Autoencoders Variacionales¶
Modelos de Machine Learning No-Supervisados¶
Dr. Cristian Candia¶
Universidad del Desarrollo (UDD), Chile¶
- Director, Computational Research in Social Sciences Lab
- Faculty, Data Science Institute, School of Engineering
Northwestern University, United States¶
- External Faculty, Northwestern Institute on Complex Systems (NICO), Kellogg School of Management
Founder & CSTO¶
- Capybara. Capybara ayuda a establecimiento educacionales a detectar señales tempranas de bullying, medir convivencia escolar y tomar decisiones basadas en evidencia para prevenir conflictos a tiempo.
De Autoencoders a Autoencoders Variacionales¶
El notebook 3.1 cerró con una pregunta natural: un autoencoder clásico aprende una función determinista $h=f_\theta(x)$ y un decoder $g_\phi(h)$ que intenta reconstruir $x$. Esa arquitectura sirve para compresión, reconstrucción y aprendizaje de embeddings, pero todavía deja una brecha importante si queremos generar datos nuevos de forma controlada.
La limitación central es que el espacio latente de un autoencoder clásico no viene con una distribución probabilística explícita. Podemos pasar puntos arbitrarios al decoder, pero el modelo no aprende por sí solo qué regiones del espacio latente son probables, continuas o semánticamente válidas.
El VAE agrega exactamente esa pieza: en vez de codificar cada dato como un punto fijo, aprende una distribución $q_\phi(z\mid x)$ alrededor de cada dato y la regulariza contra un prior simple $p(z)$, típicamente $\mathcal{N}(0,I)$. Así, el decoder deja de ser solo un reconstructor y pasa a ser un modelo generativo $p_\theta(x\mid z)$.
La siguiente sección lo desarrolla con una idea simple: pasar de un punto a una nube.
En resumen:
| Notebook 3.1 | Notebook 3.2 |
|---|---|
| Encoder determinista $h=f_\theta(x)$ | Encoder probabilístico $q_\phi(z\mid x)$ |
| Decoder reconstructivo $\hat{x}=g_\phi(h)$ | Decoder generativo $p_\theta(x\mid z)$ |
| Pérdida de reconstrucción | ELBO: reconstrucción probabilística + regularización KL |
| Espacio latente útil para embeddings | Espacio latente muestreable para generación |
La idea central: de un punto a una distribución¶
Esta es la transición conceptual más importante de esta parte.
En un autoencoder clásico, el encoder aprende una función determinista:
$$ h = f_\theta(x) $$Eso significa que para una imagen $x$, el encoder entrega un solo punto $h$ en el espacio latente. Luego el decoder intenta reconstruir:
$$ \hat{x} = g_\psi(h) $$La idea es:
Esta imagen se resume en este punto latente.
En un VAE, el encoder no entrega directamente un punto. Entrega los parámetros de una distribución:
$$ (\mu_\phi(x), \log \sigma_\phi^2(x)) = \text{Encoder}_\phi(x) $$Con esos parámetros definimos:
$$ q_\phi(z\mid x) = \mathcal{N}(z; \mu_\phi(x), \operatorname{diag}(\sigma_\phi^2(x))) $$Ahora la idea es:
Esta imagen no se resume en un único punto; se resume en una pequeña nube de puntos latentes plausibles.
Luego tomamos una muestra de esa nube:
$$ z \sim q_\phi(z\mid x) $$Y el decoder reconstruye desde esa muestra:
$$ \hat{x} \sim p_\theta(x\mid z) $$¿Por qué esto cambia todo?¶
Si cada imagen queda codificada como un punto aislado, como en el autoencoder clásico, el espacio latente puede quedar lleno de huecos: puntos desde los cuales el decoder nunca aprendió a reconstruir nada coherente.
El VAE evita eso entrenando al decoder con muestras alrededor de cada dato y, además, empujando esas nubes hacia un prior común, típicamente:
$$ p(z)=\mathcal{N}(0,I) $$Entonces el modelo aprende dos cosas a la vez:
- Reconstruir: desde muestras $z$ cercanas a cada dato.
- Ordenar el espacio latente: para que las nubes no queden arbitrariamente dispersas.
Entonces:¶
Un autoencoder clásico aprende dónde poner cada dato en el espacio latente.
Un VAE aprende qué distribución de puntos latentes podría haber generado cada dato.
Por eso el salto no es simplemente de $f(x)$ a otra función. El salto es:
$$ f_\theta(x)=h \quad \Longrightarrow \quad q_\phi(z\mid x)=\mathcal{N}(\mu_\phi(x), \sigma_\phi^2(x)) $$Es decir: pasamos de aprender una coordenada a aprender incertidumbre estructurada alrededor de esa coordenada.
Antes de comenzar: ¿Qué es la estadística de Bayes?¶
La estadística bayesiana es un marco para actualizar incertidumbre. En Bayes, una cantidad desconocida se modela mediante una distribución de probabilidad, y esa distribución se actualiza cuando observamos datos nuevos.
La idea no es reemplazar la estadística clásica, sino enfatizar una pregunta distinta: ¿cómo cambia nuestra creencia sobre una hipótesis después de ver evidencia?
¿Cómo funciona? La idea central¶
Antes de ver los datos, tenemos una creencia inicial.
- Esto se llama prior o probabilidad previa.
Observamos datos nuevos.
- Esto se resume en la verosimilitud o likelihood, que mide qué tan probable era observar esos datos bajo cada hipótesis posible.
Actualizamos la creencia combinando prior y likelihood.
- El resultado es la posterior o probabilidad posterior.
La posterior es la creencia actualizada después de incorporar evidencia.
Fórmula básica¶
$$ \text{Posterior} = \frac{\text{Likelihood} \times \text{Prior}}{\text{Evidencia}} $$- Likelihood: qué tan compatibles son los datos observados con una hipótesis.
- Prior: creencia inicial antes de observar los datos.
- Evidencia: constante de normalización que asegura que las probabilidades sumen 1.
Ejemplo: pizza vs. hamburguesa¶
Hagamos un ejemplo discreto con solo dos hipótesis.
Queremos decidir cuál hipótesis explica mejor una encuesta pequeña:
- Hipótesis A: la pizza es muy popular. Si esto fuera cierto, la probabilidad de que una persona prefiera pizza sería $0.8$.
- Hipótesis B: la hamburguesa es más popular. Si esto fuera cierto, la probabilidad de que una persona prefiera pizza sería $0.2$.
Antes de mirar la encuesta, supongamos que creemos un poco más en la hipótesis A:
$$ P(A)=0.8, \qquad P(B)=0.2 $$Ahora hacemos una encuesta a 5 personas:
- 1 persona prefiere pizza.
- 4 personas prefieren hamburguesa.
Llamemos a estos datos $D$.
Paso 1: likelihood de los datos bajo cada hipótesis¶
Si la pizza fuera realmente muy popular, observar solo 1 persona pro-pizza entre 5 sería poco probable:
$$ P(D\mid A) = 0.0064 $$Si la hamburguesa fuera más popular, observar 1 persona pro-pizza entre 5 sería mucho más razonable:
$$ P(D\mid B) = 0.4096 $$No necesitamos memorizar de dónde salen esos números; vienen de la fórmula binomial para observar 1 éxito en 5 intentos. Lo importante es la intuición:
Los datos son mucho más compatibles con la hipótesis B que con la hipótesis A.
Paso 2: prior × likelihood¶
Ahora multiplicamos lo que creíamos antes por qué tan compatibles son los datos:
| Hipótesis | Prior | Likelihood | Prior × Likelihood |
|---|---|---|---|
| A: pizza muy popular | 0.8 | 0.0064 | 0.00512 |
| B: hamburguesa más popular | 0.2 | 0.4096 | 0.08192 |
La evidencia total es la suma:
$$ P(D)=0.00512+0.08192=0.08704 $$Paso 3: posterior¶
Normalizamos dividiendo por la evidencia:
$$ P(A\mid D)=\frac{0.00512}{0.08704}\approx 0.059 $$$$ P(B\mid D)=\frac{0.08192}{0.08704}\approx 0.941 $$Interpretación¶
Antes de observar los datos, creíamos bastante en la hipótesis A:
$$ P(A)=80\% $$Después de observar que 4 de 5 personas prefieren hamburguesa, la creencia cambia fuertemente:
$$ P(A\mid D)\approx 5.9\%, \qquad P(B\mid D)\approx 94.1\% $$La lección es:
Bayes combina lo que creíamos antes (prior) con qué tan bien cada hipótesis explica los datos (likelihood). Si los datos contradicen mucho al prior, la posterior puede cambiar bastante.
