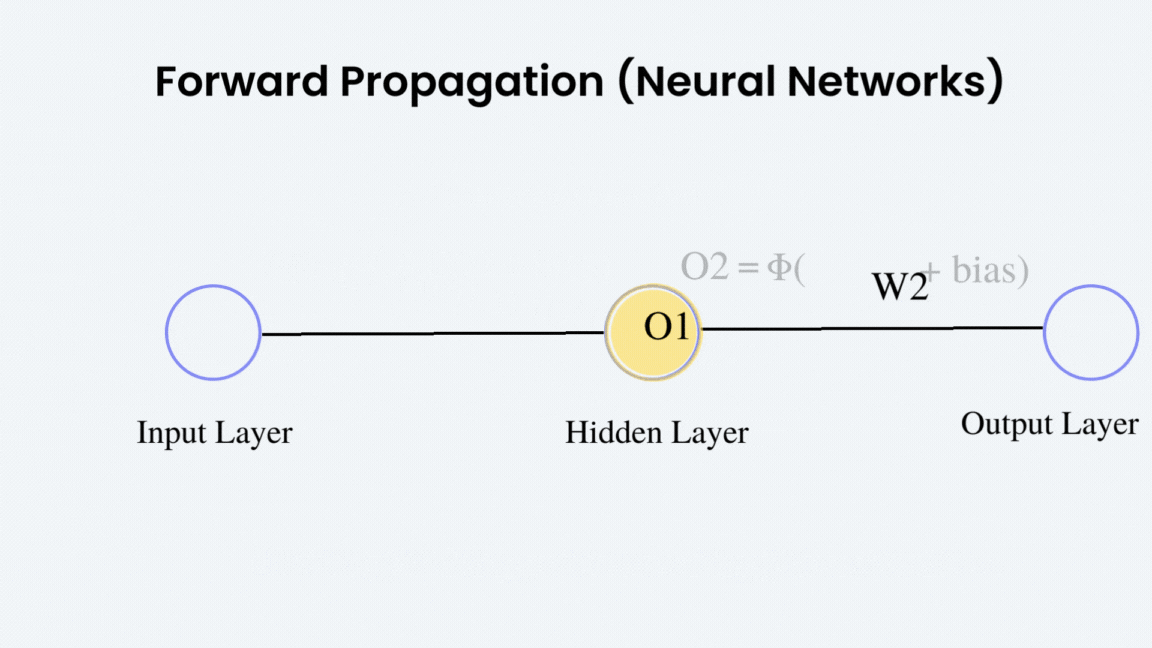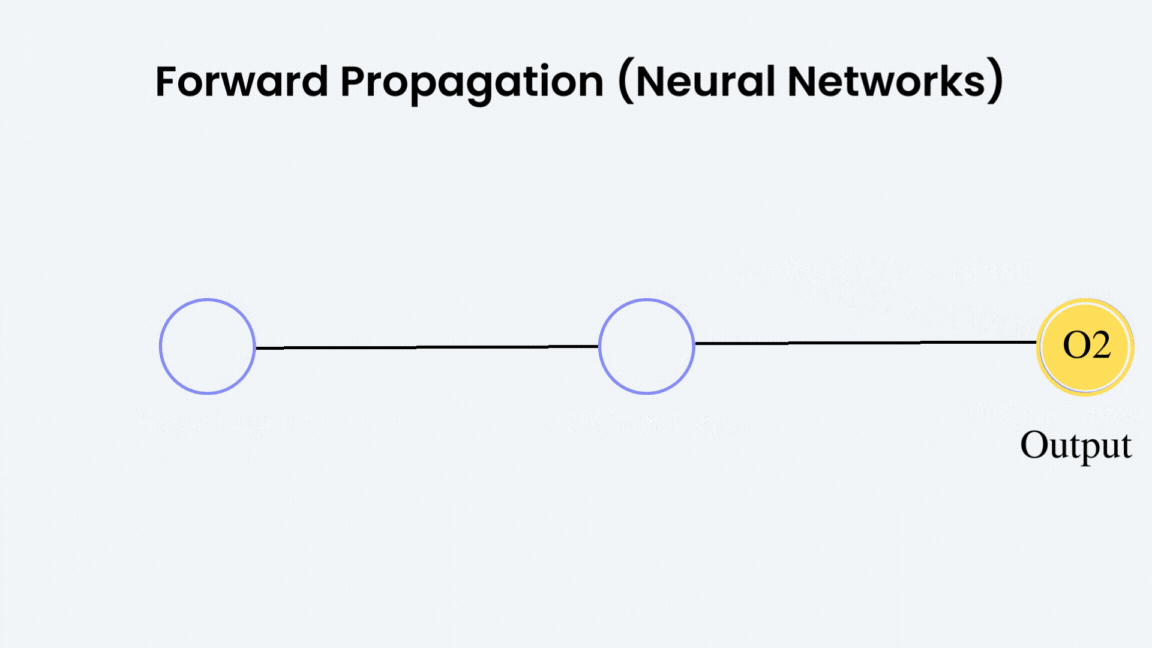
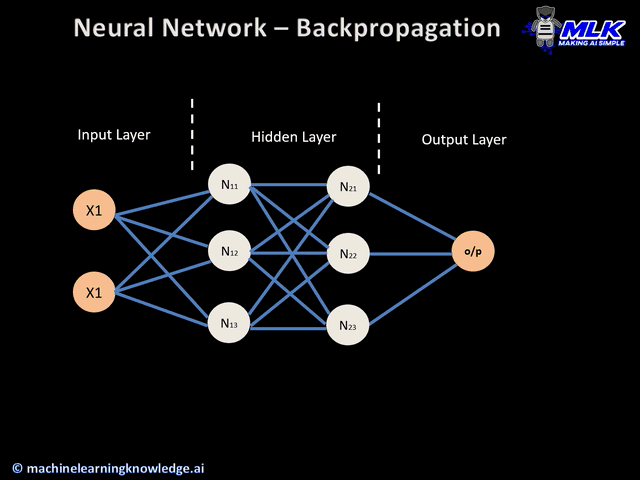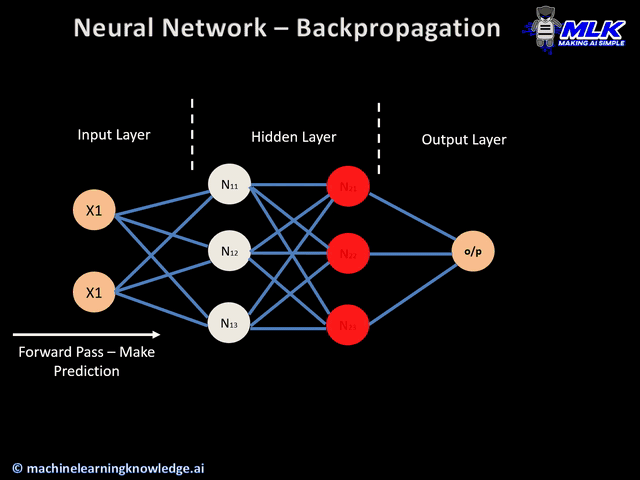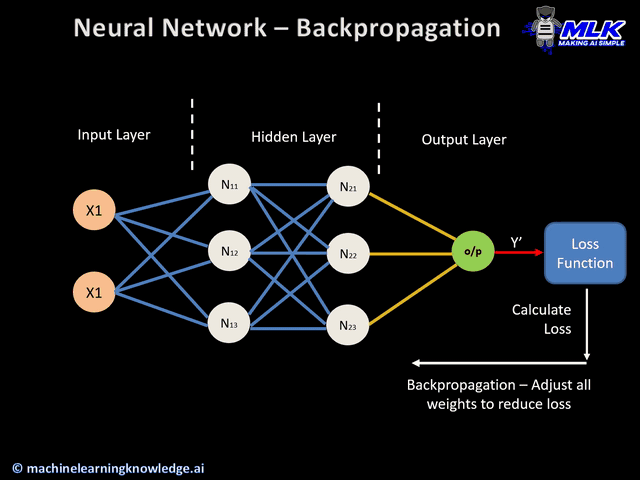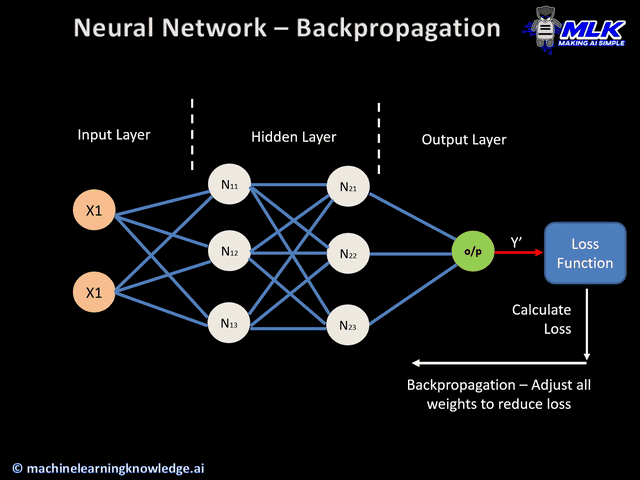
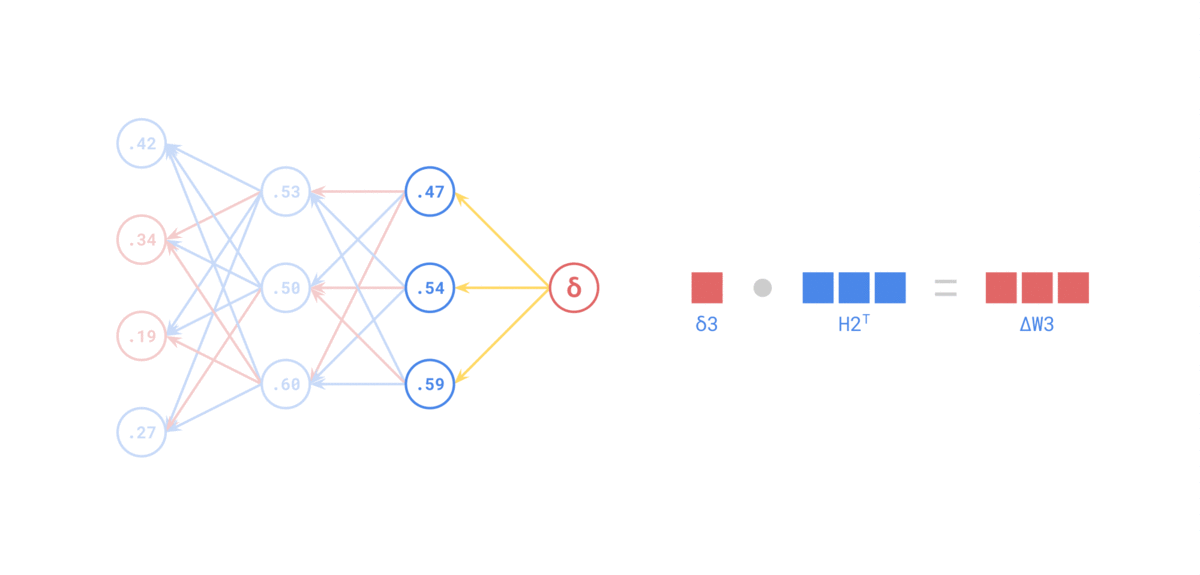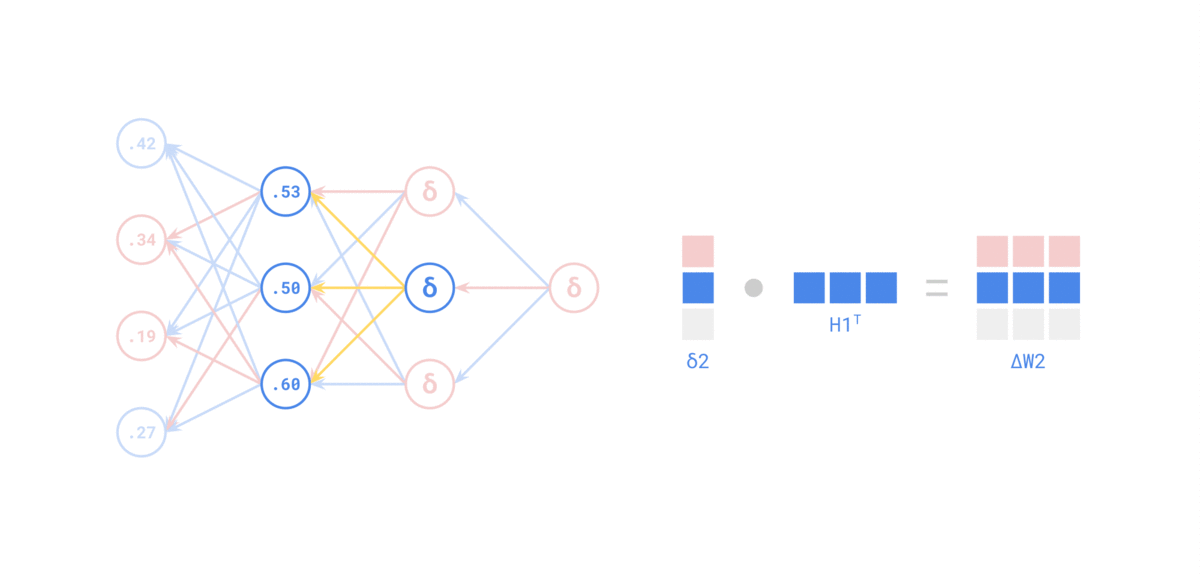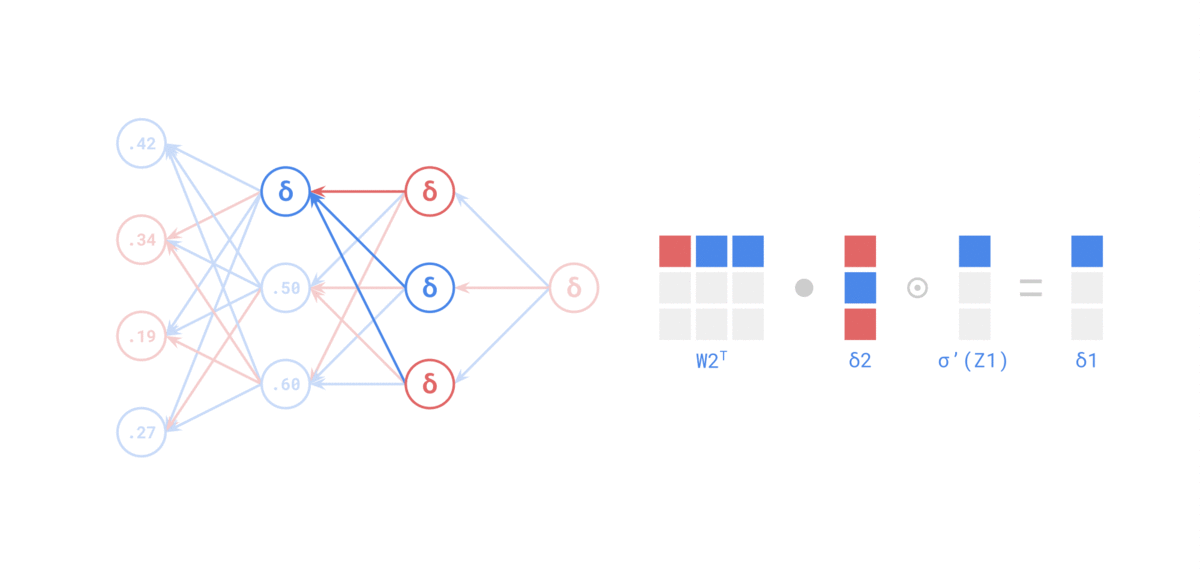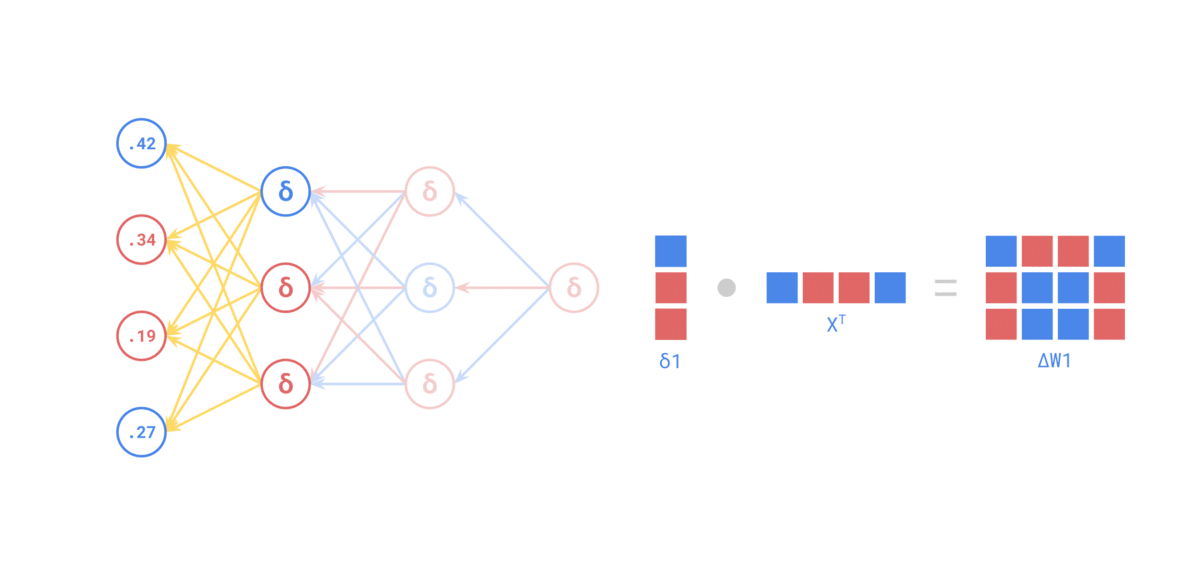
Entonces... ¿por qué necesitamos que la activación sea derivable?¶
1. Porque sin derivada, no podemos propagar el gradiente¶
La red aprende ajustando los pesos con actualizaciones del tipo:
$$ w \leftarrow w - \eta \cdot \frac{\partial \mathcal{L}}{\partial w} $$Si la función de activación no es derivable, no podemos calcular correctamente cómo el error cambia respecto de los pesos anteriores.
2. La activación conecta todo el cálculo de error¶
Cada capa usa la derivada de su activación para retropropagar el error:
