Generative Adversarial Networks¶
Modelos de Machine Learning No-Supervisados¶
Dr. Cristian Candia¶
Universidad del Desarrollo (UDD), Chile¶
- Director, Computational Research in Social Sciences Lab
- Faculty, Data Science Institute, School of Engineering
Northwestern University, United States¶
- External Faculty, Northwestern Institute on Complex Systems (NICO), Kellogg School of Management
Founder & CSTO¶
- Capybara. Capybara ayuda a establecimiento educacionales a detectar señales tempranas de bullying, medir convivencia escolar y tomar decisiones basadas en evidencia para prevenir conflictos a tiempo.

GANs: Redes Generativas Adversarias¶
1. De VAE a GAN: ¿por qué necesitamos otro enfoque generativo?¶
En el módulo anterior vimos autoencoders y autoencoders variacionales (VAE). La idea central era aprender un espacio latente $z$ que permitiera reconstruir o generar datos.
En un VAE, el modelo tiene una estructura probabilística explícita:
- el encoder aproxima un posterior latente $q_\phi(z \mid x)$;
- el decoder modela una distribución de reconstrucción $p_\theta(x \mid z)$;
- el entrenamiento maximiza una cota inferior de la log-verosimilitud, la ELBO.
Eso tiene una ventaja importante: el VAE sabe qué función objetivo está optimizando y mantiene un espacio latente relativamente ordenado. Pero también tiene una limitación práctica: cuando usamos likelihoods simples, como Bernoulli o Gaussiana, las reconstrucciones o muestras pueden volverse demasiado promedio o suavizadas.
Entonces aparece una pregunta natural:
¿Podemos generar muestras realistas sin escribir explícitamente un likelihood para los datos?
Las GANs responden que sí. En vez de maximizar una likelihood, entrenan dos redes en competencia:
- un generador, que intenta producir muestras falsas parecidas a las reales;
- un discriminador, que intenta distinguir muestras reales de muestras generadas.
La transición conceptual es esta:
| Pregunta | VAE | GAN |
|---|---|---|
| ¿Cómo aprende a generar? | Reconstrucción + regularización probabilística. | Competencia entre generador y discriminador. |
| ¿Usa likelihood explícita? | Sí, mediante $p_\theta(x \mid z)$ y ELBO. | No directamente. Aprende una distribución implícita. |
| ¿Qué aprende el latente? | Un espacio probabilístico regularizado. | Un ruido $z$ que el generador transforma en muestras realistas. |
| ¿Riesgo típico? | Muestras suaves o promedio. | Entrenamiento inestable o colapso de modos. |
2. ¿Qué queremos lograr con una GAN?¶
Queremos aprender una distribución $p_{\text{data}}(x)$ a partir de ejemplos reales y generar nuevas muestras que parezcan provenir de esa distribución.
Por ejemplo, si entrenamos con imágenes de rostros, queremos generar rostros nuevos que no estaban en el dataset, pero que sean visualmente plausibles.
La diferencia clave con VAE es que la GAN no pregunta:
“¿Qué tan probable es este dato bajo mi likelihood?”
sino:
“¿Mi muestra generada es suficientemente realista como para engañar a un discriminador?”
3. GAN vs VAE: diferencia conceptual¶
| Característica | VAE | GAN |
|---|---|---|
| Objetivo | Maximizar una lower bound (ELBO) sobre el log-likelihood. | Juego competitivo: generar datos que el discriminador no pueda distinguir de los reales. |
| Manera de aprender $p(x)$ | Modela explícitamente $p(x)$ como una integral sobre $z$ con inferencia aproximada. | No modela explícitamente $p(x)$; aprende a generar muestras que parecen reales. |
| Función de pérdida | Reconstrucción + regularización KL. | Pérdida adversarial basada en el error del discriminador. |
| Salida típica | Espacio latente ordenado, muestras a veces suaves. | Muestras potencialmente más nítidas, entrenamiento más delicado. |
| Dificultades | Posterior aproximado, compromiso reconstrucción/KL. | Colapso de modos, oscilaciones, sensibilidad a arquitectura. |
VAE: modelo generativo probabilístico explícito.
GAN: modelo generativo implícito aprendido mediante competencia.
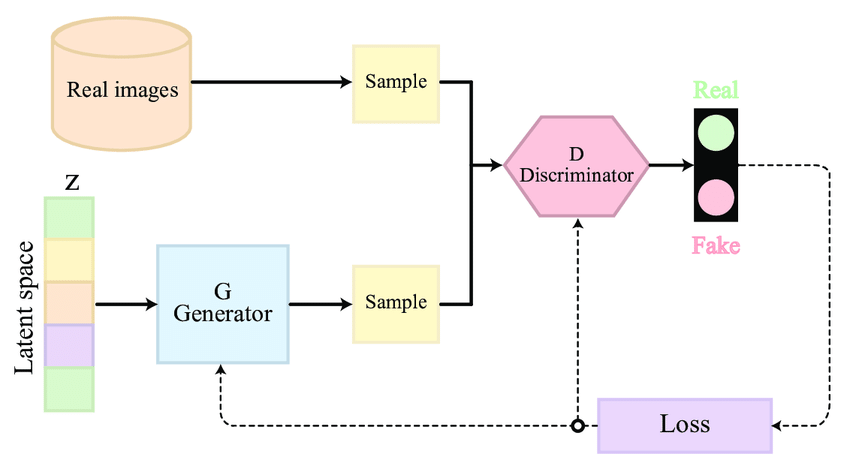
3. Estructura de una GAN¶
Una GAN consta de dos redes neuronales:
| Componente | Qué hace |
|---|---|
| Generador $G(z)$ | Toma un vector aleatorio $z \sim p_z(z)$ y produce una muestra $x' = G(z)$. |
| Discriminador $D(x)$ | Toma una muestra y predice si viene de los datos reales o es generada. $D(x) \in [0,1]$. |
Objetivo:
- $G$ quiere maximizar la probabilidad de que $D$ se equivoque.
- $D$ quiere minimizar esa probabilidad (es decir, clasificar correctamente).
Motivación Intuitiva de GAN¶
En lugar de decirle directamente al modelo cómo debe ser una muestra real...
- Le ponemos un crítico (el discriminador) que aprende a detectar si una muestra es real o falsa.
Entonces el generador:
- Aprende indirectamente a mejorar sus muestras para engañar al crítico.
Metáfora¶
- El Generador produce ejemplos sintéticos que intentan parecer reales.
- El Discriminador es un experto en arte que intenta descubrir las falsificaciones.
- El generador mejora continuamente para producir ejemplos más plausibles, y el discriminador mejora para detectar diferencias entre datos reales y generados.
Resultado: Esta competencia constante fuerza a ambos a perfeccionarse progresivamente, hasta que las falsificaciones sean indistinguibles de las obras reales.