Eso es Bayes: actualizar creencias usando evidencia.
¿Por qué es importante para VAEs?¶
Porque un VAE también trabaja con una variable latente desconocida $z$. Dado un dato observado $x$, queremos razonar sobre qué valores de $z$ podrían haberlo generado. Esa pregunta es bayesiana:
$$ p(z\mid x) = \frac{p_\theta(x\mid z)p(z)}{p(x)} $$El problema es que este posterior verdadero suele ser intratable, y por eso el VAE aprende una aproximación variacional $q_\phi(z\mid x)$.
Ejemplo bayesiano con la elección Trump vs. Clinton (2016)¶
Este ejemplo se usa solo como ilustración de actualización bayesiana: partimos con un prior, observamos evidencia nueva y obtenemos una posterior distinta.
Paso 1: Prior antes de contar los votos¶
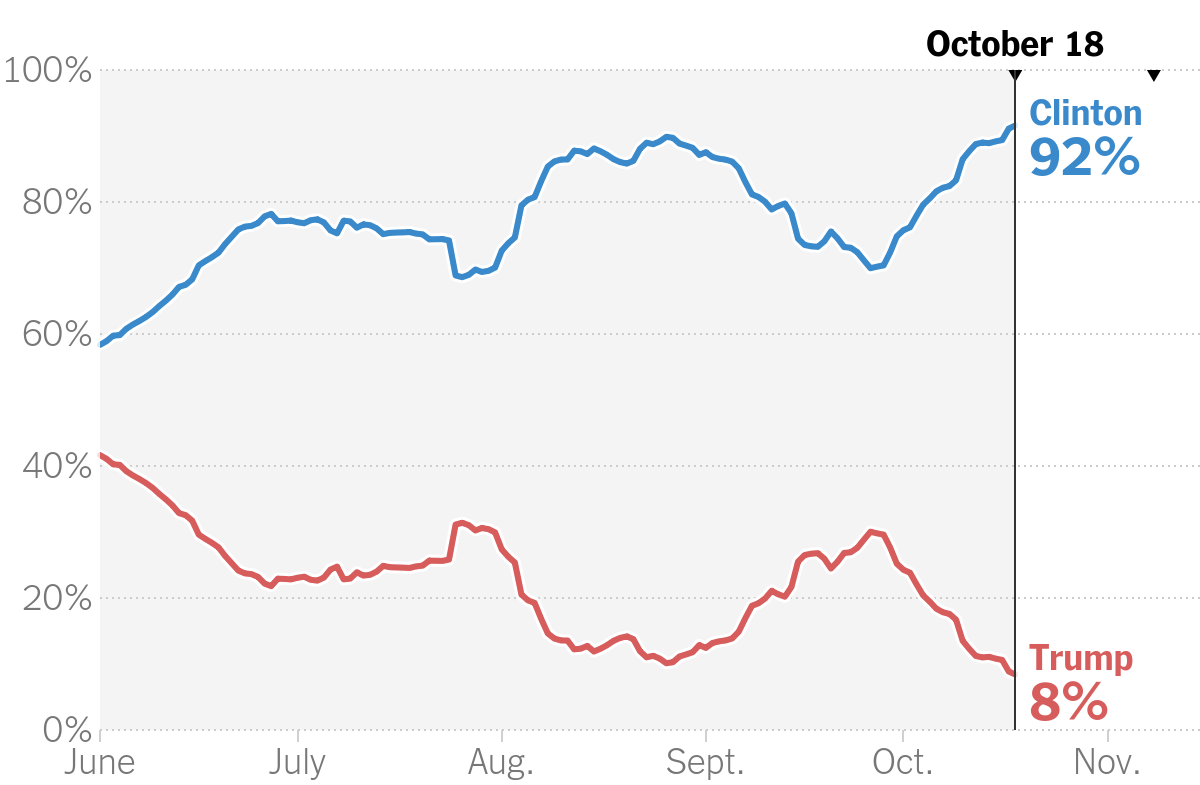
El 18 de octubre de 2016, algunas predicciones basadas en encuestas y modelos estadísticos asignaban aproximadamente:
- Clinton: 92%
- Trump: 8%
Esta creencia previa refleja el conocimiento disponible antes de la elección.
Paso 2: Evidencia en tiempo real durante el conteo¶
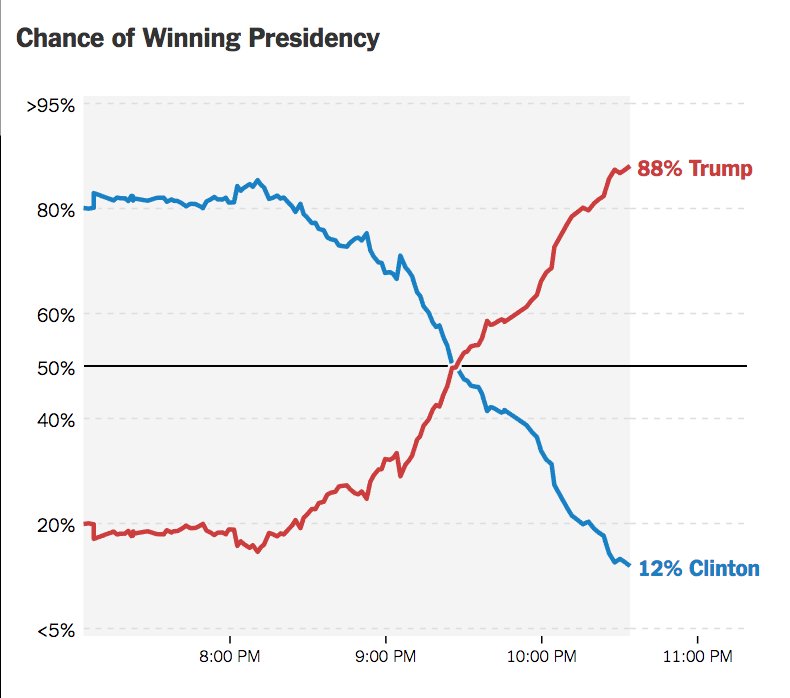
A medida que se contaban los votos la noche del 8 de noviembre, la probabilidad de victoria de Trump empezó a aumentar rápidamente, y la de Clinton a disminuir.
Esto muestra cómo un modelo bayesiano puede actualizar sus probabilidades al incorporar nueva evidencia.
Fórmula matemática de Bayes¶
La fórmula básica del Teorema de Bayes es:
$$ P(H \mid D) = \frac{P(D \mid H) \cdot P(H)}{P(D)} $$Donde:
- $P(H \mid D)$ es la probabilidad posterior de la hipótesis $H$ dados los datos $D$.
- $P(D \mid H)$ es la verosimilitud: qué tan probable es observar los datos si la hipótesis es cierta.
- $P(H)$ es la probabilidad previa de la hipótesis antes de ver los datos.
- $P(D)$ es la evidencia: la probabilidad total de observar los datos, usada como constante de normalización.
Aplicado al caso de la elección¶
Supongamos que $H$ es la hipótesis "Trump gana", y $D$ son los votos que ya se han contado.
$$ P(\text{Trump gana} \mid \text{datos}) = \frac{P(\text{datos} \mid \text{Trump gana}) \cdot P(\text{Trump gana})}{P(\text{datos})} $$- $P(\text{Trump gana}) = 0.08$ según el prior del 18 de octubre.
- $P(\text{datos} \mid \text{Trump gana})$ mide qué tan probable es observar ese patrón de votos si Trump realmente fuera el ganador.