$$ \delta^{(l)} = \frac{\partial \mathcal{L}}{\partial a^{(l)}} \cdot \sigma'(z^{(l)}) $$Si $\sigma'$ no existe o vale casi cero en muchos puntos, el aprendizaje se vuelve muy difícil.
3. Si la derivada es 0 o indefinida, el flujo de información se corta¶
- Una función con derivada cero en una región grande puede bloquear el aprendizaje.
- Una función con derivadas muy inestables puede hacer explotar el gradiente.
Ejemplo en contexto¶
Supón una red simple de dos capas:
$$ a^{(1)} = \sigma(w^{(1)} x + b^{(1)}) \quad \rightarrow \quad a^{(2)} = \sigma(w^{(2)} a^{(1)} + b^{(2)}) $$Para actualizar $w^{(1)}$, necesitamos:
$$ \frac{\partial \mathcal{L}}{\partial w^{(1)}} = \frac{\partial \mathcal{L}}{\partial a^{(2)}} \cdot \frac{\partial a^{(2)}}{\partial a^{(1)}} \cdot \frac{\partial a^{(1)}}{\partial w^{(1)}} $$Y eso incluye las derivadas $\sigma'(z^{(2)})$ y $\sigma'(z^{(1)})$. Esa es la esencia de la retropropagación: descomponer un problema grande en derivadas locales fáciles de calcular.
Resumen¶
| Razón | ¿Por qué importa la derivabilidad? |
|---|---|
| Retropropagación | Permite aplicar la regla de la cadena |
| Flujo de gradientes | Hace posible mover el error hacia capas anteriores |
| Evita bloqueos | Sin derivada útil, no hay aprendizaje efectivo |
| Optimización continua | Permite usar métodos de descenso por gradiente |
Sin derivadas, las redes no pueden aprender. El aprendizaje en redes neuronales es, en gran parte, un problema de cálculo diferencial.¶
from IPython.display import HTML
from pathlib import Path
html = Path("autoencoder_5_2_5_back.html").read_text(encoding="utf-8")
html_escaped = html.replace("&", "&").replace('"', """)
HTML(f'''
<iframe
srcdoc="{html_escaped}"
width="80%"
height="1180"
style="border:none; border-radius:12px; align-self:center; margin: 20px auto; display: block;">
</iframe>
''')
¿Cómo se organiza el entrenamiento?¶
Antes de entender SGD y otros optimizadores, conviene aclarar algunos conceptos básicos sobre cómo se recorren los datos durante el entrenamiento de una red neuronal.