Evolución de GAN desde 2014 a 2019¶

GAN 2021¶
 Ref: https://ieeexplore.ieee.org/document/9445031
Ref: https://ieeexplore.ieee.org/document/9445031
Diagrama de Flujo: Imagen en el Discriminador GAN¶
markdown
╭────────────────────────────────────────────────────────╮
│ Imagen x (Real o Falsa) │ (Ej: tamaño 64x64x3) |
╰────────────────────────────────────────────────────────╯
│
▼
╭────────────────────────────────────────────────────────╮
│ Extracción de Features (CNN) │
│ - Filtros detectan bordes, texturas, formas. │
│ - Varias capas convolucionales y activaciones. │
╰────────────────────────────────────────────────────────╯
│
▼
╭────────────────────────────────────────────────────────╮
│ Aplanado (Flatten) │
│ - Colapsa los mapas de activación a un vector. │
╰────────────────────────────────────────────────────────╯
│
▼
╭────────────────────────────────────────────────────────╮
│ Capa Fully Connected │
│ - Combina los features en una representación global. │
╰────────────────────────────────────────────────────────╯
│
▼
╭────────────────────────────────────────────────────────╮
│ Activación Sigmoid │
│ - Predice Score ∈ [0,1] │
│ - Interpretable como "Probabilidad de ser real". │
╰────────────────────────────────────────────────────────╯
│
▼
╭────────────────────────────────────────────────────────╮
│ Score Final: D(x) │
│ - Cerca de 1: Imagen real. │
│ - Cerca de 0: Imagen falsa. │
╰────────────────────────────────────────────────────────╯Resumen Conceptual¶
- Cada imagen es procesada de forma individual.
- El discriminador extrae features y colapsa esa información en un único número.
- No se compara explícitamente contra otras imágenes.
- La salida $D(x)$ representa la probabilidad de que la imagen sea real según el discriminador.
Tips¶
- Piensa en el discriminador como un experto en detectar falsificaciones, que ha aprendido a identificar detalles finos que estadísticamente ocurren en imágenes reales vs generadas.
- El entrenamiento ajusta esos criterios continuamente mostrando ejemplos.
4. Matemáticamente: Juego de Suma Cero¶
Paso 1: El juego GAN como un problema de minimax¶
Intuición: en un problema minimax, cada jugador asume que el otro responderá de forma óptima y elige su mejor estrategia bajo ese escenario.
Yo asumo que mi oponente jugará de la forma más agresiva posible. Así que busco la estrategia que me garantice el menor daño posible, incluso en ese peor escenario.
La función objetivo que define una GAN es esta:
$$ \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}}[\log D(x)] + \mathbb{E}_{z \sim p_z}[\log(1 - D(G(z)))] $$Esto define un juego de suma cero entre dos redes:
| Jugador | Qué quiere hacer |
|---|---|
| Discriminador $D$ | Maximizar esta función: detectar bien lo real y lo falso. |
| Generador $G$ | Minimizar esta función: generar imágenes que engañen a $D$. |
¿Qué significa cada término?¶
- $\mathbb{E}_{x \sim p_{\text{data}}}[\log D(x)]$: Valor esperado sobre ejemplos reales $x$ muestreados desde $p_{\text{data}}(x)$; mide el logaritmo de la probabilidad que $D$ asigna a las imágenes reales.
- $D(x)$ es la probabilidad de que una imagen $x$ sea real.
- Este término se maximiza cuando $D(x) \to 1$ para imágenes reales.
- Entonces, D quiere aprender a decir “esto es real” con confianza para los datos reales.
- $\mathbb{E}_{z \sim p_z}[\log(1 - D(G(z)))]$: Valor esperado sobre ruidos latentes $z$ muestreados desde $p_z$; mide el logaritmo de la probabilidad de que $D$ clasifique como falsas las imágenes generadas.
- $G(z)$ es una imagen falsa generada a partir de ruido $z$.
- $D(G(z))$ es la probabilidad de que el discriminador crea que esa imagen es real.
- Este término se maximiza cuando $D(G(z)) \to 0$, o sea, cuando $D$ dice "esto es falso".
- Entonces, D también quiere detectar lo falso.
En palabras simples¶
- Discriminador: quiere que $D(x) \to 1$ y $D(G(z)) \to 0$ → maximiza $V(D,G)$
- Generador: quiere que $D(G(z)) \to 1$ → hace que el segundo término disminuya → minimiza $V(D,G)$
Por eso minmax
Conclusión¶
La “función” que uno maximiza y otro minimiza es $V(D,G)$, la función objetivo GAN.
Es la función objetivo que formaliza el aprendizaje adversarial.
Cada paso de entrenamiento GAN actualiza $D$ y $G$ en direcciones opuestas de esta función objetivo.
El rol del Generador¶
El generador busca reducir la capacidad del discriminador para distinguir entre imágenes reales y generadas.
En términos matemáticos:
- $G$ minimiza la función total.
- Pero como $G$ no tiene acceso a $D(x)$ (porque $x$ es real),
- Solo puede actuar sobre el segundo término: $$ \mathbb{E}_{z \sim p_z}[\log(1 - D(G(z)))] $$
- Entonces, $G$ quiere que $D(G(z)) \to 1$, o sea que D crea que las falsas son reales.
Intuición total¶
La GAN es un juego de dos objetivos opuestos: $D$ gana cuando clasifica correctamente ejemplos reales y generados; $G$ gana cuando aumenta $D(G(z))$, es decir, cuando sus muestras son clasificadas como reales.
Paso 2: ¿Cómo se implementa esto en código?¶
Vamos por partes.
Paso 1: Actualizar el discriminador¶
Queremos maximizar:
$$ \log D(x) + \log(1 - D(G(z))) $$Esto es el promedio del log-likelihood correcto para:
- Clasificar $x$ como real (etiqueta 1),
- Clasificar $G(z)$ como falso (etiqueta 0).
En práctica, usamos una función de pérdida como la Binary Cross Entropy (BCE) para esto.
Paso 2: Actualizar el generador¶
Originalmente, se propuso que $G$ minimice:
$$ \log(1 - D(G(z))) $$Pero este objetivo tiene un problema:
- Si $D$ es muy bueno al inicio, entonces $D(G(z)) \approx 0$, lo que hace que: $$ \log(1 - D(G(z))) \approx \log(1) = 0 \quad \text{(plano)} $$
- El gradiente se vuelve casi cero; en ese régimen, $G$ aprende muy poco.
Solución práctica: cambiar la pérdida de $G$¶
Se propone usar en su lugar:
$$ \text{maximizar} \quad \log(D(G(z))) $$Es decir, decirle a $G$:
No intentes minimizar que te detecten como falso,
intenta directamente maximizar que te crean real.