- $P(\text{datos})$ se calcula sumando la probabilidad de los datos bajo todas las hipótesis consideradas:
Conclusión¶
Este ejemplo ilustra la lógica de Bayes:
- Prior: lo que creíamos antes.
- Likelihood: qué tan consistentes son los datos observados con cada hipótesis.
- Posterior: nueva probabilidad ajustada después de observar evidencia.
La estadística bayesiana permite actualizar incertidumbre de forma explícita en vez de trabajar como si las hipótesis fueran certezas absolutas.
Autoencoders Variacionales (VAE)¶
En el notebook 3.1 vimos que un autoencoder clásico aprende una representación comprimida capaz de reconstruir la entrada. El VAE mantiene la estructura encoder-decoder, pero cambia qué significa codificar: el encoder ya no devuelve directamente un único punto latente, sino los parámetros de una distribución latente.
Los Autoencoders Variacionales (VAE) combinan:
- Aprendizaje no supervisado.
- Modelos probabilísticos.
- Capacidad generativa.
¿Qué es un Autoencoder Variacional?¶
Un autoencoder tradicional aprende una representación comprimida $z$ de los datos $x$, con el objetivo de reconstruir $\hat{x}$ minimizando un error de reconstrucción:
$$ x \xrightarrow{\text{Encoder}} z \xrightarrow{\text{Decoder}} \hat{x} $$Sin embargo:
- La codificación es determinista: cada $x$ produce un único punto latente.
- El espacio latente no tiene un prior explícito, por lo que muestrear puntos nuevos no garantiza ejemplos válidos.
¿Qué aporta el VAE?¶
- Introduce una distribución latente $q_\phi(z\mid x)$ para cada dato $x$.
- Permite muestrear desde un prior conocido para generar datos nuevos.
- Aprende un espacio latente estructurado, continuo y regularizado.
Los Autoencoders Variacionales (VAE) son modelos generativos basados en redes neuronales que aprenden a reconstruir datos y a modelar explícitamente una distribución probabilística latente.
Objetivo¶
En un VAE queremos explicar un dato observado $x$ mediante factores latentes $z$. Formalmente, queremos inferir el posterior verdadero:
$$ p(z \mid x) = \frac{p_\theta(x \mid z)\, p(z)}{p(x)} $$Este posterior responde:
Dado un dato $x$, ¿qué valores de $z$ lo explican mejor?
El problema: $p(x)$ es intratable¶
Para calcular el posterior $p(z\mid x)$ necesitamos el denominador $p(x)$, que se obtiene marginalizando sobre todas las variables latentes posibles:
$$ p(x) = \int p_\theta(x\mid z) p(z)\, dz $$Este valor se llama verosimilitud marginal y suele ser intratable porque:
- $p_\theta(x\mid z)$ está parametrizada por una red neuronal.
- La integral sobre $z$ no tiene solución analítica en general.
- En espacios latentes de alta dimensión, integrar por fuerza bruta es computacionalmente inviable.
La solución: inferencia variacional¶
Como no podemos calcular el posterior real $p(z \mid x)$, lo aproximamos usando una distribución más simple y diferenciable:
$$ q_\phi(z \mid x) $$- Esta distribución es parametrizada por una red neuronal: el encoder.
- En el VAE básico se usa una gaussiana diagonal, $q_\phi(z\mid x)=\mathcal{N}(\mu_\phi(x), \operatorname{diag}(\sigma_\phi^2(x)))$.
- El objetivo es que $q_\phi(z \mid x) \approx p(z \mid x)$.
Este enfoque se llama inferencia variacional y permite aprender una representación latente útil mientras optimizamos una cota inferior de $\log p(x)$ llamada ELBO.
Intuición¶
Queremos saber qué $z$ pudo generar un dato $x$. Hacer inferencia exacta es demasiado difícil, así que entrenamos una red que aprende una aproximación tractable del posterior.
¿Qué es una distribución generadora?¶
Una distribución generadora describe cómo los datos se producen desde factores latentes no observables:
$$ z \sim p(z) \quad \text{(prior)}, \qquad x \sim p_\theta(x\mid z) $$Primero muestreamos $z$ desde el prior $p(z)$; luego generamos $x$ usando la distribución $p_\theta(x\mid z)$ definida por el decoder.
¿Qué representa cada parte?¶
$z \sim p(z)$
- Elegimos un vector $z$ del espacio latente.
- En el VAE estándar se usa $p(z)=\mathcal{N}(0,I)$.
- Esto define qué regiones del espacio latente son probables antes de observar un dato específico.
$x \sim p_\theta(x\mid z)$
- Generamos un dato $x$ a partir de esa variable latente $z$.
- Esta distribución está parametrizada por el decoder.
- Para imágenes binarias se suele usar Bernoulli; para datos continuos se puede usar una gaussiana con varianza fija o aprendida.
Intuición¶
El VAE aprende cómo se vería un dato si viniera de cierto punto $z$ en el espacio latente. Así puede generar ejemplos nuevos: muestreamos un $z$ y dejamos que el decoder produzca $x$.
Arquitectura del VAE¶
Descripción paso a paso¶
- Input image $x$: dato observado.
- Encoder $q_\phi(z\mid x)$: red que produce $\mu_\phi(x)$ y $\sigma_\phi^2(x)$.
- Latent space: se muestrea $z = \mu + \sigma \odot \epsilon$, con $\epsilon \sim \mathcal{N}(0,I)$.
- Decoder $p_\theta(x\mid z)$: define una distribución sobre reconstrucciones posibles.
- Loss total: término de reconstrucción probabilística + divergencia KL.
Corrección notacional importante¶
En algunas versiones del diagrama de VAE puede aparecer una confusión notacional. La diferencia entre los términos es:
- $p(z)$ representa el prior sobre variables latentes. Lo definimos nosotros, típicamente como $\mathcal{N}(0,I)$.
- $q_{\phi}(z\mid x)$ representa la aproximación variacional al posterior. La modela el encoder.
- $p_\theta(x\mid z)$ representa la distribución generadora de datos. La modela el decoder.
- $p(z\mid x)$ representa el posterior verdadero e intratable. No se modela directamente.
En la figura original, el bloque del decoder puede aparecer incorrectamente etiquetado como $p(z\mid x)$.
El decoder debería estar asociado a $p_\theta(x\mid z)$.
Es importante enfatizar que el VAE no modela directamente $p(z\mid x)$. Aproxima ese posterior con $q_\phi(z\mid x)$ y usa $p_\theta(x\mid z)$ para reconstrucción y generación.
El VAE está compuesto por dos redes neuronales¶
1. Encoder o inference network¶
Aproxima el posterior verdadero $p(z\mid x)$ con una distribución tractable:
$$ q_\phi(z \mid x) = \mathcal{N}\left(z; \mu_\phi(x), \operatorname{diag}(\sigma_\phi^2(x))\right) $$Es decir, dada una entrada $x$, la red genera:
- Un vector de medias $\mu \in \mathbb{R}^d$.
- Un vector de varianzas $\sigma^2 \in \mathbb{R}^d$.
En implementación se suele predecir $\log \sigma^2$ en vez de $\sigma^2$, porque es numéricamente más estable y evita varianzas negativas.
2. Reparametrización o capa de muestreo¶
Para permitir backpropagation a través del muestreo, se usa el truco de reparametrización:
$$ z = \mu + \sigma \odot \epsilon, \qquad \epsilon \sim \mathcal{N}(0,I) $$La aleatoriedad queda concentrada en $\epsilon$, que no depende de los parámetros del encoder. Así, el gradiente puede fluir por $\mu$ y $\sigma$ durante el entrenamiento.
3. Decoder o generative network¶
El decoder define una distribución sobre datos posibles dado un punto latente $z$:
$$ p_\theta(x \mid z) = \mathcal{N}\left(x; f_\theta(z), \sigma_x^2 I\right) $$Para imágenes binarias o píxeles en $[0,1]$, también es común usar una likelihood Bernoulli:
$$ p_\theta(x \mid z) = \operatorname{Bernoulli}\left(x; f_\theta(z)\right) $$- Si los datos son binarios o se interpretan como intensidades Bernoulli: se usa binary cross-entropy.