Supongamos que tenemos un dataset con muchas observaciones. En teoría, podríamos usar todos los datos al mismo tiempo para calcular el gradiente y actualizar los parámetros. Pero en la práctica eso muchas veces es caro en tiempo y memoria. Por eso el dataset se divide en partes más pequeñas.
Dataset¶
El dataset es el conjunto completo de ejemplos de entrenamiento.
Por ejemplo, si tenemos 10.000 imágenes para entrenar una red, entonces nuestro dataset contiene esas 10.000 observaciones.
Batch¶
Un batch es un conjunto de ejemplos que se procesa juntos en una actualización del modelo.
Si el batch tiene tamaño 32, eso significa que en ese paso la red procesa 32 observaciones, calcula la pérdida promedio en esas 32 observaciones y usa ese resultado para actualizar sus parámetros.
El tamaño del batch se conoce como batch size.
Mini-batch¶
En aprendizaje profundo, casi siempre trabajamos con mini-batches, es decir, batches pequeños comparados con el dataset completo.
Por ejemplo:
- dataset total: 10.000 ejemplos
- mini-batch size: 64
Entonces el modelo no procesa los 10.000 ejemplos de una vez, sino grupos de 64.
A esto se le llama mini-batch training.
Iteración¶
Una iteración es una sola actualización de los parámetros del modelo.
Es decir:
- se toma un mini-batch,
- se hace el forward pass,
- se calcula la pérdida,
- se hace backpropagation,
- se actualizan los parámetros.
Todo eso corresponde a una iteración.
Si el dataset tiene 10.000 ejemplos y usamos batch size 100, entonces una pasada completa por el dataset requiere:
$$ \frac{10000}{100} = 100 $$iteraciones.
Epoch¶
Una epoch corresponde a una pasada completa por todo el dataset de entrenamiento.
Siguiendo el ejemplo anterior:
- dataset: 10.000 ejemplos
- batch size: 100
- iteraciones por epoch: 100
Entonces después de 100 iteraciones, el modelo ha visto una vez todos los datos y ha completado 1 epoch.
Si entrenamos durante 20 epochs, eso significa que el modelo recorrió 20 veces el dataset completo.
Relación entre batch size, iteraciones y epochs¶
Estos conceptos están conectados:
- batch size: cuántos ejemplos se usan en cada actualización
- iteración: una actualización de parámetros
- epoch: una pasada completa por todo el dataset
La relación básica es:
$$ \text{iteraciones por epoch} = \frac{\text{número de observaciones}}{\text{batch size}} $$Si el batch size disminuye:
- cada actualización es más barata,
- pero se necesitan más iteraciones para completar una epoch.
Si el batch size aumenta:
- cada actualización usa más datos,
- pero cada paso es más caro.
Intuición¶
Una epoch dice cuántas veces el modelo ha recorrido todo el dataset. Una iteración dice cuántas veces ya actualizó sus parámetros. El batch size dice cuántos ejemplos usó para decidir cada actualización.
Ejemplo concreto¶
Supongamos que tenemos:
- 12.000 observaciones
- batch size = 300
Entonces:
$$ \text{iteraciones por epoch} = \frac{12000}{300} = 40 $$Eso significa:
- en cada iteración se procesan 300 ejemplos;
- después de 40 iteraciones, el modelo completó 1 epoch;
- después de 10 epochs, habrá realizado 400 iteraciones.
Idea clave¶
El modelo no suele aprender mirando todos los datos a la vez, sino avanzando en pequeños bloques. Esos bloques son los batches, cada actualización es una iteración, y una pasada completa por los datos es una epoch.
Optimizadores en Redes Neuronales¶
Una vez que backpropagation entrega gradientes, el optimizador decide cómo usar esa información para actualizar los parámetros $\theta$ y reducir la pérdida $\mathcal{L}(\theta)$.
Regla de actualización general¶
$$ \theta^{(t+1)} = \theta^{(t)} - \eta \cdot \nabla_{\theta} \mathcal{L}(\theta^{(t)}) $$- $\theta$: vector de parámetros en la iteración $t$
- $\eta$: learning rate o tasa de aprendizaje
- $\nabla_{\theta} \mathcal{L}$: gradiente de la pérdida respecto de los parámetros
¿Qué es un gradiente?¶
El gradiente apunta en la dirección de mayor aumento de la función de pérdida. Por eso, para minimizar, avanzamos en la dirección opuesta.
Idea puente: backpropagation calcula el gradiente; el optimizador decide el tamaño y la forma del paso.
Ejemplo: "Bajando una montaña con los ojos cerrados"¶
Imagina esto:¶
Estás parado en algún punto de una montaña. Pero:
- Estás con los ojos vendados (¡no sabes dónde está el valle!).
- Solo puedes sentir con tus pies hacia dónde la pendiente es más empinada.
- Cada paso que das es en la dirección que baja más.
- Pero para no caerte, haces pasos pequeños.
Objetivo:¶
Llegar al punto más bajo posible (mínimo de la función de pérdida).
¿Qué te ayuda a saber hacia dónde ir?¶
El gradiente es como una brújula:
- Te dice hacia dónde sube más la montaña.
- Por lo tanto, tú caminas en la dirección opuesta: hacia abajo.
¿Qué tan grande es cada paso?¶
Ese es el learning rate $ \eta $:
- Si das pasos muy grandes, podrías pasarte o caer por otro lado.
- Si das pasos muy chiquitos, podrías tardar muchísimo en llegar al valle.
En una red neuronal:¶
- La montaña es la función de pérdida.
- El camino que tomas es el descenso por gradiente.
- Cada paso actualiza los parámetros $ \theta $ de la red.
- La meta es encontrar el punto más bajo posible: donde la red comete el menor error.
Imaginen que estamos en una montaña, con los ojos cerrados. Lo único que sentimos es hacia dónde baja más el suelo. Cada paso que damos es hacia ese lado, pero sin pasarnos. Así, poco a poco, vamos bajando hasta llegar al fondo del valle. Eso mismo hace una red: ajusta sus parámetros para bajar el error, paso a paso, guiada por la pendiente (el gradiente).
Optimizadores: cómo usan el gradiente para aprender¶
Una vez que obtenemos el gradiente mediante backpropagation, todavía falta decidir cómo actualizar los parámetros.
Todos los optimizadores parten de la misma idea general:
$$ \theta \leftarrow \theta - \text{(algo basado en el gradiente)} $$donde:
- $ \theta $ representa los parámetros del modelo,
- el gradiente indica hacia dónde aumenta más la pérdida,
- por eso restamos el gradiente: queremos movernos en dirección contraria para disminuir el error.
La diferencia entre optimizadores está en cómo transforman el gradiente en un paso concreto.