Esto produce gradientes más fuertes y útiles al inicio del entrenamiento.
Comparación de pérdidas para el generador¶
| Formulación para $G$ | Pérdida que se minimiza | Comentario |
|---|---|---|
| Minimax original | $\mathbb{E}_{z \sim p_z}[\log(1 - D(G(z)))]$ | Es la forma del juego teórico, pero puede saturar cuando $D(G(z)) \approx 0$. |
| No saturante (práctica común) | $-\mathbb{E}_{z \sim p_z}[\log D(G(z))]$ | Mantiene gradientes más útiles al inicio porque empuja directamente a que $D(G(z))$ suba. |
Recapitulación¶
- GAN es un juego adversarial: $G$ intenta producir muestras clasificadas como reales y $D$ intenta distinguir reales de generadas.
- La pérdida original es un juego minimax entre los dos.
- En la práctica, se ajusta la pérdida de $G$ para evitar gradientes débiles al comienzo.
¿Con respecto a qué el Discriminador decide si es real o falsa?¶
Conceptualmente:¶
- El discriminador no compara imágenes explícitamente,
- Compara características internas aprendidas contra su experiencia previa de imágenes reales y falsas.
- Aprende patrones estadísticos internos: texturas, formas, bordes, coherencias globales.
¿Cómo aprende eso?
Durante el entrenamiento:
- Se le muestran imágenes reales (con etiqueta 1),
- y imágenes falsas generadas por $G$ (con etiqueta 0).
La pérdida de entrenamiento es:
$$ \mathcal{L}_D = -\left( \mathbb{E}_{x \sim p_{\text{data}}}[\log D(x)] + \mathbb{E}_{z \sim p_z}[\log(1 - D(G(z)))] \right) $$Traducción intuitiva:
- Penalizamos a $D$ si cree que una imagen real es falsa (queremos $D(x) \to 1$ para reales),
- y penalizamos a $D$ si cree que una imagen falsa es real (queremos $D(G(z)) \to 0$ para generadas).
Entonces:¶
- Al principio, el discriminador no sabe nada. Adivina al azar.
- Con el entrenamiento, aprende estadísticamente qué tipos de patrones (texturas, alineaciones, estructuras) son más probables en imágenes reales versus imágenes falsas.
- No necesita una imagen de referencia exacta. Aprende características generales.
Ejemplo Simple¶
Imagínate:
- Imágenes reales de caras humanas tienen ojos simétricos.
- El generador al principio puede generar manchas raras.
- El discriminador aprende que "ojos simétricos" = probablemente real,
- y que "manchas deformadas" = probablemente falso.
Todo esto se aprende a partir de datos observados mediante retropropagación.
Así¶
- Cada imagen pasa sola por el discriminador.
- El discriminador asigna una probabilidad a cada imagen individualmente.
- No compara explícitamente imágenes.
- Aprende características internas que ayudan a decidir si algo parece real o falso, basándose en su experiencia previa.
6. Resultado teórico (hermoso)¶
Si $G$ y $D$ tuvieran capacidad infinita, entonces:
- El $G$ óptimo genera datos $G(z)$ que tienen exactamente la distribución de los datos reales $p_{\text{data}}(x)$.
- El discriminador no puede distinguir (su salida es $D(x) = 0.5$ para todo $x$).
Esto significa que GANs en teoría pueden aprender la distribución real sin conocer explícitamente su fórmula.
Recordemos: ¿Qué queremos hacer en una GAN?¶
Queremos que el generador $G(z)$ aprenda a generar muestras que parezcan salir de la distribución real $p_{\text{data}}(x)$,
sin tener acceso a la función de densidad $p_{\text{data}}$,
ni al gradiente de esa función,
ni siquiera a una fórmula cerrada de cómo se ve.
El resultado teórico: ¿Qué pasaría si G y D fueran infinitamente poderosos?¶
Supongamos que el generador y el discriminador pueden representar cualquier función (son redes neuronales infinitamente grandes con tiempo de entrenamiento infinito).
¿Qué pasa en el equilibrio del juego?
En ese caso, se demuestra que:¶
El generador $G$ aprendería a generar exactamente desde la distribución real: $$ p_g(x) = p_{\text{data}}(x) $$
Y el discriminador óptimo no podría distinguir una muestra real de una generada. Su probabilidad sería: $$ D(x) = 0.5 \quad \forall x $$ Porque no tiene ninguna pista para decidir: ambas vienen de la misma distribución.
¿Por qué esto es tan importante?¶
Porque significa que GANs pueden aproximar $p_{\text{data}}(x)$ sin estimar explícitamente su densidad.
El entrenamiento observa muestras reales y usa la señal del discriminador para que el generador aproxime progresivamente la distribución de datos.
Demostración simple de la idea (intuitiva)¶
En el paper original se muestra que:
El discriminador óptimo para un generador dado $G$ es: $$ D^*(x) = \frac{p_{\text{data}}(x)}{p_{\text{data}}(x) + p_g(x)} $$
Cuando $p_g(x) = p_{\text{data}}(x)$, entonces: $$ D^*(x) = \frac{p_{\text{data}}(x)}{2p_{\text{data}}(x)} = 0.5 $$
Esto significa que en el equilibrio ideal:
- El generador y el real son indistinguibles,
- El discriminador solo puede adivinar.
¿Qué logramos sin usar likelihood explícita?¶
A diferencia de modelos como los VAEs, que maximizan explícitamente una función de log-likelihood,
las GANs no lo hacen.
GANs solo juegan este juego adversarial, y sin tener acceso a la función $p_{\text{data}}$,
logran que el generador implícitamente aprenda a producir muestras de esa distribución.
Esto se llama modelamiento implícito de densidades.
En la práctica…¶
- No tenemos redes infinitas.
- Ni entrenamiento perfecto.
- Ni discriminadores ideales.
Por eso las GANs pueden colapsar modos, oscilar, o no cubrir toda la distribución.
Pero en teoría…¶
Si tuviéramos poder de cómputo y tiempo infinitos,
una GAN sería capaz de aprender perfectamente la distribución real de los datos solo viendo ejemplos,
sin necesidad de fórmula ni likelihood.
Pero, ¿qué pasa con la pérdida (loss) del discriminador?¶
En el equilibrio ideal:
- El generador genera datos que son idénticos en distribución a los reales.
- El discriminador no puede distinguir si una imagen es real o generada.
- Entonces:
$$ D(x) \approx 0.5 \quad \text{para toda } x $$
La pérdida de $D$ es:
$$ \mathcal{L}_D = - \left( \log D(x) + \log(1 - D(G(z))) \right) $$Si $D(x) = 0.5$ y $D(G(z)) = 0.5$, entonces:
$$ \mathcal{L}_D = -(\log 0.5 + \log 0.5) = -2 \log 0.5 = -2(-\log 2) = 2 \log 2 \approx 1.386 $$Conclusión¶
| Valor esperado en equilibrio ideal | Valor aproximado |
|---|---|
| Output de $D$ | $D(x) = 0.5$ |
| Pérdida de $D$ | $\approx 1.386$ |
Entonces:
No interpretes que una loss de $D$ cercana a 0.5 sea necesariamente el objetivo.