- Si los datos son continuos: se puede usar una pérdida cuadrática, equivalente a una gaussiana con varianza fija salvo constantes.
Función objetivo: ELBO (Evidence Lower Bound)¶
Queremos maximizar la log-verosimilitud marginal $\log p_\theta(x)$, pero esta cantidad es intratable porque integra sobre todas las posibles variables latentes $z$. Por eso maximizamos una cota inferior llamada ELBO:
$$ \log p_\theta(x) \geq \mathbb{E}_{q_\phi(z\mid x)}\left[\log p_\theta(x\mid z)\right] - D_{\mathrm{KL}}\left(q_\phi(z\mid x) \Vert p(z)\right) = \mathcal{L}_{\mathrm{ELBO}}(x) $$¿Qué significa?¶
- Queremos maximizar $\log p_\theta(x)$: la log-verosimilitud marginal de los datos.
- Como no podemos calcularla directamente, maximizamos una cota inferior.
- El modelo aprende dos cosas a la vez: reconstruir bien y mantener un espacio latente compatible con el prior.
Parte por parte¶
1. $\log p_\theta(x)$¶
- Es la log-verosimilitud marginal de los datos bajo el modelo generativo.
- En un modelo ideal querríamos maximizarla directamente.
- Pero implica integrar sobre todos los posibles $z$:
Esto suele ser intratable.
2. $\mathbb{E}_{q_\phi(z\mid x)}[\log p_\theta(x\mid z)]$¶
Qué significa:
- Es la esperanza sobre $z \sim q_\phi(z\mid x)$ del logaritmo de la probabilidad de reconstruir $x$.
- En la práctica se aproxima muestreando uno o más valores de $z$ con el truco de reparametrización.
Intuición:
- Este término premia que el decoder asigne alta probabilidad al dato original.
- Si usamos Bernoulli para los píxeles, aparece binary cross-entropy.
- Si usamos gaussiana con varianza fija, aparece MSE salvo constantes y factores de escala.
3. $D_{\mathrm{KL}}(q_\phi(z\mid x) \Vert p(z))$¶
Qué es:
- Es la divergencia KL entre la distribución inferida por el encoder y el prior $p(z)$.
Intuición:
- Mide cuánto se desvía $q_\phi(z\mid x)$ del prior gaussiano que queremos imponer.
- Actúa como regularizador del espacio latente.
Interpretación práctica:
- Si el encoder se aleja mucho de $\mathcal{N}(0,I)$, este término penaliza al modelo.
- Esto evita que cada dato ocupe una región aislada e imposible de muestrear coherentemente.
Forma que se maximiza y forma que se minimiza¶
La ELBO se maximiza:
$$ \mathcal{L}_{\mathrm{ELBO}}(x) = \mathbb{E}_{q_\phi(z\mid x)}[\log p_\theta(x\mid z)] - D_{\mathrm{KL}}(q_\phi(z\mid x) \Vert p(z)) $$En código normalmente minimizamos la negative ELBO:
$$ \mathcal{J}(x) = \text{reconstruction loss} + D_{\mathrm{KL}}(q_\phi(z\mid x) \Vert p(z)) $$Por eso en PyTorch veremos una suma entre pérdida de reconstrucción y KL, aunque matemáticamente el objetivo original se escriba como una maximización.
Intuición¶
La ELBO pide dos cosas simultáneamente: reconstruir bien los datos y no alejarse demasiado de un espacio latente gaussiano compartido. Esa tensión es precisamente lo que permite generar muestras nuevas desde el prior.
¿Existen variantes de la función objetivo?¶
Sí. Una variante muy usada es el β-VAE, que controla explícitamente la fuerza del término KL.
La forma que se maximiza es:
$$ \mathcal{L}_{\beta\text{-VAE}}(x) = \mathbb{E}_{q_\phi(z\mid x)}[\log p_\theta(x\mid z)] - \beta D_{\mathrm{KL}}(q_\phi(z\mid x) \Vert p(z)) $$La forma equivalente que se minimiza en código es:
$$ \mathcal{J}_{\beta\text{-VAE}}(x) = \text{reconstruction loss} + \beta D_{\mathrm{KL}}(q_\phi(z\mid x) \Vert p(z)) $$- Si $\beta > 1$: se fuerza mayor regularización del espacio latente y puede favorecer representaciones más disentangled, aunque con peores reconstrucciones.
- Si $\beta < 1$: se prioriza reconstrucción, pero el espacio latente puede quedar menos regularizado.
- Si $\beta = 1$: recuperamos el VAE estándar.
¿Por qué funciona el VAE?¶
Porque modela la distribución conjunta de datos y latentes:
$$ p_\theta(x,z) = p_\theta(x\mid z)p(z) $$Al mismo tiempo, aprende una aproximación variacional del posterior:
$$ q_\phi(z\mid x) \approx p_\theta(z\mid x) $$¿Qué hace especial a un VAE?¶
| Elemento | Autoencoder clásico | VAE |
|---|---|---|
| Representación latente | Determinista | Probabilística, típicamente gaussiana |
| Función objetivo | Reconstrucción | Reconstrucción probabilística + regularización KL |
| Muestreo desde prior conocido | No definido por defecto | Sí, típicamente desde $\mathcal{N}(0,I)$ |
| Interpretación probabilística | No necesariamente | Sí |
Ventajas¶
- Permite generar datos nuevos desde un prior explícito.
- Entrega una interpretación probabilística del espacio latente.
- Aprende una representación continua, útil para interpolación y exploración.
Desventajas¶
- Las reconstrucciones pueden ser borrosas cuando la likelihood pixelwise favorece promedios.
- El entrenamiento requiere balancear reconstrucción y regularización.
- La ELBO no siempre coincide con calidad perceptual.
- Puede ocurrir posterior collapse si el decoder ignora $z$ y el encoder se aproxima demasiado al prior.
Interpretación probabilística¶
El VAE puede entenderse como optimización variacional:
$$ \text{Maximizar } \log p_\theta(x) \quad \Rightarrow \quad \text{Maximizar } \mathcal{L}_{\mathrm{ELBO}}(x) $$El modelo generativo $p_\theta(x\mid z)$ y el modelo inferencial $q_\phi(z\mid x)$ son redes neuronales parametrizadas.
¿Por qué "variacional"?¶
Porque usamos inferencia variacional para aproximar el posterior intratable $p_\theta(z\mid x)$ con una distribución más sencilla $q_\phi(z\mid x)$.
Relación con autoencoders clásicos y PCA¶
| Método | Reconstrucción | Latente | Generativo | Probabilístico |
|---|---|---|---|---|
| PCA | Lineal | Sí | No | No |
| Autoencoder | No lineal | Sí | No por defecto | No por defecto |
| VAE | No lineal | Sí | Sí | Sí |
Otras extensiones del VAE¶
| Variante | Característica principal |
|---|---|
| β-VAE | Controla el peso de la KL y puede favorecer disentanglement |
| Conditional VAE (CVAE) | Modela $p_\theta(x\mid z,y)$ para generación condicionada |
| VQ-VAE | Usa variables latentes discretas mediante cuantización vectorial |
| VAE-GAN | Combina entrenamiento variacional con un discriminador adversarial |
Analogía¶
El autoencoder clásico aprende a comprimir y reconstruir. El VAE aprende además qué regiones del espacio comprimido son probables, lo que permite muestrear e interpolar de forma coherente.