1. SGD (Stochastic Gradient Descent)¶
Idea central¶
SGD usa el gradiente estimado con un mini-batch para actualizar directamente los parámetros.
$$ \theta \leftarrow \theta - \eta \cdot \nabla_{\theta}\mathcal{L}_{\text{mini-batch}} $$¿Qué significa esta ecuación?¶
- $ \theta $: parámetros actuales del modelo.
- $ \eta $: tasa de aprendizaje (learning rate).
- $ \nabla_{\theta}\mathcal{L}_{\text{mini-batch}} $: gradiente de la pérdida calculado con el mini-batch actual.
La lógica es simple:
- calculo el gradiente en el punto actual;
- multiplico por $ \eta $ para controlar el tamaño del paso;
- resto ese valor a los parámetros.
Intuición¶
SGD mira solo la pendiente actual y da un paso en dirección descendente.
Si el gradiente es grande, el paso es grande.
Si el gradiente es pequeño, el paso es pequeño.
Pero todos los parámetros comparten la misma escala global $ \eta $.
Qué limita a SGD¶
- no tiene memoria del pasado;
- no distingue entre coordenadas estables e inestables;
- puede oscilar mucho en ciertas superficies.
Idea para recordar¶
SGD usa solo la información del presente.
2. SGD + Momentum¶
Problema que intenta resolver¶
SGD puro puede avanzar lentamente y oscilar mucho, especialmente en superficies alargadas o con “valles” estrechos.
Momentum agrega una variable auxiliar que acumula parte del movimiento pasado:
$$ v_t = \gamma v_{t-1} + \eta \nabla \mathcal{L}(\theta_t) $$$$ \theta_{t+1} = \theta_t - v_t $$¿Qué significa cada ecuación?¶
Primera ecuación¶
$$ v_t = \gamma v_{t-1} + \eta \nabla \mathcal{L}(\theta_t) $$Aquí:
- $ v_t $ es la velocidad acumulada en el paso $ t $;
- $ v_{t-1} $ es la velocidad del paso anterior;
- $ \gamma $ controla cuánta memoria conservamos del pasado;
- $ \eta \nabla \mathcal{L}(\theta_t) $ es el gradiente actual escalado por la tasa de aprendizaje.
Entonces esta ecuación dice:
la nueva velocidad es una mezcla entre lo que veníamos haciendo y lo que el gradiente actual sugiere hacer.
Segunda ecuación¶
$$ \theta_{t+1} = \theta_t - v_t $$Una vez construida esa velocidad acumulada, actualizamos los parámetros usando $ v_t $ en vez del gradiente puro.
Intuición¶
Momentum no solo pregunta “¿qué dice el gradiente ahora?”,
sino también “¿en qué dirección me he estado moviendo últimamente?”.
Si durante varios pasos el gradiente apunta más o menos en la misma dirección, la velocidad acumulada crece y el avance se acelera.
Si hay pequeñas oscilaciones laterales, la memoria del movimiento ayuda a suavizarlas.
Interpretación física¶
Es como una pelota bajando por una montaña: gana inercia en una dirección consistente y no cambia de rumbo violentamente por pequeñas irregularidades.
Idea para recordar¶
Momentum = gradiente actual + memoria del pasado.
3. RMSprop¶
Problema que intenta resolver¶
No todas las coordenadas del espacio de parámetros se comportan igual.
Algunas pueden recibir gradientes muy grandes, otras muy pequeños.
Si usamos la misma escala para todas, algunas direcciones avanzan demasiado y otras demasiado poco.
RMSprop intenta adaptar el tamaño del paso por parámetro.
Ecuaciones¶
$$ s_t = \rho s_{t-1} + (1-\rho)g_t^2 $$$$ \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{s_t + \epsilon}} \cdot g_t $$¿Qué significa la primera ecuación?¶
$$ s_t = \rho s_{t-1} + (1-\rho)g_t^2 $$Aquí:
- $ g_t $ es el gradiente actual;
- $ g_t^2 $ es el gradiente al cuadrado;
- $ s_t $ es un promedio móvil de la magnitud reciente del gradiente;
- $ \rho $ controla cuánta memoria damos al pasado.
Esta ecuación no promedia la dirección del gradiente, sino su magnitud reciente.
¿Por qué aparece el gradiente al cuadrado?¶
Porque aquí no queremos saber si el gradiente fue positivo o negativo, sino qué tan grande fue.
Si promediáramos $ g_t $ directamente:
- valores positivos y negativos se podrían cancelar;
pero con $ g_t^2 $:
- todos los términos son no negativos;
- medimos intensidad;
- gradientes grandes producen valores grandes en $ s_t $.
¿Qué significa la segunda ecuación?¶
$$ \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{s_t + \epsilon}} \cdot g_t $$Comparada con SGD, aquí el gradiente ya no se multiplica solo por $ \eta $, sino por:
$$ \frac{\eta}{\sqrt{s_t + \epsilon}} $$Eso significa que el tamaño del paso ahora depende de $ s_t $.
- Si $ s_t $ es grande, el divisor crece y el paso se hace más pequeño.
- Si $ s_t $ es pequeño, el divisor es menor y el paso efectivo es más grande.
Entonces RMSprop hace esto:
frena en coordenadas que vienen recibiendo gradientes grandes,
y permite avanzar más en coordenadas donde los gradientes han sido pequeños.
Intuición¶
RMSprop regula la velocidad de cada parámetro por separado.
Idea para recordar¶
RMSprop no recuerda hacia dónde ibas,
pero sí recuerda qué tan brusco ha sido el terreno en cada coordenada.
4. Adam (Adaptive Moment Estimation)¶
Idea central¶
Adam combina dos ideas:
- Momentum: acumular dirección promedio;
- RMSprop: adaptar el tamaño del paso por parámetro.
Por eso usa dos promedios móviles.
Paso 1: promedio de dirección¶
$$ m_t = \beta_1 m_{t-1} + (1-\beta_1)g_t $$Aquí:
- $ m_t $ es el primer momento;
- resume la dirección promedio reciente del gradiente;
- cumple un rol análogo a la memoria direccional de Momentum.
Esta ecuación dice:
Adam guarda una versión suavizada del gradiente.
Paso 2: promedio de magnitud¶
$$ v_t = \beta_2 v_{t-1} + (1-\beta_2)g_t^2 $$Aquí:
- $ v_t $ es el segundo momento;
- resume la magnitud reciente del gradiente;
- cumple un rol parecido a RMSprop.
Esta ecuación dice:
Adam también estima qué tan grandes han sido los gradientes recientemente.
Paso 3: corrección de sesgo¶
Como al principio se usa $ m_0 = 0 $ y $ v_0 = 0 $, los primeros valores de $ m_t $ y $ v_t $ quedan sesgados hacia abajo.
Por eso Adam corrige:
$$ \hat{m}_t = \frac{m_t}{1-\beta_1^t} \qquad \hat{v}_t = \frac{v_t}{1-\beta_2^t} $$¿Qué hace esta corrección?¶
En los primeros pasos, como todavía no hay suficiente historia acumulada, los promedios móviles serían artificialmente pequeños.