Si el entrenamiento va bien, la loss de $D$ suele estabilizarse cerca de 1.3–1.4,
mientras que sus salidas tienden a 0.5 para ambos reales y falsos.
En la práctica¶
- Si la loss de $D$ es muy baja (~0), significa que D está ganando completamente →$G$ no aprende.
- Si es muy alta (>> 1.5), puede estar adivinando o colapsado.
- Lo ideal es observar:
- Que la loss de $D$ no baje demasiado,
- Y que la salida de $D(x)$ tienda a 0.5 cuando $G$ está bien entrenado.
Ahora, ¿qué pasa con la pérdida (loss) del generador?¶
Respuesta corta:
No existe un valor estándar “ideal” para la pérdida del generador (
loss_G) que indique que la GAN está funcionando bien.
En cambio, se evalúa el desempeño por:
1. Tendencia relativa de la pérdida¶
- Queremos ver que
loss_Gdisminuya al principio, luego oscile o se mantenga relativamente estable. - Si se mantiene alta (ej. >5) y no cambia, puede significar que el discriminador es demasiado fuerte y el generador no está aprendiendo.
- Si es demasiado baja (≈ 0) constantemente, puede indicar que el generador está engañando al discriminador sin diversidad (colapso de modos).
2. Equilibrio visual y numérico con loss_D¶
- Un buen entrenamiento suele mostrar:
loss_Den el rango 1.0 – 1.5loss_Gen el rango 1.0 – 4.0 (aproximadamente, dependiendo del dataset y arquitectura)
- Pero lo más importante es que ambas se mantengan activas, es decir, que ninguna se vuelva constante o se colapse.
3. Evaluación cualitativa¶
- La métrica más confiable en la práctica es visual: ¿las imágenes generadas son realistas, diversas y coherentes?
- Algunos trabajos usan métricas como FID (Fréchet Inception Distance) para cuantificar calidad y diversidad. Pero no son parte de la loss.
Conclusión¶
La
loss_Ges útil para monitorear entrenamiento, pero no tiene un valor fijo universal. Su escala depende de la formulación de pérdida, la arquitectura y el balance con el discriminador.
Lo importante es mirar conjuntamente:
- la tendencia de
loss_G,- la tendencia de
loss_D,- las salidas $D(x)$ y $D(G(z))$,
- y, sobre todo, la diversidad/calidad de las muestras generadas.
7. Problemas prácticos de entrenamiento¶
Aunque la teoría es bella, en la práctica:
- Colapso de modos: el generador produce siempre lo mismo.
- Oscilaciones: $G$ y $D$ nunca se estabilizan.
- Gradientes débiles: si $D$ es demasiado bueno,$G$ no recibe gradientes útiles.
- No hay función de likelihood para medir la convergencia como en VAEs.
8. Variantes para mejorar GANs¶
A lo largo de los años, surgieron mejoras como:
- Wasserstein GAN (WGAN): reemplaza la divergencia de Jensen-Shannon por una distancia Wasserstein para mejorar gradientes.
- Least Squares GAN (LSGAN): cambia la función de pérdida para penalizar muestras falsas más suavemente.
- Feature Matching: en lugar de engañar a D en su salida, intentar hacer coincidir características intermedias.
9. Visualización conceptual¶
Ruido z ─▶ Generador G(z) ─▶ Imagen falsa ─▶ Discriminador D(x)
▲ ▼
Imagen real ──────────┘ (Decide: ¿real o falsa?)
Cada mejora de $G$ fuerza a $D$ a mejorar, y viceversa.
Es un proceso de coadaptación: cada mejora de $G$ cambia el problema que debe resolver $D$, y viceversa.
import numpy as np
import matplotlib.pyplot as plt
# Simulación didáctica: acercamiento gradual al equilibrio ideal de una GAN.
# Se calculan las pérdidas desde las salidas del discriminador para evitar
# interpretar curvas arbitrarias que no son compatibles entre sí.
epochs = np.arange(1, 101)
rng = np.random.default_rng(123)
eps = 1e-6
# D empieza separando reales/falsas con confianza y luego se acerca a la duda.
D_real = 0.55 + 0.35 * np.exp(-0.035 * epochs) + rng.normal(0, 0.015, size=len(epochs))
D_fake = 0.45 - 0.35 * np.exp(-0.035 * epochs) + rng.normal(0, 0.015, size=len(epochs))
D_real = np.clip(D_real, eps, 1 - eps)
D_fake = np.clip(D_fake, eps, 1 - eps)
# BCE sumada por batch balanceado: real=1, falsa=0.
loss_D = -(np.log(D_real) + np.log(1 - D_fake))
# Pérdida no saturante del generador: quiere que D(G(z)) sea clasificado como real.
loss_G = -np.log(D_fake)
fig, axs = plt.subplots(2, 1, figsize=(10, 8), sharex=True)
axs[0].plot(epochs, loss_D, label='Loss Discriminador (BCE real + falsa)', color='red')
axs[0].plot(epochs, loss_G, label='Loss Generador no saturante', color='blue')
axs[0].axhline(np.log(4), color='gray', linestyle='--', label=r'Loss D ideal: $2\log 2$')
axs[0].axhline(np.log(2), color='black', linestyle=':', label=r'Loss G no saturante ideal: $\log 2$')
axs[0].set_ylabel('Pérdida')
axs[0].set_title('Pérdidas calculadas desde las probabilidades del discriminador')
axs[0].legend()
axs[0].grid(True, alpha=0.3)
axs[1].plot(epochs, D_real, label='D(x) para muestras reales', color='green')
axs[1].plot(epochs, D_fake, label='D(G(z)) para muestras generadas', color='orange')
axs[1].axhline(0.5, color='gray', linestyle='--', label='Equilibrio ideal: 0.5')
axs[1].set_xlabel('Épocas')
axs[1].set_ylabel('Probabilidad estimada por D')
axs[1].set_title('Salidas del discriminador durante una dinámica estable')
axs[1].legend()
axs[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
Cómo leer estas curvas sin sobreinterpretarlas¶
Esta simulación no pretende decir que una GAN real deba seguir exactamente estos valores. Su objetivo es mostrar una relación que sí debe ser consistente:
Loss Dse calcula desde $D(x)$ y $D(G(z))$.Loss Gse calcula desde $D(G(z))$ usando la pérdida no saturante $-\log D(G(z))$.- En el equilibrio teórico ideal, si $p_g = p_{\text{data}}$, entonces el discriminador óptimo no puede distinguir reales de generadas y devuelve $0.5$.