Visual interactiva: intuición del VAE¶
from IPython.display import HTML
from pathlib import Path
raw = Path("vae_intuicion_interactiva.html").read_text(encoding="utf-8")
raw_escaped = raw.replace("&", "&").replace('"', """)
HTML(f"""
<iframe
srcdoc="{raw_escaped}"
width="100%"
height="1650"
style="border:none; border-radius:12px; align-self:center; margin:16px auto; display:block;">
</iframe>
""")
Ejemplo¶
# IMPORTAMOS LIBRERÍAS NECESARIAS
import gzip
import struct
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
# CONFIGURAMOS DISPOSITIVO Y SEMILLAS
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.manual_seed(42)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(42)
# CARGA LOCAL DE MNIST DESDE ARCHIVOS IDX
# Evita depender de torchvision y usa los archivos ya disponibles en ./data/MNIST/raw.
def _open_idx(path):
# Abre un archivo IDX (ya sea comprimido o no) para lectura.
path = Path(path)
if path.suffix == ".gz":
return gzip.open(path, "rb")
return path.open("rb")
def _find_mnist_file(raw_dir, filename):
# Busca el archivo MNIST dado un nombre base, considerando tanto versiones comprimidas como sin comprimir.
raw_dir = Path(raw_dir)
for candidate in (raw_dir / filename, raw_dir / f"{filename}.gz"):
if candidate.exists():
return candidate
raise FileNotFoundError(
f"No se encontró {filename} en {raw_dir}. "
"Verifica que los archivos MNIST estén en ./data/MNIST/raw."
)
def _read_idx_images(path):
# Lee un archivo IDX de imágenes MNIST y devuelve un tensor de PyTorch con forma (n_images, 1, 28, 28) normalizado a [0,1].
with _open_idx(path) as f:
magic, n_images, rows, cols = struct.unpack(">IIII", f.read(16))
if magic != 2051:
raise ValueError(f"Archivo de imágenes MNIST inválido: {path}")
data = np.frombuffer(f.read(), dtype=np.uint8).copy()
images = data.reshape(n_images, 1, rows, cols).astype("float32") / 255.0
return torch.from_numpy(images)
def _read_idx_labels(path):
# Lee un archivo IDX de etiquetas MNIST y devuelve un tensor de PyTorch con forma (n_labels,) con valores enteros.
with _open_idx(path) as f:
magic, n_labels = struct.unpack(">II", f.read(8))
if magic != 2049:
raise ValueError(f"Archivo de etiquetas MNIST inválido: {path}")
data = np.frombuffer(f.read(), dtype=np.uint8).copy()
if len(data) != n_labels:
raise ValueError(f"Número de etiquetas inconsistente en {path}")
return torch.from_numpy(data.astype("int64"))
def load_mnist_dataset(root="./data", train=True, normalize=False):
# Carga el dataset MNIST desde archivos IDX locales, devolviendo un TensorDataset con imágenes y etiquetas.
raw_dir = Path(root) / "MNIST" / "raw"
prefix = "train" if train else "t10k"
images = _read_idx_images(_find_mnist_file(raw_dir, f"{prefix}-images-idx3-ubyte"))
labels = _read_idx_labels(_find_mnist_file(raw_dir, f"{prefix}-labels-idx1-ubyte"))
if normalize:
images = (images - 0.5) / 0.5
return TensorDataset(images, labels)
def make_mnist_loaders(batch_size=128, normalize=False):
# Crea DataLoaders para el dataset MNIST usando la función de carga local, con opciones de normalización.
train_dataset = load_mnist_dataset(train=True, normalize=normalize)
test_dataset = load_mnist_dataset(train=False, normalize=normalize)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_loader, test_loader
# PREPROCESAMIENTO DE LOS DATOS (MNIST a tensores 1x28x28)
train_loader, test_loader = make_mnist_loaders(batch_size=128, normalize=False)
# DEFINIMOS EL MODELO VAE
class VAE(nn.Module):
# Un Variational Autoencoder (VAE) simple para imágenes MNIST. El encoder mapea la imagen a
# un espacio latente, y el decoder reconstruye la imagen desde ese espacio.
# nn.Module es la clase base para todos los modelos de PyTorch, y aquí definimos las capas del encoder y decoder.
def __init__(self, input_dim=784, hidden_dim=400, latent_dim=2):
# Llamamos al constructor de la clase base nn.Module para inicializar el modelo.
super(VAE, self).__init__()
# Encoder layers
# El encoder consta de una capa oculta que mapea la imagen a un espacio de características, y luego dos
# capas que mapean esas características a los parámetros de la distribución latente (media y log-varianza).
# Capa oculta del encoder que mapea la imagen a un espacio de características. Es lineal ya que
# luego aplicaremos una función de activación no lineal (ReLU) a su salida.
self.fc1 = nn.Linear(input_dim, hidden_dim)
# Capa que mapea las características a la media de la distribución latente q(z|x) que representa la media
# de la distribución normal que modela el espacio latente.
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
# Capa que mapea las características a la log-varianza de la distribución latente q(z|x). La log-varianza
# se utiliza para asegurar que la varianza sea positiva, ya que la varianza es la exponencial de la log-varianza.
# El algoritmo no "entiende" que es logvar, simplemente lo que hacemos es definir una capa lineal que mapea a un
# espacio de características. Lo que realmente define que es logvar es cómo usamos la salida de esa capa en el
# método reparameterize. En ese método, tomamos la salida de fc_logvar y la tratamos como log-varianza al aplicar
# la función torch.exp para obtener la varianza. Ahí el algoritmo aprende que la salida de fc_logvar representa
# log-varianza porque es lo que hacemos con esa salida en el código.
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
# Decoder layers
# Capa oculta del decoder que mapea el espacio latente a un espacio de características,
# y luego una capa de salida que mapea esas características a la imagen reconstruida (en formato aplanado).
self.fc3 = nn.Linear(latent_dim, hidden_dim)
self.fc4 = nn.Linear(hidden_dim, input_dim)
def encode(self, x):
# Codificamos la imagen x a un espacio latente z usando una distribución normal
h1 = F.relu(self.fc1(x)) # Aplicamos ReLU a la salida de la primera capa para introducir no linealidad
mu = self.fc_mu(h1) # Media de la distribución q(z|x)
logvar = self.fc_logvar(h1) # Log-varianza (para asegurar positividad)
return mu, logvar
def reparameterize(self, mu, logvar):