La corrección compensa ese “arranque en frío”.
Paso 4: actualización final¶
$$ \theta_t = \theta_{t-1} - \eta \cdot \frac{\hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon} $$¿Cómo se interpreta esta ecuación?¶
Esta expresión combina dos piezas:
Numerador: $ \hat{m}_t $¶
Da la dirección promedio corregida.
Esto le da a Adam memoria direccional.
Denominador: $ \sqrt{\hat{v}_t}+\epsilon $¶
Controla la escala del paso.
Si una coordenada ha tenido gradientes grandes recientemente, el denominador crece y el paso se reduce.
Entonces Adam hace ambas cosas a la vez:
- usa memoria para decidir hacia dónde moverse;
- adapta el tamaño del paso según la variabilidad reciente.
Intuición¶
Adam intenta responder dos preguntas al mismo tiempo:
- ¿hacia dónde conviene moverme?
- ¿qué tan grande debería ser ese movimiento?
Idea para recordar¶
Adam = Momentum + RMSprop + corrección de sesgo inicial.
Comparación conceptual¶
SGD¶
Usa solo el gradiente actual.
$$ \theta \leftarrow \theta - \eta g_t $$Pregunta implícita:
“¿Qué dice la pendiente ahora?”
Momentum¶
Usa el gradiente actual y además acumula dirección pasada.
$$ v_t = \gamma v_{t-1} + \eta g_t \qquad \theta_{t+1} = \theta_t - v_t $$Pregunta implícita:
“¿Qué dice la pendiente ahora y hacia dónde venía moviéndome?”
RMSprop¶
Usa el gradiente actual, pero adapta la escala del paso por parámetro.
$$ s_t = \rho s_{t-1} + (1-\rho)g_t^2 \qquad \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{s_t+\epsilon}}g_t $$Pregunta implícita:
“¿Qué tan grande debería ser el paso en esta coordenada?”
Adam¶
Combina dirección promedio y escala adaptativa.
$$ m_t = \beta_1 m_{t-1} + (1-\beta_1)g_t $$$$ v_t = \beta_2 v_{t-1} + (1-\beta_2)g_t^2 $$$$ \theta_t = \theta_{t-1} - \eta \cdot \frac{\hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon} $$Pregunta implícita:
“¿Hacia dónde debería moverme y qué tan grande debería ser ese movimiento?”
Resumen rápido¶
| Optimizador | Qué recuerda | Qué adapta | Idea breve |
|---|---|---|---|
| SGD | Nada | Nada | Sigue el gradiente actual |
| Momentum | Dirección pasada | No | Acumula inercia |
| RMSprop | Magnitud reciente | Sí, por parámetro | Ajusta la velocidad local |
| Adam | Dirección y magnitud | Sí, por parámetro | Combina inercia y adaptación |
Take away¶
Todos usan gradientes.
Lo que cambia es cómo convierten ese gradiente en movimiento:
con memoria, con adaptación local, o con ambas cosas a la vez.
from IPython.display import HTML
from pathlib import Path
html = Path("optimizer_simulator_fit.html").read_text(encoding="utf-8")
html_escaped = html.replace("&", "&").replace('"', """)
HTML(f'''
<iframe
srcdoc="{html_escaped}"
width="100%"
height="980"
style="border:none; border-radius:12px;">
</iframe>
''')
import numpy as np
import plotly.graph_objects as go
# Función de pérdida
def loss_function(x, y):
return np.log(x**2 + y**2 + 1)
# Malla del terreno
x = np.linspace(-2, 2, 100)
y = np.linspace(-2, 2, 100)
X, Y = np.meshgrid(x, y)
Z = loss_function(X, Y)
# Trayectorias simuladas
adam_path = np.array([[-1.5, -1.5], [-1.2, -1.2], [-0.8, -0.9], [-0.4, -0.5], [-0.1, -0.2], [0, 0]])
sgd_path = np.array([[-1.5, -1.5], [-1.4, -1.3], [-1.3, -1.2], [-1.1, -1.0], [-0.9, -0.8], [-0.5, -0.6]])
adam_z = loss_function(adam_path[:, 0], adam_path[:, 1])
sgd_z = loss_function(sgd_path[:, 0], sgd_path[:, 1])
# Crear fotogramas de animación
frames = []
for i in range(1, len(adam_path) + 1):
frames.append(go.Frame(
data=[
go.Surface(x=X, y=Y, z=Z, colorscale='Viridis', opacity=0.8, showscale=False),
go.Scatter3d(x=adam_path[:i, 0], y=adam_path[:i, 1], z=adam_z[:i],
mode='lines+markers', line=dict(color='red', width=5),
marker=dict(size=5), name='Adam'),
go.Scatter3d(x=sgd_path[:i, 0], y=sgd_path[:i, 1], z=sgd_z[:i],
mode='lines+markers', line=dict(color='blue', width=5),
marker=dict(size=5), name='SGD')
],
name=f"frame{i}"
))
# Figura base
fig = go.Figure(
data=[
go.Surface(x=X, y=Y, z=Z, colorscale='Viridis', opacity=0.8, showscale=False),
go.Scatter3d(x=[], y=[], z=[], mode='lines+markers', line=dict(color='red'), name='Adam'),
go.Scatter3d(x=[], y=[], z=[], mode='lines+markers', line=dict(color='blue'), name='SGD')
],
frames=frames
)
# Layout de animación
fig.update_layout(
title="Animación de Trayectoria: Adam vs SGD",
scene=dict(xaxis_title='x', yaxis_title='y', zaxis_title='Pérdida'),
updatemenus=[dict(type='buttons',
showactive=False,
buttons=[dict(label='Play',
method='animate',