En ese equilibrio ideal:
$$ \mathcal{L}_D = -[\log(0.5) + \log(1 - 0.5)] = 2\log 2 \approx 1.386 $$Si usamos la pérdida no saturante para el generador:
$$ \mathcal{L}_G = -\log D(G(z)) = -\log(0.5) = \log 2 \approx 0.693 $$Señales prácticas de entrenamiento¶
| Señal | Lectura típica |
|---|---|
Loss D muy baja y Loss G muy alta |
El discriminador separa demasiado bien; el generador puede recibir señal débil. |
Loss D cerca de $2\log 2$ y salidas de D cerca de 0.5 |
Compatible con equilibrio, aunque también puede indicar un discriminador incapaz si las muestras son malas. |
Loss G baja con poca diversidad visual |
Posible colapso de modos: no basta mirar la pérdida. |
| Muestras diversas y mejora visual con pérdidas activas | Evidencia más razonable de entrenamiento útil. |
Punto clave¶
En GANs no hay un número mágico de loss que certifique éxito. La evaluación combina pérdidas, salidas del discriminador y revisión cualitativa o métricas externas como FID/KID.
Aspectos profundos de GANs¶
1. Diferencias fundamentales entre VAE y GAN¶
En esta clase vimos que tanto los VAEs como las GANs buscan generar datos realistas.
Sin embargo, su filosofía es muy distinta:
VAE: intenta aproximar directamente la distribución de datos $p(x)$.
- Maximiza una cota inferior (ELBO) del log-likelihood.
- Hay una función explícita que modela la probabilidad de cada dato.
GAN: intenta simular $p(x)$ sin modelarla explícitamente.
- No tiene una fórmula para $p(x)$.
- Aprende a producir datos que se parecen a los reales, sin calcular probabilidades.
Conclusión:
VAE ≈ "Modela la distribución explícitamente".
GAN ≈ "Aprende a generar datos realistas sin modelar la distribución".
2. ¿Qué significa no tener likelihood explícito?¶
En un VAE (o en cualquier modelo probabilístico tradicional), podemos calcular:
$$ \log p(x) \quad \text{(o al menos una cota)} $$Esto nos permite:
- Comparar modelos numéricamente,
- Medir cuánto mejoran,
- Hacer validaciones estadísticas estándar.
En una GAN, como no tenemos $p(x)$, no podemos calcular likelihood.
Por lo tanto:
- No hay una métrica simple para saber cuándo el entrenamiento va bien.
- Tenemos que basarnos en la calidad visual de las muestras o métricas indirectas.
Evaluar GANs es mucho más difícil que evaluar VAEs.
3. ¿Por qué colapsan modos en GANs?¶
Uno de los grandes problemas prácticos en GANs es el colapso de modos.
¿Qué pasa?
- El generador $G$ descubre que hay algunas muestras que engañan muy bien al discriminador $D$.
- Entonces empieza a generar siempre las mismas pocas muestras.
- Se pierde la diversidad de la distribución real.
Ejemplo:
- Si $p_{\text{data}}$ son fotos de perros de distintas razas,
- un generador colapsado puede aprender a generar solo bulldogs porque son fáciles de falsificar.
Intuición:
$G$ engaña a $D$ en un atajo, en lugar de aprender toda la diversidad de $p(x)$.
4. ¿Cómo se busca solucionar estos problemas?¶
Para mejorar la estabilidad de GANs, surgieron ideas como:
Wasserstein GAN (WGAN):
- Cambia la métrica: en vez de usar la divergencia de Jensen-Shannon, usa la distancia de Wasserstein (o "Earth Mover Distance").
- Esto genera gradientes más estables para entrenar $G$.
- Hace que aunque $D$ sea muy bueno, $G$ siga recibiendo gradientes útiles.
Feature Matching:
- Propuesto como alternativa en GANs para evitar el colapso de modos.
- En vez de solo "engañar a D" en su salida final,
- El generador intenta igualar características internas del discriminador para ser más diverso.
5. Visualización real: Ejemplos de GANs¶
En la práctica:
- Las GANs bien entrenadas pueden generar imágenes extraordinariamente realistas.
- Ejemplos conocidos incluyen:
- Caras de personas que no existen (como las de ThisPersonDoesNotExist.com https://this-person-does-not-exist.com/en),
- Imágenes de alta resolución (proyectos como StyleGAN).
- Código en GitHub: https://github.com/NVlabs/stylegan
Al mostrar ejemplos:
- En imágenes, muchas GANs modernas pueden superar a VAEs clásicos en nitidez y detalle visual.
- Pero también vemos cómo GANs pueden fallar si no están bien entrenadas: artefactos, falta de diversidad, repeticiones.
Recapitulando¶
- VAE aprende $p(x)$ explícitamente, GAN lo simula indirectamente.
- GAN no tiene likelihood: evaluar progreso es más desafiante.
- El colapso de modos es un problema común cuando el generador explota un atajo que engaña al discriminador sin cubrir toda la diversidad de los datos.
- Mejoras como WGAN y Feature Matching fueron propuestas para hacer que GANs sean más estables y diversos.
- GANs bien entrenadas logran resultados visualmente impresionantes.
# === 1. Librerías necesarias ===
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torchvision
from pathlib import Path
# === 2. Parámetros principales ===
batch_size = 128
latent_dim = 100 # Dimensión del ruido de entrada al generador
image_size = 28*28 # Tamaño de las imágenes aplanadas (MNIST) #784
device = torch.device('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu')
DATA_DIR = Path("data")
if not (DATA_DIR / "MNIST").exists():
DATA_DIR = Path("runs/2026-1-Pregrado/overrides/labs/Modulo 4 Modelos Generativos/data")
# === 3. Cargar MNIST ===
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]) # Escala a [-1, 1]
])
dataloader = DataLoader(
datasets.MNIST(root=str(DATA_DIR), train=True, transform=transform, download=True),
batch_size=batch_size,
shuffle=True
)
# === 4. Definir el Generador ===
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.ReLU(True),
nn.Linear(512, image_size),
nn.Tanh() # Salida entre [-1, 1]
)
def forward(self, z):
return self.model(z)
# === 5. Definir el Discriminador ===
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(image_size, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid() # Probabilidad entre 0 y 1
)
def forward(self, x):
return self.model(x)
# === 6. Inicializar modelos ===
G = Generator().to(device)
D = Discriminator().to(device)
# === 7. Función de pérdida y optimizadores ===
criterion = nn.BCELoss()
optimizer_G = optim.Adam(G.parameters(), lr=0.0002)
optimizer_D = optim.Adam(D.parameters(), lr=0.0002)
# === 8. Entrenamiento GAN ===
num_epochs = 3 # Demo rápida; sube a 30-50 para mejores muestras
for epoch in range(num_epochs):
for real_imgs, _ in dataloader:
# =======================
# Paso 1: Preparar datos
# =======================
real_imgs = real_imgs.view(-1, image_size).to(device) # Aplanar imágenes reales
batch_size = real_imgs.size(0)
# Etiquetas: 1 para reales, 0 para falsas
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# ===============================
# Paso 2: Entrenar Discriminador
# ===============================
# a) Imagen real
outputs_real = D(real_imgs)
d_loss_real = criterion(outputs_real, real_labels)
# b) Imagen falsa
z = torch.randn(batch_size, latent_dim).to(device) # Ruido aleatorio
fake_imgs = G(z)
outputs_fake = D(fake_imgs.detach()) # ¡No actualizamos G aquí!