# ------------------------------------------------------------
# Truco de reparametrización
# ------------------------------------------------------------
#
# Problema que queremos resolver:
#
# En un VAE, el encoder no entrega directamente un vector latente z.
# En vez de eso, entrega los parámetros de una distribución latente:
#
# q(z|x) = N(mu, sigma^2)
#
# Es decir, para cada imagen x, el encoder aprende:
#
# mu = centro de la distribución latente
# logvar = logaritmo de la varianza de esa distribución
#
# Esto significa que el modelo no representa cada imagen como un punto fijo,
# sino como una pequeña región probabilística del espacio latente.
#
# El decoder, sin embargo, no puede reconstruir desde una distribución completa.
# Necesita recibir un vector concreto z. Por eso necesitamos muestrear:
#
# z ~ N(mu, sigma^2)
#
# El problema es que el muestreo directo introduce una operación aleatoria
# dentro de la red. Si hacemos algo como:
#
# z = sample_normal(mu, sigma)
#
# entonces z depende al mismo tiempo de los parámetros aprendidos
# y del azar del muestreo. En una pasada podría salir un valor, y con
# una media casi idéntica podría salir otro valor muy distinto simplemente
# porque se sorteó otra muestra.
#
# Eso dificulta backpropagation, porque la pérdida de reconstrucción necesita
# saber cómo ajustar las capas que produjeron mu y logvar.
#
# Recordemos que mu y logvar no son números sueltos: son salidas del encoder.
# Es decir:
#
# mu = f_encoder(x)
# logvar = g_encoder(x)
#
# y esas funciones dependen de los pesos del modelo.
#
# Lo que necesitamos es que exista un camino diferenciable:
#
# pesos del encoder -> mu, logvar -> z -> reconstrucción -> pérdida
#
# El truco de reparametrización resuelve esto separando la parte aleatoria
# de la parte aprendible.
#
# En vez de muestrear directamente:
#
# z ~ N(mu, sigma^2)
#
# hacemos:
#
# epsilon ~ N(0, I)
# z = mu + sigma * epsilon
#
# Esta operación genera muestras de la misma distribución N(mu, sigma^2),
# pero ahora el azar está aislado en epsilon.
#
# epsilon NO es un parámetro del modelo.
# epsilon NO se aprende.
# epsilon NO queda fijo durante todo el entrenamiento.
#
# Se genera un nuevo epsilon en cada forward pass:
#
# eps = torch.randn_like(std)
#
# Pero durante esa pasada concreta, epsilon se trata como una constante.
# Dado ese epsilon, z sí es una función diferenciable de mu y sigma:
#
# z = mu + sigma * epsilon
#
# Por ejemplo:
#
# dz/dmu = 1
# dz/dsigma = epsilon
#
# Por eso, si la reconstrucción es mala, la pérdida puede enviar gradientes
# hacia las capas que produjeron mu y logvar.
#
# Importante:
#
# La reparametrización no elimina el azar. El gradiente sigue siendo ruidoso,
# porque en cada forward pass se usa un epsilon distinto. Sin embargo, el ruido
# queda controlado por sigma:
#
# ruido efectivo = sigma * epsilon
#
# Si sigma es pequeño, z queda cerca de mu.
# Si sigma es grande, z puede explorar una región más amplia.
#
# Además, el término KL de la pérdida regulariza q(z|x) para que no se aleje
# demasiado del prior N(0, I). Por eso el modelo aprende un balance entre:
#
# 1. reconstruir bien las imágenes
# 2. mantener un espacio latente ordenado y muestreable
#
# En resumen:
#
# El truco de reparametrización permite entrenar un modelo con espacio latente
# probabilístico usando backpropagation. Convierte el muestreo desde una
# distribución aprendida en una operación diferenciable respecto a mu y sigma.
# Convertimos log-varianza a desviación estándar.
# Si logvar = log(sigma^2), entonces:
# sigma = sqrt(exp(logvar)) = exp(0.5 * logvar)
std = torch.exp(0.5 * logvar)
# Generamos ruido estándar con la misma forma que std.
# Este epsilon cambia en cada forward pass, pero durante esa pasada se trata
# como una constante independiente de los parámetros del modelo.
eps = torch.randn_like(std)
# Construimos la muestra latente usando la reparametrización.
# Esto equivale a muestrear desde N(mu, sigma^2), pero mantiene un camino
# diferenciable desde la pérdida hacia mu y logvar.
z = mu + eps * std
return z
def decode(self, z):
# Decodificamos z para reconstruir la imagen
h3 = F.relu(self.fc3(z))
return torch.sigmoid(self.fc4(h3)) # Salida en [0,1] para imágenes
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
recon_x = self.decode(z)
return recon_x, mu, logvar
# DEFINIMOS LA FUNCIÓN DE PÉRDIDA: NEGATIVE ELBO
def loss_function(recon_x, x, mu, logvar):
reconstruction_loss = F.binary_cross_entropy(recon_x, x, reduction='sum') # Pérdida de reconstrucción (reconstrucción pixel a pixel)
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp()) # Pérdida KL entre q(z|x) y p(z) (asumiendo p(z) ~ N(0, I))
return reconstruction_loss + kl_loss # La pérdida total es la suma de la pérdida de reconstrucción y la pérdida KL, que juntos forman el ELBO negativo que queremos minimizar.
# INSTANCIAMOS EL MODELO Y OPTIMIZADOR
model = VAE().to(device) # Creamos una instancia del modelo VAE y la movemos al dispositivo (GPU o CPU)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) # Usamos el optimizador Adam para actualizar los pesos del modelo durante el entrenamiento, con una tasa de aprendizaje de 0.001.
# ENTRENAMIENTO DEL MODELO
epochs = 10
for epoch in range(epochs):
model.train()# Ponemos el modelo en modo entrenamiento para habilitar comportamientos específicos como dropout o batch normalization (aunque este modelo no los tiene, es una buena práctica).
train_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
# Aplanamos las imágenes de 28x28 a 784 para que puedan ser procesadas por el VAE, y las movemos al dispositivo.
# No tenemos capa convolucional ya que el VAE es completamente conectado, por lo que necesitamos aplanar las imágenes antes de pasarlas al encoder.
# Funciona bien ya que MNIST es un dataset relativamente simple, pero para datasets más complejos podríamos considerar un VAE convolucional.
# Por que el VAE no necesita capa convolucional para reconstruir bien MNIST?
# Porque MNIST es un dataset de dígitos escritos a mano que son relativamente simples y
# tienen poca variabilidad en comparación con otros tipos de imágenes. Las capas completamente
# conectadas pueden capturar las características necesarias para reconstruir estas imágenes sin
# necesidad de la capacidad de extracción de características espaciales que ofrecen las capas
# convolucionales. Sin embargo, para datasets más complejos con mayor variabilidad y detalles
# espaciales, un VAE convolucional podría ser más efectivo.
data = data.view(-1, 784).to(device) # Aplanamos la imagen (28x28 -> 784)
# Reiniciamos los gradientes antes de la retropropagación ya que PyTorch acumula los gradientes por
# defecto. Si no hacemos esto, los gradientes de cada batch se acumularían, lo que no es deseable porque
# queremos que cada actualización de los pesos se base solo en el batch actual.
optimizer.zero_grad()
# Pasamos los datos por el modelo para obtener la reconstrucción y los parámetros de la distribución
# latente (mu y logvar). Luego calculamos la pérdida usando la función de pérdida definida anteriormente,
# que combina la pérdida de reconstrucción y la pérdida KL. Después de calcular la pérdida, realizamos
# la retropropagación para calcular los gradientes y luego actualizamos los pesos del modelo usando el optimizador.
recon_batch, mu, logvar = model(data) # Obtenemos la reconstrucción y los parámetros latentes del modelo
loss = loss_function(recon_batch, data, mu, logvar)# Calculamos la pérdida total para este batch
loss.backward()# Calculamos los gradientes de la pérdida con respecto a los parámetros del modelo
train_loss += loss.item() # Acumulamos la pérdida total para este epoch
optimizer.step() # Actualizamos los pesos del modelo usando el optimizador
print(f'Epoch {epoch+1}, Loss: {train_loss / len(train_loader.dataset):.4f}')
# VISUALIZAMOS RECONSTRUCCIONES
model.eval() # Ponemos el modelo en modo evaluación para deshabilitar comportamientos específicos de entrenamiento como dropout o batch normalization, asegurando que el modelo se comporte de manera determinista durante la evaluación.
with torch.no_grad():
# Tomamos 10 imágenes reales del dataset de prueba
test_data = next(iter(test_loader))[0][:10].to(device)
test_data_flat = test_data.view(-1, 784)
recon, _, _ = model(test_data_flat)
# Mostramos originales vs reconstrucciones
plt.figure(figsize=(15, 3))
for i in range(10):
# Imagen original
plt.subplot(2, 10, i + 1)
plt.imshow(test_data[i][0].cpu(), cmap='gray')
plt.axis('off')
# Imagen reconstruida
plt.subplot(2, 10, i + 11)
plt.imshow(recon[i].view(28, 28).cpu(), cmap='gray')
plt.axis('off')
plt.suptitle('Arriba: Originales | Abajo: Reconstrucciones', fontsize=16)
plt.show()

Evaluación de las reconstrucciones del VAE¶
Parte superior: imágenes originales (MNIST)¶
- Son dígitos reales del conjunto de evaluación.
- Sirven como referencia para revisar qué información visual debe preservar el modelo.
Parte inferior: reconstrucciones del VAE¶
- Los dígitos reconstruidos mantienen la estructura general, pero pueden verse suavizados.
- Esto es esperable en un VAE simple con espacio latente de solo 2 dimensiones.
- Clases visualmente parecidas, como 6 y 8 o 4 y 9, pueden mezclarse parcialmente en el espacio latente.
¿Por qué se ven así?¶
Reconstrucciones borrosas
- El decoder modela una distribución $p_\theta(x\mid z)$, no una copia determinista píxel a píxel.
- Las likelihoods pixelwise tienden a favorecer soluciones promedio cuando existe incertidumbre.
Limitaciones del espacio latente
- Usar $z \in \mathbb{R}^2$ facilita visualizar el espacio latente.
- Pero dos dimensiones son muy restrictivas para representar la variabilidad de 10 dígitos.