args=[None, {"frame": {"duration": 600, "redraw": True},
"fromcurrent": True}])])]
)
fig.show()
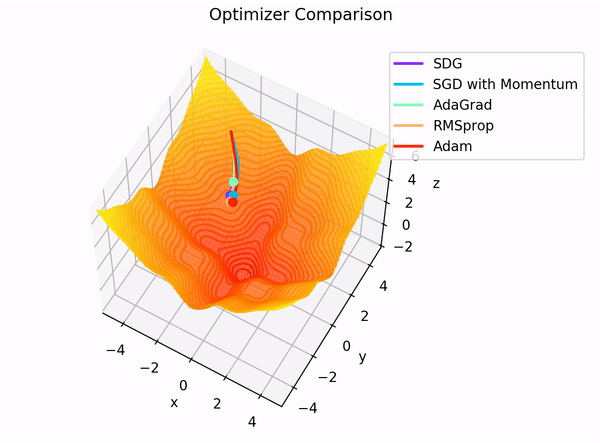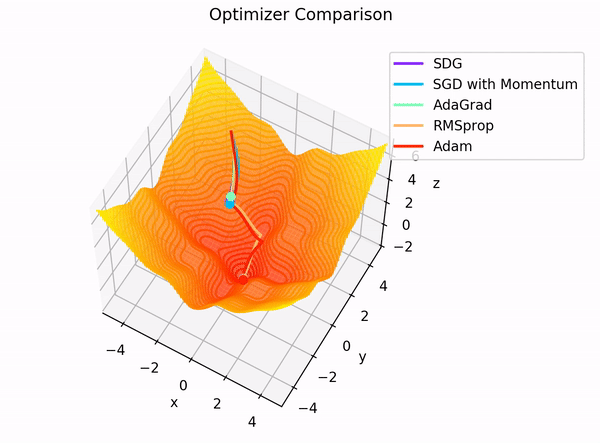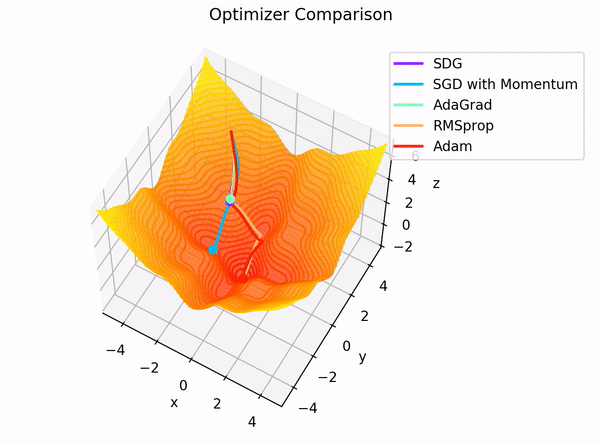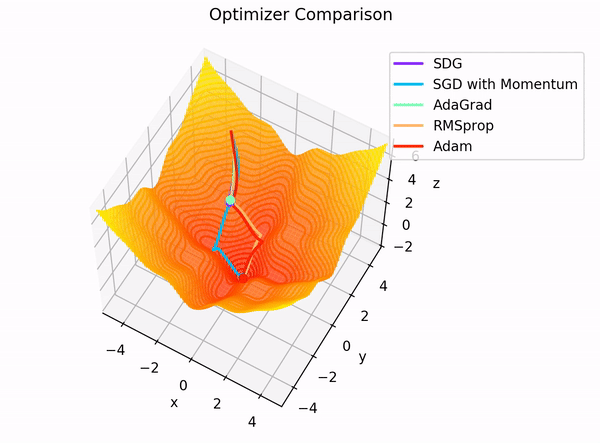
Elección práctica¶
| Optimizador | Cuándo usarlo |
|---|---|
| SGD | Cuando quieres simplicidad y buena generalización con suficiente tiempo de entrenamiento |
| SGD + Momentum | Cuando buscas una opción sólida para redes profundas y trayectorias largas |
| RMSprop | Cuando el problema es secuencial o los gradientes cambian mucho entre pasos |
| Adam | Cuando necesitas un punto de partida robusto y efectivo en la práctica |
Regla rápida de decisión¶
- Si no sabes por dónde empezar, prueba Adam.
- Si te importa mucho la generalización final y puedes entrenar más tiempo, prueba SGD + Momentum.
- Si trabajas con secuencias o gradientes muy variables, RMSprop puede ser una buena alternativa.
Intuición visual¶
Las activaciones moldean el terreno. La función de pérdida define a dónde queremos llegar. El optimizador decide cómo moverse por ese terreno.
Distintos optimizadores generan trayectorias distintas:
- SGD avanza con zigzag
- Momentum gana inercia
- RMSprop adapta la velocidad por coordenada
- Adam combina dirección e intensidad del paso
Cómo entran los datos a la capa input?¶
from IPython.display import HTML
from pathlib import Path
import html
raw = Path("codificacion_capa_input.html").read_text(encoding="utf-8")
if "<head>" in raw:
raw = raw.replace("<head>", '<head><base target="_blank">', 1)
escaped = html.escape(raw, quote=True)
HTML(f"""
<iframe
srcdoc="{escaped}"
width="100%"
height="980"
sandbox="allow-scripts allow-same-origin allow-popups allow-popups-to-escape-sandbox allow-top-navigation-by-user-activation"
style="border:none; border-radius:12px;">
</iframe>
""")
De una Red Neuronal a un Autoencoder¶
Ahora ya tenemos casi todas las piezas que necesitaremos en el siguiente notebook. Un autoencoder no es otro tipo de entrenamiento: sigue siendo una red neuronal entrenada con forward pass, backpropagation y un optimizador.
La diferencia central está en la tarea.
- En una red supervisada clásica, la red aprende a mapear $x \mapsto y$.
- En un autoencoder, la red aprende a mapear $x \mapsto \hat{x}$, es decir, intenta reconstruir su propia entrada.
¿Qué se mantiene?¶
- Seguimos teniendo capas lineales más activaciones no lineales.
- Seguimos haciendo un forward pass para obtener una salida.
- Seguimos calculando una pérdida.
- Seguimos usando backpropagation para obtener gradientes.
- Seguimos actualizando parámetros con SGD, Adam u otro optimizador.
En otras palabras: la mecánica de entrenamiento no cambia.
¿Qué cambia?¶
Lo que cambia es la forma de escribir el problema:
$$ h = f_{\theta}(x), \quad \hat{x} = g_{\phi}(h) $$y la pérdida ahora compara la entrada con su reconstrucción:
$$ \mathcal{L}_{\text{rec}}(x, \hat{x}) $$- $f_{\theta}$ es el encoder.
- $g_{\phi}$ es el decoder.
- $h$ es la representación latente o código.
En un problema supervisado, la pregunta es “¿predije bien la etiqueta?”. En un autoencoder, la pregunta es “¿reconstruí bien la entrada?”.
Ejemplo concreto de dimensiones¶
Supón que la entrada es una imagen de $28 \times 28$ píxeles aplanada en un vector:
$$ x \in \mathbb{R}^{784} $$Un autoencoder simple podría verse así:
$$ 784 \rightarrow 128 \rightarrow 32 \rightarrow 128 \rightarrow 784 $$- La parte izquierda comprime la información.
- El vector de dimensión 32 es el bottleneck o espacio latente.
- La parte derecha intenta reconstruir la señal original a partir de ese código.
Si el cuello de botella obliga a comprimir información relevante, el modelo no puede memorizar trivialmente cada detalle de la entrada y debe aprender estructura útil.
Tener en mente¶
- Si la dimensión latente es mucho menor que la de entrada, hablamos de un autoencoder undercomplete.
- Si la dimensión latente es igual o mayor, el modelo puede aprender una copia casi trivial de la entrada si no agregamos restricciones.
- Por eso el tamaño del espacio latente y la regularización importan tanto.
Esta es una de las razones por las que más adelante veremos variantes como denoising, sparse o variational autoencoders.
Resumen¶
Para pasar de redes neuronales básicas a autoencoders no necesitamos una nueva teoría de entrenamiento. Necesitamos reutilizar lo ya visto y cambiar el objetivo: comprimir y reconstruir bien los datos.