d_loss_fake = criterion(outputs_fake, fake_labels)
# c) Backpropagation para D
d_loss = d_loss_real + d_loss_fake
optimizer_D.zero_grad()
d_loss.backward()
optimizer_D.step()
# ===========================
# Paso 3: Entrenar Generador
# ===========================
z = torch.randn(batch_size, latent_dim).to(device)
fake_imgs = G(z)
outputs = D(fake_imgs)
# Queremos que D piense que las falsas son reales → etiquetas = 1
g_loss = criterion(outputs, real_labels)
optimizer_G.zero_grad()
g_loss.backward()
optimizer_G.step()
# ======================
# Paso 4: Mostrar progreso
# ======================
print(f"Epoch [{epoch+1}/{num_epochs}] Loss D: {d_loss.item():.4f}, Loss G: {g_loss.item():.4f}")
import matplotlib.pyplot as plt
# Generar un batch de imágenes
z = torch.randn(64, latent_dim).to(device)
fake_imgs = G(z)
fake_imgs = fake_imgs.view(-1, 1, 28, 28).cpu().detach()
# Mostrar algunas
grid_img = torchvision.utils.make_grid(fake_imgs, nrow=8, normalize=True)
plt.figure(figsize=(8,8))
plt.imshow(grid_img.permute(1, 2, 0))
plt.axis('off')
plt.show()
# ========================================
# 1. LIBRERÍAS NECESARIAS
# ========================================
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from pathlib import Path
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# ========================================
# 2. HIPERPARÁMETROS PRINCIPALES
# ========================================
latent_dim = 100 # Tamaño del vector de entrada aleatorio z
image_size = 28 * 28 # Tamaño de las imágenes (MNIST 28x28 aplanado)
batch_size = 128
num_epochs = 5 # Demo rápida; sube a 30-50 para una versión de clase completa
device = torch.device("cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
DATA_DIR = Path("data")
if not (DATA_DIR / "MNIST").exists():
DATA_DIR = Path("runs/2026-1-Pregrado/overrides/labs/Modulo 4 Modelos Generativos/data")
# ========================================
# 3. TRANSFORMACIONES Y CARGA DE DATOS
# ========================================
# Convertimos las imágenes a tensores y las normalizamos a [-1, 1]
# Esto es necesario ya que mas abajo usamos tanh que va entre [-1 y 1], mientras que la data va entre [0 y 1]
# por lo tanto el discriminador recibe dominios diferentes
# haciendo que sea muy facil aprender que es real vs falso aunque las imagenes sean visualmente parecidas.
# Abajo aplicamos x'=(x-0.5)/0,5 =2x-1; que va de [-1,1] igual que la salida de tanh.
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
# Dataset MNIST cargado con DataLoader
dataloader = DataLoader(
datasets.MNIST(root=str(DATA_DIR), train=True, download=True, transform=transform),
batch_size=batch_size,
shuffle=True
)
# ========================================
# 4. DEFINICIÓN DEL GENERADOR MEJORADO
# ========================================
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.BatchNorm1d(256), # Normaliza activaciones (acelera convergencia)
nn.LeakyReLU(0.2, inplace=True), # Evita zonas muertas
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, image_size),
nn.Tanh() # Output entre [-1, 1] para que coincida con imágenes normalizadas
)
def forward(self, z):
return self.model(z)
# ========================================
# 5. DEFINICIÓN DEL DISCRIMINADOR MEJORADO
# ========================================
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(image_size, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3), # Regularización
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid() # Salida ∈ (0,1): probabilidad de que sea real
)
def forward(self, x):
return self.model(x)
# ========================================
# 6. INSTANCIAR MODELOS, OPTIMIZADORES Y PÉRDIDA
# ========================================
G = Generator().to(device)
D = Discriminator().to(device)
criterion = nn.BCELoss() # Binary Cross Entropy: para clasificación real/falso
optimizer_G = optim.Adam(G.parameters(), lr=0.0002)
optimizer_D = optim.Adam(D.parameters(), lr=0.0002)
# # ========================================
# # 7. FUNCIÓN PARA VISUALIZAR RESULTADOS GENERADOS
# # ========================================
# def show_fake_images(generator, nrow=8):
# generator.eval() # Pone la red en modo evaluación
# z = torch.randn(nrow**2, latent_dim).to(device) # Vector aleatorio z
# with torch.no_grad():
# fake_imgs = generator(z).view(-1, 1, 28, 28) # Reconstruimos la imagen generada
# fake_imgs = fake_imgs.cpu()
# grid = torchvision.utils.make_grid(fake_imgs, nrow=nrow, normalize=True)
# plt.figure(figsize=(6,6))
# plt.imshow(grid.permute(1, 2, 0))
# plt.axis("off")
# plt.show()
# generator.train() # Volver a modo entrenamiento
# ====================================================
# Crear un vector fijo z para visualizar el progreso
# ====================================================
torch.manual_seed(42) # Para reproducibilidad (CPU)
torch.cuda.manual_seed_all(42) # Para reproducibilidad (GPU, si aplica)
z_fixed = torch.randn(64, latent_dim).to(device)