Capacidad y entrenamiento
- Más épocas, más capacidad o un espacio latente más grande suelen mejorar la reconstrucción.
- Pero demasiada capacidad sin regularización puede debilitar la estructura generativa.
Recomendaciones para mejorar¶
| Mejora | Acción sugerida | Trade-off |
|---|---|---|
| Mejor definición | Aumentar épocas o capacidad | Mayor costo computacional |
| Mayor precisión | Usar latent_dim entre 5 y 20 |
Pierde visualización 2D directa |
| Visualización | Mantener $z \in \mathbb{R}^2$ | Reconstrucciones menos detalladas |
| Control de regularización | Experimentar con β-VAE | Cambia el balance reconstrucción-generación |
# Librerías necesarias
import seaborn as sns
import matplotlib.pyplot as plt
# Dataset de prueba (MNIST) con etiquetas
_, test_loader = make_mnist_loaders(batch_size=1000, normalize=False)# Cargamos el dataset de prueba con un batch grande para obtener muchas imágenes a la vez. No normalizamos para mantener los valores en [0,1], lo que facilita la interpretación de las reconstrucciones y el espacio latente.
# Codificamos muchas imágenes para observar su ubicación en el espacio latente
model.eval()
all_z = []
all_labels = []
# usamos torch para obtener las representaciones latentes de las imágenes del dataset de prueba.
# Al usar torch.no_grad(), desactivamos el cálculo de gradientes, lo que es importante porque solo
# queremos obtener las representaciones latentes para visualización y no necesitamos calcular gradientes
# para esto. Esto ahorra memoria y mejora la velocidad durante esta fase de evaluación. Luego,
# iteramos sobre el test_loader, aplanamos las imágenes y las pasamos por el encoder del modelo para obtener
# la media (mu) de la distribución latente q(z|x). Al usar mu como punto representativo, obtenemos un punto
# fijo para cada imagen en el espacio latente, lo que facilita la visualización. Si usáramos muestras
# aleatorias (z = mu + eps * std), cada imagen podría aparecer en diferentes lugares del espacio latente
# en cada pasada debido al ruido introducido por eps, lo que dificultaría la interpretación del espacio latente.
with torch.no_grad(): #
for data, labels in test_loader:
data = data.view(-1, 784).to(device)
mu, _ = model.encode(data)
all_z.append(mu.cpu())
all_labels.append(labels)
# Concatenamos todo
z_points = torch.cat(all_z, dim=0).numpy()# Concatenamos las representaciones latentes de todas las imágenes en un solo tensor y lo convertimos a numpy para facilitar la visualización.
z_labels = torch.cat(all_labels, dim=0).numpy() # Concatenamos las etiquetas de todas las imágenes en un solo tensor y lo convertimos a numpy para facilitar la visualización. Estas etiquetas se usarán para colorear los puntos en el espacio latente según su clase (dígito).
# Visualizamos con Seaborn
plt.figure(figsize=(10, 8))
sns.scatterplot(x=z_points[:, 0], y=z_points[:, 1], hue=z_labels, palette='tab10', alpha=0.7, s=40)
plt.title('Espacio Latente 2D del VAE (coloreado por dígito)', fontsize=16)
plt.xlabel('z[0]')
plt.ylabel('z[1]')
plt.legend(title='Clase', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(True)
plt.tight_layout()
plt.show()

Análisis del espacio latente 2D del VAE¶
¿Qué muestra este gráfico?¶
Cada punto representa una imagen del conjunto de prueba MNIST codificada por el VAE en un espacio latente de 2 dimensiones. El color indica la clase real del dígito, lo que permite evaluar si la geometría latente refleja similitud visual.
¿Qué podemos interpretar?¶
1. Agrupamientos por clase¶
- Zonas con alta densidad de un mismo color sugieren que el modelo aprendió representaciones latentes coherentes con ciertas clases.
- Este agrupamiento no se optimiza de forma supervisada: aparece porque dígitos de la misma clase comparten estructura visual.
2. Superposición entre clases¶
- Clases como 4 y 9, o 3 y 8, pueden quedar solapadas porque comparten trazos.
- En 2D no siempre hay suficiente capacidad para separar 10 clases sin perder continuidad generativa.
3. Relación con el prior¶
- El término KL empuja las distribuciones $q_\phi(z\mid x)$ hacia el prior $\mathcal{N}(0,I)$.
- Por eso esperamos mayor densidad cerca de regiones probables bajo el prior y menos estructura confiable en zonas muy alejadas.
- Si aparece una forma curva o continua, debe interpretarse como resultado del balance entre reconstrucción y regularización, no como una propiedad universal de todos los VAEs.
Limitaciones y oportunidades¶
| Observación | Implicación | Qué hacer |
|---|---|---|
| Solapamiento de clases | El modelo no discrimina completamente | Entrenar más o aumentar latent_dim |
| Concentración cerca del prior | La KL está regularizando el espacio | Revisar balance reconstrucción/KL |
| Buen agrupamiento de ciertos dígitos | El VAE captó relaciones visuales | Confirmar con reconstrucciones y muestreos |
import numpy as np
import matplotlib.pyplot as plt
# Asegúrate de tener el modelo entrenado con `latent_dim=2`
model.eval()
# Definimos una grilla regular de puntos en el espacio latente (z[0], z[1])
n = 20 # número de puntos por dimensión (grilla n x n)
grid_x = np.linspace(-4, 4, n)
grid_y = np.linspace(-4, 4, n)
# Creamos una figura para visualizar las imágenes generadas
canvas = np.zeros((28 * n, 28 * n)) # grilla de 28x28 imágenes
with torch.no_grad():
for i, yi in enumerate(grid_y): # Iteramos sobre cada valor de z[1] en la grilla
for j, xi in enumerate(grid_x): # Iteramos sobre cada valor de z[0] en la grilla
z_sample = torch.tensor([[xi, yi]], dtype=torch.float32).to(device) # punto z que entra al decoder
x_decoded = model.decode(z_sample) # decodificamos el punto z para obtener la imagen generada
digit = x_decoded.view(28, 28).cpu().numpy() # convertimos la salida del decoder a una imagen 28x28
canvas[i * 28:(i + 1) * 28, j * 28:(j + 1) * 28] = digit
# Mostrar el canvas completo
plt.figure(figsize=(10, 10))
plt.imshow(canvas, cmap="gray")
plt.title('Muestreo del espacio latente 2D – Dígitos generados')
plt.axis('off')
plt.show()

Evaluación: muestreo del espacio latente 2D en el VAE¶
¿Qué estamos viendo?¶
- Cada imagen fue generada por el decoder del VAE a partir de un punto $z=(z_0,z_1)$ en una grilla 2D.
- El objetivo es observar cómo cambia la salida del modelo al recorrer el espacio latente.
Durante el entrenamiento, el VAE aprende a mapear imágenes reales $x$ hacia distribuciones latentes $q_\phi(z\mid x)$. En generación hacemos el proceso inverso: tomamos un $z$ directamente desde el espacio latente y lo pasamos por el decoder para generar una imagen.
Interpretación conceptual¶
| Elemento observado | Qué significa |
|---|---|
| Transiciones suaves entre dígitos | El decoder aprendió continuidad local en el espacio latente. |
| Zonas densas y definidas | Son regiones más compatibles con el prior $\mathcal{N}(0,I)$ y con los datos vistos. |
| Regiones borrosas en bordes o esquinas | Corresponden a zonas de baja probabilidad bajo el prior o poco visitadas durante entrenamiento. |
| Predominancia de ciertos dígitos | Algunas regiones latentes quedan asociadas a patrones visuales dominantes. |
¿Qué nos enseña esto?¶
- El VAE aprende una representación continua y estructurada del dominio de los dígitos.
- La generación no es puramente azarosa: cada región del espacio latente puede adquirir semántica visual.
- Este experimento muestra la diferencia clave con un autoencoder clásico: ahora existe una forma razonable de muestrear desde el espacio latente.