Cuando construyamos un autoencoder, una de las decisiones más importantes será cómo definir la capa de salida y la pérdida de reconstrucción. Esa elección depende del tipo de dato que queremos reconstruir.
| Tipo de dato de salida | Activación de salida sugerida | Pérdida típica | Comentario |
|---|---|---|---|
| Variables continuas sin cota clara | Lineal | MSE | Buena opción si los datos fueron estandarizados |
| Variables o pixeles en $[0,1]$ | Sigmoid | BCE o MSE | Útil cuando interpretamos la salida como intensidad o probabilidad |
| Variables acotadas en $[-1,1]$ | tanh |
MSE | Solo tiene sentido si los datos fueron llevados a ese rango |
| Categorías mutuamente excluyentes | Softmax | Cross-entropy | Caso especial; no suele ser la salida básica de un autoencoder denso estándar |
Punto importante: en autoencoders básicos, softmax no suele ser la salida natural, porque obliga a que las dimensiones compitan entre sí. Para reconstrucción de vectores o imágenes, normalmente queremos que cada componente pueda reconstruirse con más independencia.
Checklist antes de construir un autoencoder¶
- Definir claramente la dimensión de entrada $d$.
- Elegir una dimensión latente $k$ y decidir si queremos un modelo undercomplete o overcomplete.
- Escoger la activación de salida según el rango de los datos, no por costumbre.
- Elegir una pérdida de reconstrucción coherente con ese rango.
- Elegir un optimizador razonable; en la práctica, Adam suele ser una buena primera prueba.
- Si el modelo es overcomplete, pensar desde el inicio qué mecanismo impedirá que aprenda una identidad trivial.
¿Por qué se dice que Machine Learning es una “caja negra”?¶
Ahora que ya vimos activaciones, backpropagation y optimizadores, podemos precisar mejor esta idea. En redes neuronales hablamos de “caja negra” no porque el modelo sea invisible, sino porque ver sus componentes no equivale a entender su razonamiento.
Podemos inspeccionar pesos, gradientes, activaciones y salidas intermedias. Lo difícil es traducir todo eso a una explicación humana simple y estable.
¿Qué entra y qué sale?¶
- Entrada (input): datos crudos, como imágenes, texto, audio o vectores numéricos.
- Salida (output): una predicción, una clasificación, una probabilidad o una reconstrucción.
Entre esos extremos puede haber miles, millones o incluso billones de parámetros. Cada parámetro participa en el cálculo, pero rara vez tiene un significado interpretable por sí solo.
En un programa tradicional podemos leer reglas explícitas. En una red neuronal, la “regla” está distribuida en muchos parámetros a la vez.
¿Por qué esta discusión aparece justo después de backpropagation?¶
Porque backpropagation da una falsa sensación de transparencia si no somos cuidadosos.
Cuando hacemos backpropagation sí entendemos:
- cómo cambia la pérdida si perturbamos un peso,
- qué dirección local reduce el error,
- y cómo entrenar el modelo de manera eficiente.
Pero eso no responde automáticamente preguntas como:
- ¿qué concepto semántico aprendió esta neurona?,
- ¿por qué esta combinación interna representa “gato”, “anomalía” o “rostro”?,
- ¿qué estrategia global está usando la red para resolver la tarea?
En otras palabras: backpropagation explica cómo ajustar el modelo, no necesariamente cómo interpretarlo.
¿Entrenar la red significa entenderla?¶
No. Entrenar una red significa encontrar parámetros que reduzcan una pérdida. Entender una red significa poder dar una explicación legible y relativamente estable de sus representaciones y decisiones.
Lo que sí vemos con backpropagation¶
- Qué parámetros son sensibles al error.
- Qué dirección de cambio mejora la predicción o reconstrucción.
- Qué partes del cálculo contribuyen más a reducir la pérdida localmente.
Lo que no vemos directamente¶
- Qué concepto humano representa cada peso.
- Qué patrón global sintetiza una capa completa.
- Qué tan robusta o frágil es la explicación frente a pequeñas perturbaciones.
¿Qué hace que una red sea difícil de interpretar?¶
1. Representaciones distribuidas¶
La información rara vez vive en una sola neurona. Normalmente está repartida entre muchas unidades al mismo tiempo.
2. Composición de muchas capas¶
Cada capa transforma la representación anterior. Después de varias composiciones no lineales, la relación entre entrada y salida deja de ser intuitiva para una lectura humana directa.
3. Explicaciones locales versus globales¶
Un gradiente nos dice qué pasa cerca de un punto. Pero una explicación global del comportamiento del modelo es mucho más difícil.
4. No hay una semántica garantizada¶
Dos redes entrenadas para la misma tarea pueden llegar a soluciones internas distintas y tener desempeños similares. Eso sugiere que la interpretación no está fijada de manera única.
Ejemplo: clasificador de imágenes¶
- Le mostramos al modelo una imagen de un gato.
- El modelo responde “gato”.
- Podemos calcular gradientes, activaciones o mapas de sensibilidad.
- Pero aun así puede seguir siendo difícil explicar con precisión:
- qué zonas de la imagen fueron realmente decisivas,
- qué patrones visuales aprendió,
- y cómo combinó esos patrones para llegar a la decisión final.
Sabemos que funciona, pero no necesariamente sabemos cómo piensa.
¿Y qué pasa con autoencoders?¶
En autoencoders esta discusión sigue siendo relevante, incluso cuando tenemos acceso al espacio latente $h$.
- Podemos visualizar el código latente.
- Podemos interpolar entre puntos latentes.
- Podemos usar ese espacio para clustering o reducción de dimensionalidad.
Pero tener acceso al espacio latente no implica que cada dimensión tenga una interpretación humana clara. En muchos casos, el modelo aprende una representación útil para reconstruir, no una representación diseñada para ser semánticamente transparente.
Eso cambia en parte cuando imponemos estructura adicional, por ejemplo con regularización, sparsity o modelos variacionales. Aun así, la interpretabilidad nunca viene “gratis”.
Entonces… ¿la caja negra está completamente cerrada?¶
No. Existen herramientas para abrirla parcialmente:
- mapas de activación o saliency maps,
- visualización de filtros y neuronas,
- análisis del espacio latente,
- métodos como LIME, SHAP o probing,
- estudios de ablación y sensibilidad.
Estas herramientas ayudan, pero normalmente entregan aproximaciones o explicaciones parciales, no una lectura completa y definitiva del modelo.
Conclusión¶
El aprendizaje automático no es una caja negra porque no podamos mirar dentro, sino porque interpretar de manera humana, simple y estable lo que ocurre dentro sigue siendo difícil.
Backpropagation nos da el mecanismo de aprendizaje. La interpretabilidad intenta darnos el mecanismo de explicación. Son problemas relacionados, pero no son lo mismo.
Ejemplo ilustrativo en inglés: https://medium.com/the-feynman-journal/what-makes-backpropagation-so-elegant-657f3afbbd