# Este vector se usará cada 10 epochs para generar SIEMPRE las mismas imágenes.
# Así podemos ver cómo mejora su calidad durante el entrenamiento.
# ====================================================
# Función de visualización usando z_fixed
# ====================================================
def show_fake_images_fixed(generator, z=z_fixed, nrow=8):
generator.eval() # Cambia a modo evaluación: sin dropout, sin batchnorm acumulado
with torch.no_grad(): # No guarda gradientes → no afecta entrenamiento
fake_imgs = generator(z).view(-1, 1, 28, 28) # Reconstruye forma 28x28
fake_imgs = fake_imgs.cpu() # Pasamos a CPU para graficar
grid = torchvision.utils.make_grid(fake_imgs, nrow=nrow, normalize=True) # Arma grilla
plt.figure(figsize=(6,6))
plt.imshow(grid.permute(1, 2, 0)) # Convierte de CHW (chanel height width) a HWC para matplotlib
plt.axis("off")
plt.title("Muestras generadas (z fijo)")
plt.show()
generator.train() # Vuelve a modo entrenamiento
# ========================================
# 8. ENTRENAMIENTO DE LA GAN
# ========================================
for epoch in range(1, num_epochs + 1):
for real_imgs, _ in dataloader:
real_imgs = real_imgs.view(-1, image_size).to(device) # Aplana y pasa a GPU
batch_size = real_imgs.size(0)
# === Etiquetas ===
real_labels = torch.ones(batch_size, 1).to(device) # Etiquetas para imágenes reales
fake_labels = torch.zeros(batch_size, 1).to(device) # Etiquetas para imágenes falsas
# === ENTRENAR DISCRIMINADOR ===
# 1. Discriminador con imágenes reales
outputs_real = D(real_imgs)
d_loss_real = criterion(outputs_real, real_labels)
# 2. Discriminador con imágenes falsas (sin actualizar G)
z = torch.randn(batch_size, latent_dim).to(device) # Muestras aleatorias
fake_imgs = G(z)
outputs_fake = D(fake_imgs.detach()) # .detach() para que no retropropague en G
d_loss_fake = criterion(outputs_fake, fake_labels)
# 3. Backpropagation para D
d_loss = d_loss_real + d_loss_fake
optimizer_D.zero_grad()
d_loss.backward()
optimizer_D.step()
# === ENTRENAR GENERADOR ===
# El generador intenta engañar al discriminador
z = torch.randn(batch_size, latent_dim).to(device)
fake_imgs = G(z)
outputs = D(fake_imgs)
g_loss = criterion(outputs, real_labels) # ¡Queremos que D diga que son reales!
optimizer_G.zero_grad()
g_loss.backward()
optimizer_G.step()
# === Mostrar progreso numérico ===
print(f"Epoch [{epoch}/{num_epochs}] Loss D: {d_loss.item():.4f}, Loss G: {g_loss.item():.4f}")
# === Visualización cada 10 épocas o al inicio ===
if epoch % 10 == 0 or epoch == 1:
show_fake_images_fixed(G)
Evaluación de una GAN entrenada¶
Después de ejecutar el entrenamiento, no conviene evaluar la GAN solo con el último valor de la pérdida. En una GAN, las pérdidas describen la competencia entre dos modelos, no una métrica directa de calidad como en clasificación supervisada.
Evaluación numérica¶
| Qué revisar | Interpretación cuidadosa |
|---|---|
Loss D |
Si cae cerca de 0, D domina; si se vuelve muy errática, puede haber inestabilidad. |
Loss G |
Si crece sin control, G no engaña a D; si cae demasiado con muestras repetidas, puede haber colapso. |
| $D(x)$ y $D(G(z))$ | En equilibrio ideal ambos tienden a 0.5, pero durante entrenamiento activo D suele separar parcialmente. |
| Evolución por época | Importa más la trayectoria que una lectura aislada. |
Evaluación visual con z fijo¶
Usar el mismo z_fixed en distintas épocas permite comparar si el generador mejora sobre los mismos puntos del espacio latente.
- Diversidad: aparecen distintos tipos de dígitos, no solo una forma repetida.
- Claridad: los trazos se vuelven progresivamente más legibles.
- Cohesión: las muestras tienen estructura espacial, no solo ruido disperso.
- Estabilidad: no hay saltos bruscos donde la calidad colapsa después de mejorar.
Diagnóstico recomendado¶
| Criterio | Qué buscar |
|---|---|
| Estabilidad de pérdidas | Oscilación acotada, sin explosiones persistentes. |
| Balance G-D | Ningún jugador domina durante todo el entrenamiento. |
| Diversidad visual | Varias clases/modos representados. |
| Calidad visual | Muestras plausibles para el dataset usado. |
| Colapso de modos | Ausencia de repeticiones sistemáticas. |
Para una evaluación cuantitativa más formal en imágenes se usan métricas como FID o KID, pero para MNIST en una clase introductoria la combinación de curvas + grillas generadas suele ser suficiente.
Rúbrica de Evaluación de GANs¶
| Dimensión | Nivel Bajo ❌ | Nivel Medio ⚠️ | Nivel Alto ✅ |
|---|---|---|---|
1. Estabilidad de pérdidas (Loss D, Loss G) |
Oscilan fuertemente o explotan/cuelgan | Fluctúan, pero sin colapsar | Oscilan en rangos razonables para la formulación usada |
| 2. Balance G ↔ D | D o G domina completamente | Un jugador tiene ventaja constante | Ambos se adaptan mutuamente |
| 3. Diversidad de muestras | Muchos dígitos repetidos (colapso de modos) | 2–3 dígitos dominan el batch | Amplia variedad de clases generadas |
| 4. Claridad visual | Trazos deformes, ilegibles | Algunos dígitos ruidosos o poco definidos | Dígitos nítidos, legibles y coherentes |
| 5. Evolución con z fijo | No mejora entre épocas | Mejora parcial o inconsistente | Mejora progresiva visible |
| 6. Cohesión espacial (opcional para GANs convolucionales) | Fragmentación de píxeles o trazos disconexos | Algunos bordes ruidosos o zonas vacías | Bordes limpios, trazos conectados |
| 7. Ausencia de colapso | Colapso total: genera siempre lo mismo | Colapso parcial: repite 2–3 muestras | Genera variedad sostenida |
Criterios de Aprobación y Retroalimentación¶
Un modelo GAN es funcional cuando:
- Tiene pérdidas estables,
- No colapsa,
- Y genera muestras visualmente diversas y aceptables.
Un modelo GAN es avanzado cuando:
- Tiene equilibrio competitivo G/D,
- Produce imágenes limpias y variadas,
- Mejora visiblemente a lo largo del entrenamiento.
Ejemplo de Retroalimentación Formativa¶
“Tu GAN muestra pérdidas estables y genera buena diversidad de dígitos. Sin embargo, algunos trazos aún son ruidosos o deformes. Puedes mejorar la claridad usando capas convolucionales (DCGAN) o ajustando el balance G/D para evitar que el discriminador domine por completo.”
Mejora para imágenes: DCGAN (Deep Convolutional GAN)¶
La diferencia entre un GAN (Generative Adversarial Network) y un DCGAN (Deep Convolutional GAN) es principalmente arquitectónica: un DCGAN es una versión especializada de un GAN que utiliza redes neuronales convolucionales profundas para mejorar la generación de imágenes. Aquí te explico punto por punto:
1. GAN (General)¶
- Concepto base: Propuesto por Goodfellow et al. en 2014.
- Componentes:
- Generador (G): Aprende a producir datos falsos que parezcan reales.
- Discriminador (D): Aprende a distinguir entre datos reales y falsos.