Este mapa no es un mapa de píxeles, sino una visualización del espacio de factores latentes que el modelo aprendió. Cada coordenada $z$ representa una combinación de rasgos abstractos que el decoder transforma en una imagen.
Experimento 2: más capacidad manteniendo $z \in \mathbb{R}^2$¶
El primer VAE usa un espacio latente 2D para facilitar visualización. Ahora aumentamos la capacidad de la red y entrenamos por más épocas, pero mantenemos latent_dim=2. Esto permite aislar una pregunta: ¿cuánto mejora la reconstrucción si el cuello de botella sigue siendo visualizable?
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.manual_seed(42)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(42)
# Cargamos MNIST normalizado a [-1, 1] para usar salida tanh.
train_loader, test_loader = make_mnist_loaders(batch_size=128, normalize=True)
# Modelo mejorado
class VAE(nn.Module):
# Un VAE simple pero con arquitectura ligeramente más profunda y salida tanh para mejorar la calidad de las reconstrucciones.
def __init__(self, input_dim=784, hidden_dim=512, latent_dim=2):
super(VAE, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
self.fc3 = nn.Linear(latent_dim, hidden_dim)
self.fc4 = nn.Linear(hidden_dim, hidden_dim)
self.fc5 = nn.Linear(hidden_dim, input_dim)
def encode(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
return self.fc_mu(h), self.fc_logvar(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h = F.relu(self.fc3(z))
h = F.relu(self.fc4(h))
return torch.tanh(self.fc5(h)) # Tanh mejora reconstrucciones con normalización
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
# Pérdida: negative ELBO con likelihood gaussiana de varianza fija
def loss_function(recon_x, x, mu, logvar):
reconstruction_loss = F.mse_loss(recon_x, x, reduction='sum')
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return reconstruction_loss + kl_loss
model = VAE().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# Entrenamiento
epochs = 30 # más entrenamiento para mejores resultados
for epoch in range(epochs):
model.train()
train_loss = 0
for data, _ in train_loader:
data = data.view(-1, 784).to(device)
optimizer.zero_grad()
recon, mu, logvar = model(data)
loss = loss_function(recon, data, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {train_loss / len(train_loader.dataset):.4f}")
# Visualización
model.eval()
with torch.no_grad():
data_iter = iter(test_loader)
test_data, _ = next(data_iter)
test_data = test_data.to(device)
test_data_flat = test_data.view(-1, 784)
recon, _, _ = model(test_data_flat)
test_data = test_data * 0.5 + 0.5 # desnormalizar
recon = recon * 0.5 + 0.5
plt.figure(figsize=(15, 3))
for i in range(10):
plt.subplot(2, 10, i + 1)
plt.imshow(test_data[i][0].cpu(), cmap='gray')
plt.axis('off')
plt.subplot(2, 10, i + 11)
plt.imshow(recon[i].view(28, 28).cpu(), cmap='gray')
plt.axis('off')
plt.suptitle('Arriba: Originales | Abajo: Reconstrucciones (mejoradas)', fontsize=16)
plt.show()

Experimento 3: aumentar dimensión latente¶
Ahora aumentamos latent_dim a 10. La hipótesis es que un espacio latente más amplio debería mejorar la reconstrucción, porque el modelo puede codificar más variación visual. El costo es que ya no podemos visualizar directamente todo el espacio latente en 2D sin usar otra técnica de reducción dimensional.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.manual_seed(42)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(42)
# Cargamos MNIST normalizado a [-1, 1] para usar salida tanh.
train_loader, test_loader = make_mnist_loaders(batch_size=128, normalize=True)
# Modelo con más dimensiones latentes
class VAE(nn.Module):
def __init__(self, input_dim=784, hidden_dim=512, latent_dim=10): # << aumentado a 10
super(VAE, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
self.fc3 = nn.Linear(latent_dim, hidden_dim)
self.fc4 = nn.Linear(hidden_dim, hidden_dim)
self.fc5 = nn.Linear(hidden_dim, input_dim)
def encode(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
return self.fc_mu(h), self.fc_logvar(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h = F.relu(self.fc3(z))
h = F.relu(self.fc4(h))
return torch.tanh(self.fc5(h)) # usamos tanh porque los datos están normalizados
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
# Pérdida: negative ELBO con likelihood gaussiana de varianza fija
def loss_function(recon_x, x, mu, logvar):
reconstruction_loss = F.mse_loss(recon_x, x, reduction='sum')
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return reconstruction_loss + kl_loss
# Early stopping (sencillo)
class EarlyStopper:
def __init__(self, patience=5, min_delta=1e-4):
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.best_loss = float('inf')
def check(self, current_loss):
if current_loss < self.best_loss - self.min_delta:
self.best_loss = current_loss
self.counter = 0
else:
self.counter += 1
return self.counter >= self.patience
# Entrenamiento con early stopping
model = VAE().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
epochs = 100 # máximo permitido
# paciencia de 6 epochs sin mejora significativa (delta mínimo de 0.01) para activar el early stopping
early_stopper = EarlyStopper(patience=6,min_delta=1e-2)
for epoch in range(epochs):
model.train()
train_loss = 0
for data, _ in train_loader:
data = data.view(-1, 784).to(device)
optimizer.zero_grad()
recon, mu, logvar = model(data)
loss = loss_function(recon, data, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
avg_loss = train_loss / len(train_loader.dataset)
print(f"Epoch {epoch+1}, Loss: {avg_loss:.4f}")
if early_stopper.check(avg_loss):
print("Early stopping activado.")
break
# Visualización final
model.eval()
with torch.no_grad():
data_iter = iter(test_loader)
test_data, _ = next(data_iter)
test_data = test_data.to(device)
test_data_flat = test_data.view(-1, 784)
recon, _, _ = model(test_data_flat)
test_data = test_data * 0.5 + 0.5
recon = recon * 0.5 + 0.5
plt.figure(figsize=(15, 3))
for i in range(10):
plt.subplot(2, 10, i + 1)
plt.imshow(test_data[i][0].cpu(), cmap='gray')
plt.axis('off')
plt.subplot(2, 10, i + 11)
plt.imshow(recon[i].view(28, 28).cpu(), cmap='gray')
plt.axis('off')
plt.suptitle('Reconstrucciones con VAE (10D latente + early stopping)', fontsize=16)
plt.show()

¿Qué estamos haciendo durante el entrenamiento?¶
- Para cada dato $x$, el encoder produce una distribución $q_\phi(z\mid x)=\mathcal{N}(\mu_\phi(x),\operatorname{diag}(\sigma_\phi^2(x)))$.
- El modelo muestrea un punto $z$ usando $z=\mu+\sigma\odot\epsilon$, con $\epsilon\sim\mathcal{N}(0,I)$.
- El decoder aprende a asignar alta probabilidad al dato original $x$ condicionado en ese $z$.
- La divergencia KL empuja cada $q_\phi(z\mid x)$ hacia el prior $p(z)=\mathcal{N}(0,I)$.
¿Qué efecto tiene esto?¶
Entrenamos al decoder no solo con un punto fijo por dato, sino con muestras alrededor de la media $\mu$. Esto obliga a que regiones cercanas del espacio latente produzcan salidas coherentes.
Este mecanismo suaviza y regulariza el espacio latente:
- El decoder aprende a generar algo plausible para regiones completas, no solo para puntos aislados.
- El prior $\mathcal{N}(0,I)$ da una regla clara para muestrear ejemplos nuevos.
- La KL evita que cada ejemplo quede codificado en una isla separada del resto.
En contraste con un autoencoder clásico¶
- El AE ve un único punto determinista $z=f_\theta(x)$ por cada $x$.
- Si damos al decoder un $z$ nunca visto, no hay garantía de que ese punto pertenezca a una región válida del espacio latente.
- El VAE resuelve esto al entrenar con distribuciones y regularizar el espacio contra un prior común.
Cierre¶
El notebook 3.1 mostró cómo aprender embeddings mediante reconstrucción. Este notebook agrega la capa probabilística: el embedding ya no es solo una compresión, sino una variable latente con distribución. Esa diferencia convierte al autoencoder en un modelo generativo entrenable.