- Tipo de red: Originalmente MLPs (perceptrones multicapa).
- Aplicaciones: Genéricas, desde imágenes hasta texto o audio.
2. DCGAN (Deep Convolutional GAN)¶
- Introducido por: Radford et al. (2015) como una implementación más robusta y estable de GANs para imágenes.
- Modificaciones clave:
- Sustituye las capas densas por capas convolucionales y transpuestas (deconvoluciones).
- Usa Batch Normalization para estabilizar el entrenamiento.
- Emplea funciones de activación específicas:
- ReLU en el generador (excepto salida:
tanh). - LeakyReLU en el discriminador.
- ReLU en el generador (excepto salida:
- Mejor rendimiento para generar imágenes visualmente realistas.
Comparación rápida¶
| Característica | GAN clásico | DCGAN |
|---|---|---|
| Arquitectura | MLP | Convolucional profunda |
| Dominio | Genérico | Imagen principalmente |
| Estabilidad | Baja | Mejor |
| Detalle visual | Limitado | Mucho mejor (detalles y texturas) |
| Facilidad de entrenamiento | Difícil | Más fácil con buenas prácticas |
Ejemplo de arquitectura¶
Generador DCGAN típico:
Input (z) → Dense → Reshape → ConvTranspose → BatchNorm → ReLU → ... → tanhDiscriminador DCGAN típico:
Input (image) → Conv → LeakyReLU → BatchNorm → ... → SigmoidConclusión¶
Todo DCGAN es un GAN, pero no todo GAN es un DCGAN.
DCGAN es una instanciación especializada de GANs adaptada para generar imágenes con mayor fidelidad y estabilidad. Si trabajas con imágenes, DCGAN suele ser el punto de partida recomendado.
# ================================
# IMPORTS
# ================================
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, utils
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from pathlib import Path
# ================================
# PARÁMETROS
# ================================
batch_size = 128 # Tamaño del batch para entrenamiento
latent_dim = 100 # Dimensión del espacio latente z
image_size = 28 # Tamaño de las imágenes MNIST
epochs = 5 # Demo rápida; sube a 50-100 para mejores muestras # Número de épocas
device = torch.device("cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu") # Usa GPU si está disponible
DATA_DIR = Path("data")
if not (DATA_DIR / "MNIST").exists():
DATA_DIR = Path("runs/2026-1-Pregrado/overrides/labs/Modulo 4 Modelos Generativos/data")
# ================================
# TRANSFORMACIÓN DE DATOS
# ================================
transform = transforms.Compose([
transforms.Resize(image_size), # Asegura tamaño 28x28
transforms.ToTensor(), # Convierte a tensor con valores en [0,1]
transforms.Normalize([0.5], [0.5]) # Escala a [-1,1] para que coincida con Tanh
])
# Dataset MNIST
dataloader = DataLoader(
datasets.MNIST(root=str(DATA_DIR), train=True, download=True, transform=transform),
batch_size=batch_size,
shuffle=True
)
# ================================
# GENERADOR CONVOLUTIONAL (DCGAN)
# ================================
class DCGANGenerator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.ConvTranspose2d(latent_dim, 128, 7, 1, 0, bias=False), # (batch, 128, 7, 7)
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False), # (batch, 64, 14, 14)
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 1, 4, 2, 1, bias=False), # (batch, 1, 28, 28)
nn.Tanh() # Salida ∈ [-1, 1]
)
def forward(self, z):
return self.model(z)
# ================================
# DISCRIMINADOR CONVOLUTIONAL
# ================================
class DCGANDiscriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(1, 64, 4, 2, 1, bias=False), # (batch, 64, 14, 14)
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, 2, 1, bias=False), # (batch, 128, 7, 7)
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Flatten(),
nn.Linear(128 * 7 * 7, 1),
nn.Sigmoid() # Probabilidad de que sea real
)
def forward(self, x):
return self.model(x)
# ================================
# INICIALIZACIÓN DE MODELOS Y OPTIMIZADORES
# ================================
G = DCGANGenerator().to(device)
D = DCGANDiscriminator().to(device)
criterion = nn.BCELoss() # Binary Cross-Entropy Loss
optimizer_G = optim.Adam(G.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(D.parameters(), lr=0.0002, betas=(0.5, 0.999))
# ================================
# VECTOR Z FIJO PARA VISUALIZACIÓN
# ================================
torch.manual_seed(42)
torch.cuda.manual_seed_all(42)
z_fixed = torch.randn(64, latent_dim, 1, 1).to(device) # vector z fijo 4D para DCGAN
# ================================
# FUNCIÓN DE VISUALIZACIÓN
# ================================
def show_fake_images_fixed(generator, epoch=None, z=z_fixed, nrow=8):
generator.eval() # Desactiva dropout/batchnorm acumulativo
with torch.no_grad():
fake_imgs = generator(z).detach().cpu()
grid = utils.make_grid(fake_imgs, nrow=nrow, normalize=True)
plt.figure(figsize=(6, 6))
plt.imshow(grid.permute(1, 2, 0)) # Convierte de CHW a HWC
plt.axis("off")
title = f"Muestras generadas (z fijo)" if epoch is None else f"Epoch {epoch} - z fijo"
plt.title(title)
plt.show()
generator.train()
# ================================
# ENTRENAMIENTO DE LA GAN
# ================================
for epoch in range(1, epochs + 1):
for real_imgs, _ in dataloader:
real_imgs = real_imgs.to(device)
batch_size = real_imgs.size(0)
# === LABEL SMOOTHING (real=0.9) ===
real_labels = torch.full((batch_size, 1), 0.9, device=device)
fake_labels = torch.zeros(batch_size, 1, device=device)
# === ENTRENAR DISCRIMINADOR ===
output_real = D(real_imgs)
loss_real = criterion(output_real, real_labels)
z = torch.randn(batch_size, latent_dim, 1, 1, device=device)
fake_imgs = G(z)
output_fake = D(fake_imgs.detach())
loss_fake = criterion(output_fake, fake_labels)
loss_D = loss_real + loss_fake
optimizer_D.zero_grad()
loss_D.backward()
optimizer_D.step()
# === ENTRENAR GENERADOR ===
z = torch.randn(batch_size, latent_dim, 1, 1, device=device)
fake_imgs = G(z)
output = D(fake_imgs)
loss_G = criterion(output, real_labels) # El generador quiere que sus muestras parezcan reales (0.9)
optimizer_G.zero_grad()
loss_G.backward()
optimizer_G.step()
# === MOSTRAR RESULTADOS CADA 10 ÉPOCAS (z fijo) ===
print(f"Epoch [{epoch}/{epochs}] Loss D: {loss_D.item():.4f}, Loss G: {loss_G.item():.4f}")
if epoch % 10 == 0 or epoch == 1:
show_fake_images_fixed(G, epoch)